【SIGIR2020-斯坦福大学】一种新的BERT类信息检索模型-又好又快的ColBERT
【导读】今日SIGIR2020刚刚公布了接受论文,来自斯坦福的两位学者发布了ColBERT,一种新的信息检索BERT模型,能够又好又快的进行检索,值得关注。

https://arxiv.org/abs/2004.12832
在过去的几年里,信息检索(IR)社区见证了一系列神经排序模型的引入,包括DRMM[8]、KNRM[5,36]和Duet[21,23]。与之前依赖手工特性的学习排序方法相比,这些模型采用基于嵌入式的查询和文档表示,并直接对本地交互进行建模(例如,在它们的内容之间。其中,最近出现了一种方法,即微调深度预训练语言模型(LMs),如ELMo[29]和BERT[6],以估计相关性。通过计算查询-文档对的深度上下文语义表示,这些LMs有助于弥补文档和查询[30]之间普遍存在的词汇表不匹配[22,42]。事实上,在短短几个月的时间里,许多基于BERT的排名模型已经在各种检索基准上取得了最先进的结果[4,19,25,39],并被Google1和Bing2所独有地采用。
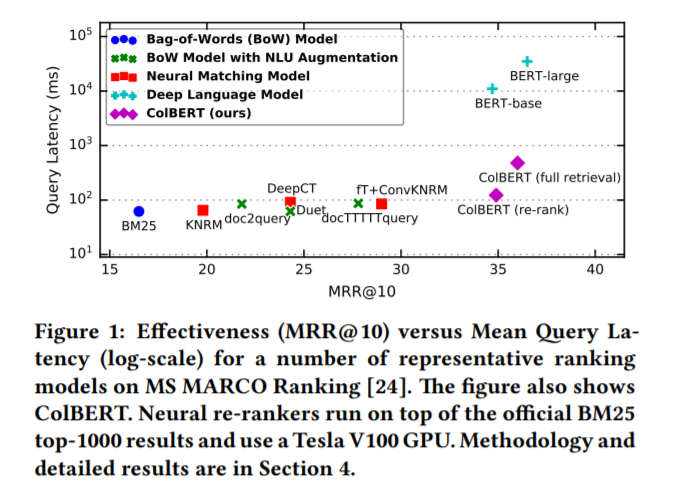
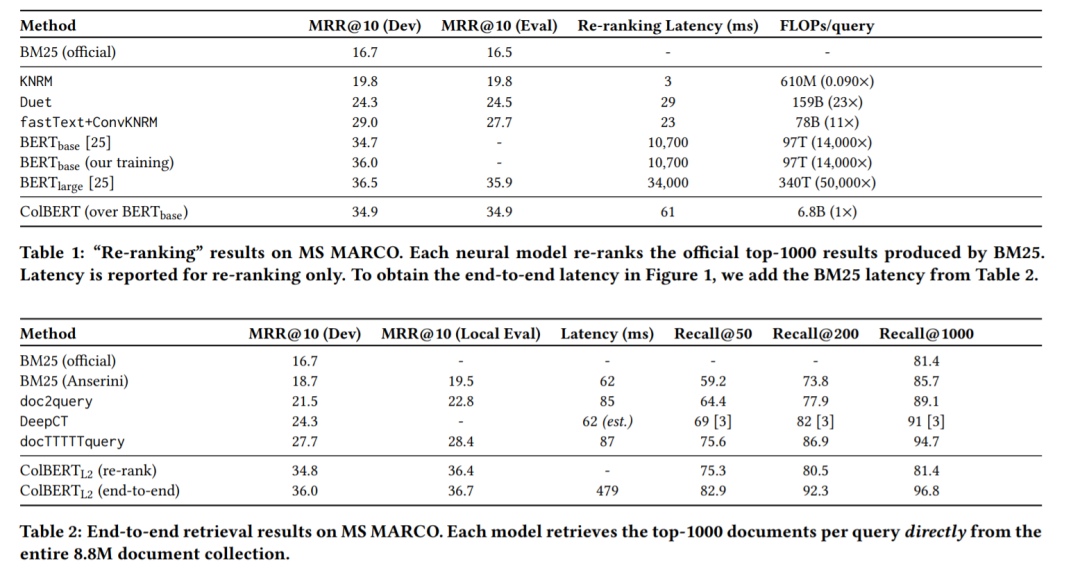
然而,这些LMs带来的显著收益是在计算成本急剧增加的情况下实现的。Hofstatter¨等人的[10]和MacAvaney等人的[19]观察到,文献中基于bert的模型在计算上比以前的模型要昂贵100-1000倍,其中一些模型在开始使用[14]时可能并不便宜。图1总结了这种质量成本权衡,它将两个基于bert的排名者[25,27]与一组有代表性的排名模型进行了比较。这个数字使用了MS MARCO[24]的排名,这是必应最近收集的900万篇文章和100万条查询。它报告了在官方验证集上的检索效率(MRR@10),以及使用高端服务器的平均查询延迟(log-scale)。按照MS MARCO的重新排序设置,ColBERT(重新排序)、神经匹配模型和深度LMs对MS MARCO的每个查询的官方前1000个文档重新排序。其他方法,包括ColBERT(完全检索),直接从整个集合中检索前1000个结果。
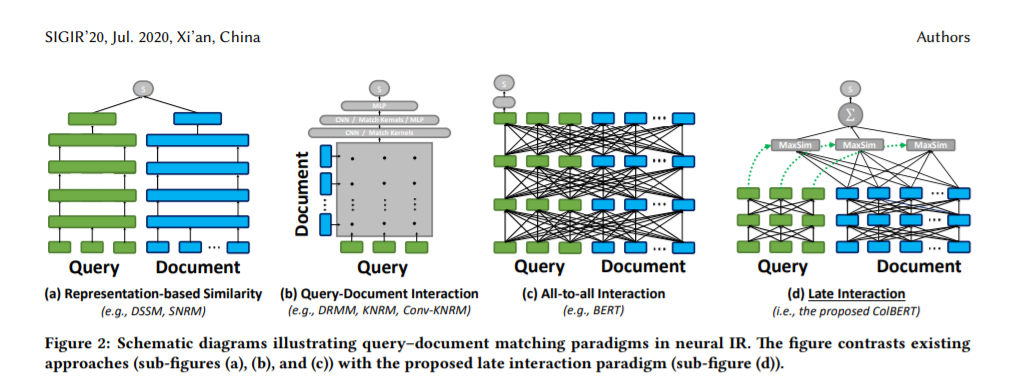
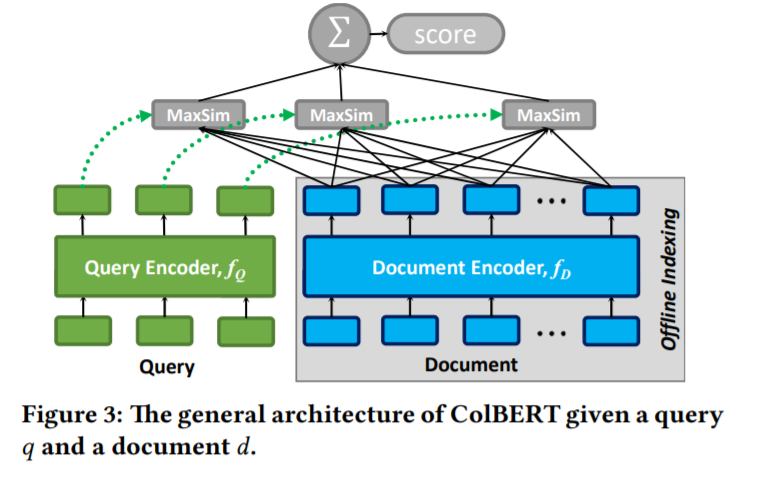
为了在IR中协调效率和情景化,我们提出了基于情景化后期交互的ColBERT排序模型。顾名思义,ColBERT提出了一种新颖的后期交互范式,用于估计查询q和文档d之间的相关性。在后期交互下,q和d分别编码为两组上下文嵌入,并使用两组集合之间的廉价且友好的裁剪计算来评估相关性——也就是说,快速计算可以在不完全评估每个可能的候选者的情况下进行排序。
更多请查看 《深度学习搜索》新书327页pdf

《Deep Learning for Search》利用神经网络、NLP和深度学习技术来提高搜索性能。深度学习处理最困难的搜索挑战,包括不精确的搜索条件、索引糟糕的数据和使用最少的元数据检索图像。有了像DL4J和TensorFlow这样的现代工具,您就可以应用强大的DL技术,而不需要在数据科学或自然语言处理(NLP)方面有深入的背景知识。这本书会告诉你怎么做。
第1部分介绍了搜索、机器学习和深度学习的基本概念。第一章介绍了应用深度学习技术来搜索问题的原理,涉及了信息检索中最常见的方法。第2章给出了如何使用神经网络模型从数据中生成同义词来提高搜索引擎效率的第一个例子。
第2部分讨论了可以通过深度神经网络更好地解决的常见搜索引擎任务。第3章介绍了使用递归神经网络来生成用户输入的查询。第四章在深度神经网络的帮助下,在用户输入查询时提供更好的建议。第5章重点介绍了排序模型:尤其是如何使用词嵌入提供更相关的搜索结果。第6章讨论了文档嵌入在排序函数和内容重新编码上下文中的使用。
第3部分将介绍更复杂的场景,如深度学习机器翻译和图像搜索。第7章通过基于神经网络的方法为你的搜索引擎提供多语言能力来指导你。第8章讨论了基于内容的图像集合的搜索,并使用了深度学习模型。第9章讨论了与生产相关的主题,如微调深度学习模型和处理不断输入的数据流。
https://www.manning.com/books/deep-learning-for-search
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DLS2020” 就可以获取《最新《深度学习搜索》新书327页pdf,和SIGIR2020-ColBERT论文》专知下载链接







