且回忆且学习:在更少的遗忘下精调深层预训练语言模型 | EMNLP 2020
通过精调预训练深层语言模型,很多NLP任务都取得了巨大的提升。然而,这样的顺序迁移学习通常会遇到灾难性遗忘问题。
为此,本文介绍一篇收录于EMNLP 2020的论文。在这篇论文当中作者提出了且回忆且学习的机制,通过采用多任务学习同时学习预训练任务和目标任务。
作者提出了预训练模拟机制在没有预训练数据时回忆预训练的知识,以及目标迁移机制将学习目标逐步迁移至目标任务上。
实验表明作者在GLUE上达到了的最优性能。
作者还将提出的机制集成到Adam优化器中,提供了开源的RecAdam优化器
(https://github.com/Sanyuan-Chen/RecAdam)。

论文名称:《Recall and Learn: Fine-tuning Deep Pretrained Language Models with Less Forgetting》
论文作者:陈三元,侯宇泰,崔一鸣,车万翔,刘挺,余翔湛
原创作者:陈三元
论文链接:https://arxiv.org/abs/2004.12651
背景
1.1 顺序迁移学习
多任务学习(Multi-task Learning)同时学习多个任务,并通过在这些任务之间共享知识来提高模型在所有任务上的性能[4, 5]。通过多任务学习的方式,我们使用以下损失函数同时在源任务和目标任务上训练模型:
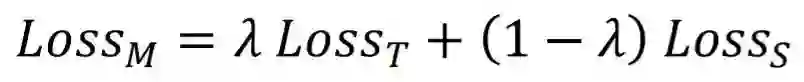
-
我们在适应阶段无法访问预训练数据来计算 。 -
适应阶段的优化目标是 ,而多任务学习旨在优化 ,即 和 的加权和。
方法
2.1 预训练模拟机制
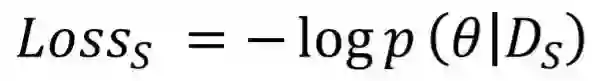
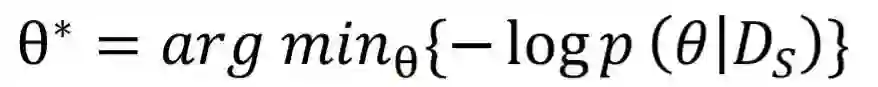
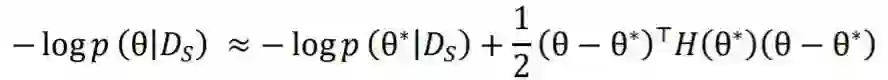
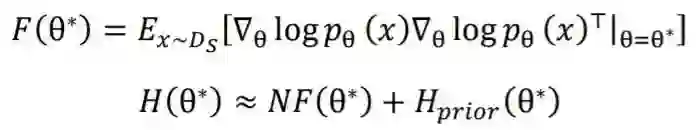
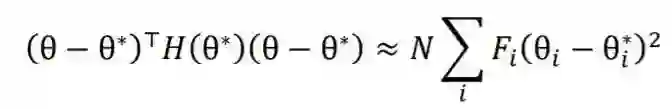
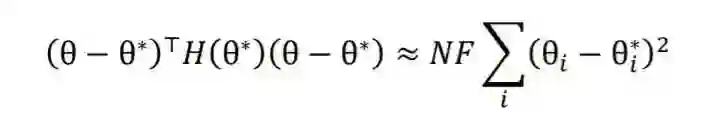
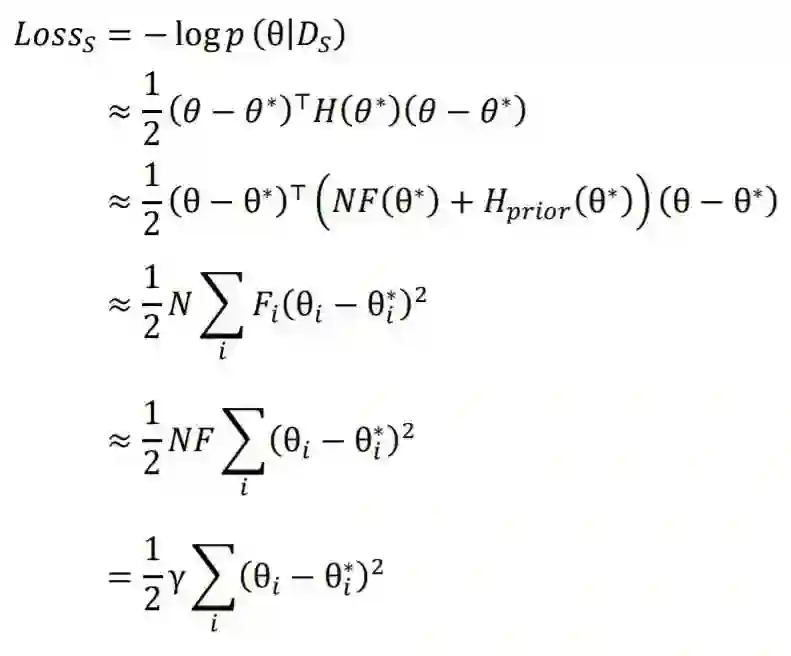
2.2 目标迁移机制
对于多任务学习的优化目标与适应阶段不一致的第二项挑战,我们提出了目标迁移机制,通过使用退火系数使优化目标逐步迁移至目标任务上的损失函数 。
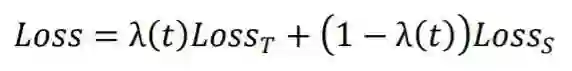
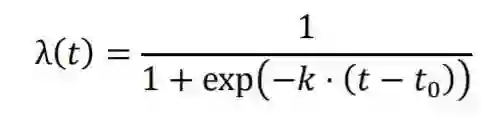
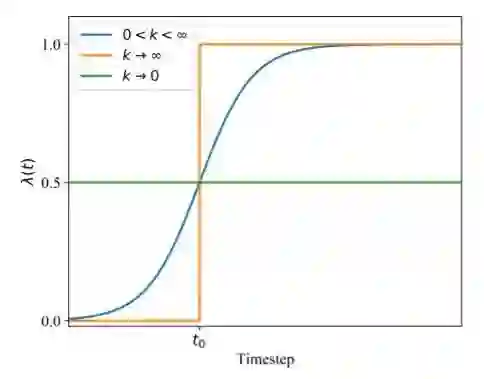
图1 目标迁移机制:我们用退火函数 代替多任务学习优化目标中的系数 。精调和多任务学习可以视为我们的方法的特例( 和 )。
2.3 优化器
Adam优化器[11]通常被用于精调深层预训练语言模型。我们提出Recall Adam(RecAdam)优化器,将预训练模拟机制(3.1节)和目标平移机制(3.2节)机制的核心因子二次惩罚项和退火系数融入Adam优化器,并将它们从梯度更新算法中解耦。
[12]观察到L2正则化和权重衰减对于诸如Adam的自适应梯度算法并不相同,通过将权重衰减从Adam梯度更新算法中解耦,得到AdamW优化器,并且从理论上和经验上证实可以有效地提高Adam的性能。
同样地,当使用Adam优化器精调预训练语言模型时,我们有必要将二次惩罚和退火系数从梯度更新算法中解耦。否则,二次惩罚和退火系数都将通过梯度更新规则进行调整,从而导致不同的模型权重所对应二次惩罚的大小是不同的。

算法1中显示了Adam和RecAdam之间的比较,其中SetScheduleMultiplier(t)(第11行)代指获取步长比例因子的过程(例如预热技术)。
实验结果
我们使用深层预训练语言模型BERT-base[13]和ALBERT-xxlarge[3] 在通用语言理解评估(GLUE)数据集[14]进行实验来评估我们的方法。
表1显示了基于BERT-Base和ALBERT-xxlarge模型在GLUE数据集的开发集上我们提出的RecAdam精调方法与普通精调方法的单任务单模型的比较结果。表2显示了基于BERT-Base模型在GLUE数据集的测试集上我们提出的RecAdam精调方法与普通精调方法的单任务单模型的比较结果。
表1 GLUE 数据集的开发集上的最先进的单任务单模型结果。
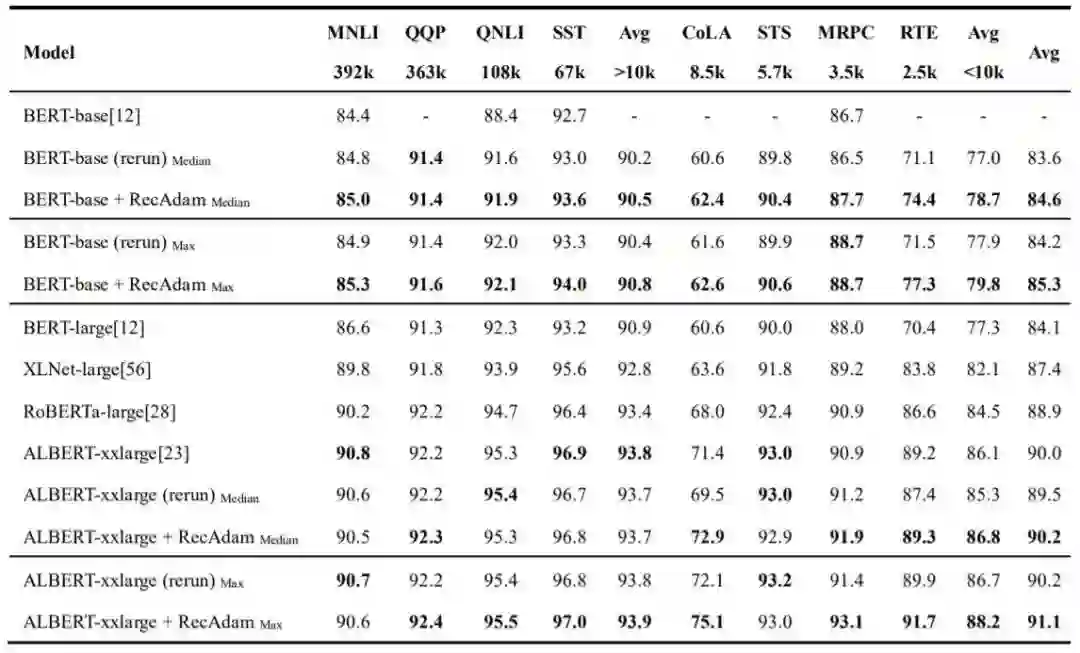
表2 GLUE 数据集的测试集上的单任务单模型结果,由 GLUE 服务器进行评分。我们提交 了在每个开发集上得到的最佳模型的结果。

3.1 基于BERT-base的结果
基于BERT-base模型,我们在GLUE数据集8个任务中的7个任务上实现了优于基线方法的开发集结果,并且平均在每个任务上提高了1.0%的中位数结果和1.1%的最大值结果。
尤其对于训练数据较小(<10k)的任务,与普通的精调方法相比,我们的方法可以实现显着的提升(平均+1.7%)。
由于训练数据的缺乏,这些任务上进行的普通的精调会较为脆弱,并且容易出现过拟合和灾难性遗忘的问题[15, 16]。借助所提出的RecAdam方法,我们可以通过在学习目标任务时回忆预训练任务的知识从而实现更好的精调。
值得注意的是,相较于普通精调BERT-large模型,我们可以通过使用RecAdam方法精调BERT-base模型在一半以上的任务上获得更好的结果(RTE:+ 4.0%,STS:+ 0.4%,CoLA:+ 1.8%,SST:+ 0.4%,QQP:+ 0.1%),并且在所有GLUE任务上平均能够取得更好的中位数结果(+ 0.5%)。
得益于RecAdam方法可以有效地减少灾难性遗忘,我们可以使用包含更少参数的预训练模型来获得更好的实验结果。
基于最先进的ALBERT-xxlarge模型,我们在GLUE数据集的8个任务中的5个任务上实现了优于基线方法的开发集结果,并在GLUE数据集的开发集上实现了单任务单模型的最先进的平均中位数结果90.2%。
与基于BERT-base模型的结果相似,我们发现我们的提升主要来自训练数据较少(<10k)的任务,我们可以基于ALBERT-xxlarge模型在这些任务上平均提高+ 1.5%的性能。此外,与[3]的结果相比,我们可以无需在MNLI任务上进行第二阶段的预训练,在RTE(+0.1%),STS(-0.1%)和MRPC(+ 1.0%)任务上取得相似或更好的中位数结果。
总体而言,基于ALBERT-xxlarge模型,我们平均在每个任务上提高了0.7%中位数结果,较低于我们基于BERT-base模型所获得的提升(+ 1.0%)。借助于先进的模型设计和预训练技术,ALBERT-xxlarge在GLUE数据集上获得了显著的性能提升,从而较难取得进一步的提升。
3.3 初始化分析
表3 不同的模型初始化策略的比较:预训练初始化策略和随机初始化策略

通过使用基于预训练模拟机制和目标迁移机制的RecAdam方法,我们可以使用随机值初始化模型参数,并在学习新任务的同时回顾预训练任务的知识。
那么初始化策略的选择是否会对我们的RecAdam方法的性能产生影响呢?
表2显示了基于不同初始化策略使用RecAdam方法精调BERT-base模型的结果比较。
结果表明,基于随机初始化策略和预训练初始化策略,RecAdam精调方法都可以在所有的四个任务上得到优于普通精调方法的结果。对于STS任务,通过预训练初始化的模型可以得到与随机初始化相同的结果。对于其他任务(CoLA,MRPC,RTE),随机初始化模型是更优的选择。这是因为通过随机初始化策略,模型会受益于更大参数搜索空间。
相比而言,如果使用预训练模型的参数进行初始化,模型的搜索空间将受限于预训练模型参数附近,从而使模型较难去逃离次优的局部最小区域从而在目标任务上取得更好的性能。
3.4 遗忘分析
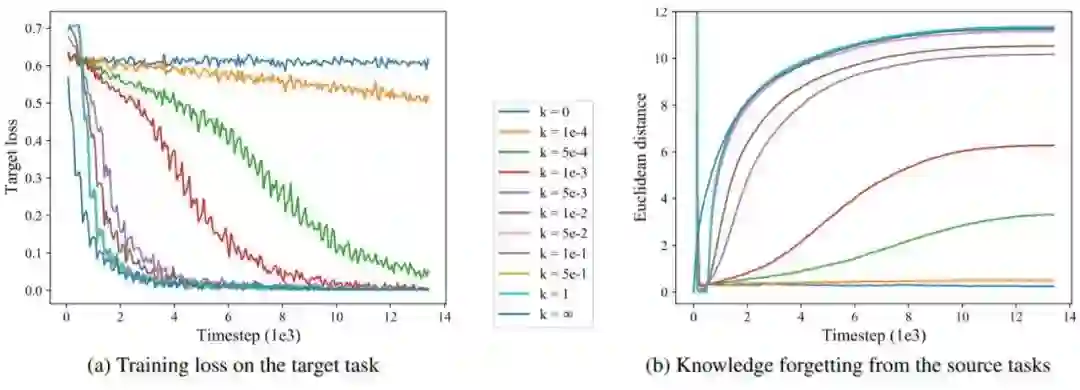
图2 在CoLA数据集上使用有着不同的 值的RecAdam方法精调BERT-base的学习曲线。
结论
参考文献


点击阅读原文,直达NeurIPS小组~

