TinyBert: 蒸馏集大成者!!

大家好,我是DASOU,今天说一下 TinyBert;
TinyBert[1] 主要掌握两个核心点:
-
提出了对基于 transformer 的模型的蒸馏方式:Transformer distillation;
-
提出了两阶段学习框架:在预训练和具体任务微调阶段都进行了 Transformer distillation(两阶段有略微不同);
下面对这两个核心点进行阐述。
1. Transformer distillation
1.1整体架构
整体架构如下:
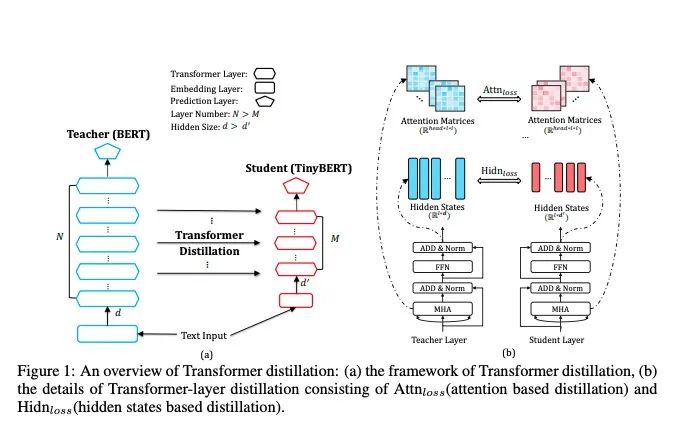
Bert不严谨的来划分,可以分为三个部分:词向量输入层,中间的TRM层,尾端的预测输出层。
在这个论文里,作者把词向量输入层 和中间的TRM层统一称之为中间层,大家读的时候需要注意哈。
Bert的不同层代表了学习到了不同的知识,所以针对不同的层,设定不同的损失函数,让学生网络向老师网络靠近,如下:
-
ebedding层的输出 -
多头注意力层的注意力矩阵和隐层的输出 -
预测层的输出
1.2 Transformer 基础知识:
注意力层:
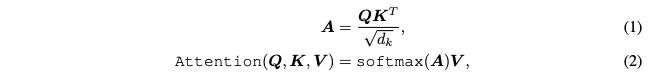
多头注意力层:

前馈神经网路:
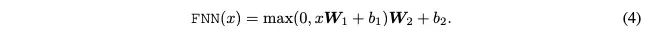
1.3 Transformer 的蒸馏
对 Transformer的蒸馏分为两个部分:一个是注意力层矩阵的蒸馏,一个是前馈神经网络输出的蒸馏。
注意力层矩阵蒸馏的损失函数:
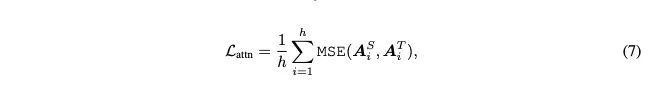
这里注意两个细节点:
一个是使用的是MSE;
还有一个是,使用的没有归一化的注意力矩阵,见(1),而不是softmax之后的。原因是实验证明这样能够更快的收敛而且效果会更好。
前馈神经网络蒸馏的损失函数
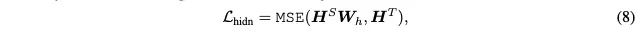
两个细节点:
第一仍然使用的是MSE.
第二个细节点是注意,学生网路的隐层输出乘以了一个权重矩阵 ,这样的原因是学生网络的隐层维度和老师网络的隐层维度不一定相同。
所以如果直接计算MSE是不行的,这个权重矩阵也是在训练过程中学习的。
写到这里提一点,其实这里也可以看出来为什么tinybert的初始化没有采用类似PKD这种,而是使用GD过程进行蒸馏学习。
因为我们的tinybert 在减少层数的同时也减少了宽度(隐层的输出维度),如果采用PKD这种形式,学生网络的维度和老师网络的维度对不上,是不能初始化的。
词向量输入层的蒸馏:
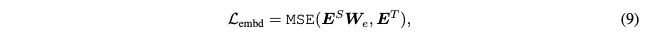
预测层输出蒸馏:
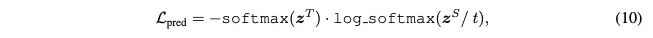
1.4 总体蒸馏损失函数
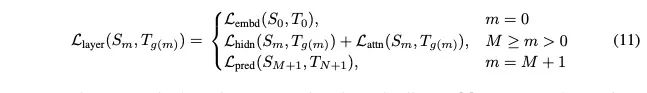
2. 两阶段蒸馏
2.1 整体架构
整体架构如图:
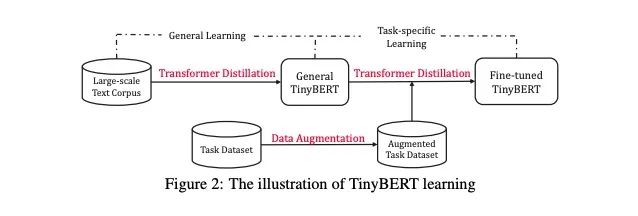
2.2 为什么需要GD:
说一下我自己的理解哈,我觉得有两个原因:
首先,就是上文说到的,tinybert不仅降低了层数,也降低了维度,所以学生网络和老师网络的维度是不符的,所以PKD这种初始化方式不太行。
其次,一般来说,比如PKD,学生网络会使用老师网络的部分层进行初始化。这个从直觉上来说,就不太对。
老师网络12层,学到的是文本的全部信息。学生网络是6层,如果使用老师的12层的前6层进行初始化,这个操作相当于认为这前6层代表了文本的全部信息。
当然,对于学生网络,还会在具体任务上微调。这里只是说这个初始化方式不太严谨。
Tiny bert的初始化方式很有意思,也是用了蒸馏的方式。
老师网络是没有经过在具体任务进行过微调的Bert网络,然后在大规模无监督数据集上,进行Transformer distillation。当然这里的蒸馏就没有预测输出层的蒸馏,翻看附录,发现这里只是中间层的蒸馏。
简单总结一下,这个阶段,使用一个预训练好的Bert( 尚未微调)进行了3epochs的 distillation;
2.3 TD:
TD就是针对具体任务进行蒸馏。
核心点:先进行中间层(包含embedding层)的蒸馏,再去做输出层的蒸馏。
老师网络是一个微调好的Bert,学生网络使用GD之后的tinybert,对老师网络进行TD蒸馏。
TD过程是,先在数据增强之后的数据上进行中间层的蒸馏-10eopchs,learning rate 5e-5;然后预测层的蒸馏3epochs,learning rate 3e-5.
3. 数据增强
在具体任务数据上进行微调的时候,进行了数据增强。
(感觉怪怪的)
两个细节点:
-
对于 single-piece word 通过Bert找到当前mask词最相近的M个单词;对于 multiple sub-word pieces 使用Glove和Consine找到最相近的M个词
-
通过概率P来决定是否替换当前的词为替换词。
-
对任务数据集中的所有文本数据做上述操作,持续N次。
伪代码如下:

4. 实验效果
其实我最关心的一个点就是,数据增强起到了多大的作用。
作者确实也做了实验,如下,数据增强作用还是很大的:
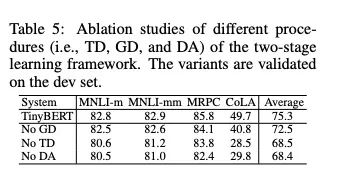
我比较想知道的是,在和PKD同等模型架构下,两者的比较,很遗憾,作者好像并没有做类似的实验(或者我没发现)。
这里的tinybert参数如下:
the number of layers M=4, the hidden size d 0=312, the feedforward/filter size d 0 i=1200 and the head number h=12.
5. 简单总结
先说一下,我读完论文学到的东西:
首先是transformer层蒸馏是如何涉及到的损失函数:
-
注意力矩阵和前馈神经层使用mse; -
蒸馏的时候注意力矩阵使用未归一化 -
维度不同使用权重矩阵进行转化
其次,维度不同导致不能从老师Bert初始化。GD过程为了解决这个问题,直接使用学生网络的架构从老师网络蒸馏一个就可以,这里并不是重新学一个学生网络。
还有就是数据增强,感觉tinyebert的数据增强还是比较简陋的,也比较牵强,而且是针对英文的方法。
TD过程,对不同的层的蒸馏是分开进行的,先进行的中间层的蒸馏,然后是进行的输出层的蒸馏,输出层使用的是Soft没有使用hard。
这个分过程蒸馏很有意思,之前没注意到这个细节点。在腾讯的文章中看到这样一句话:
并且实验中,softmax cross-entropy loss 容易发生不收敛的情况,把 softmax 交叉熵改成 MSE, 收敛效果变好,但泛化效果变差。这是因为使用 softmax cross-entropy 需要学到整个概率分布,更难收敛,因为拟合了 teacher BERT 的概率分布,有更强的泛化性。MSE 对极值敏感,收敛的更快,但泛化效果不如前者。
是有道理的,积累一下这个知识点。
参考资料
TINYBERT: DISTILLING BERT FOR NATURAL LANGUAGE UNDERSTANDING: https://openreview.net/pdf?id=rJx0Q6EFPB
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



