收藏 | 知识图谱论文大合集,干货满满的笔记解读(附资源)

来源:PaperWeekly
本文约6134字,建议阅读15分钟。
本文整理了关于知识图谱的多篇顶会论文,带你了解知识图谱的最新进展。
ACL 2018

链接:https://www.paperweekly.site/papers/2108
解读:刘兵,东南大学计算机学院博士,研究方向为机器学习、自然语言处理
动机
远程监督关系抽取方法虽然可以使用知识库对齐文本的方法得到大量标注数据,但是其中噪声太多,影响模型的训练效果。基于 bag 建模比基于句子建模能够减少噪声的影响,但是仍然无法克服 bag 全部是错误标注的情形。
为了换机噪声标注,本文提出基于对抗神经网络的方法,尝试从自动标注数据中清除噪声。实验结果表明,本文提出的方法能够有效去除噪声,提升远程监督方法的抽取性能。
方法框架
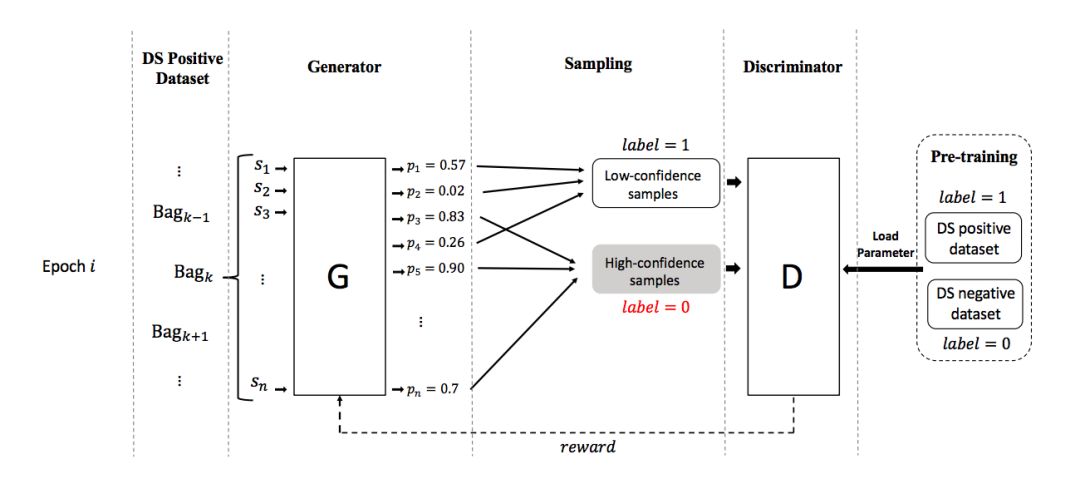
本文提出的方法包括一个生成器和一个判别器,他们的功能是:
生成器:生成器用于将关于关系 r 的有噪声的数据 P 划分成两组:表示正确标注数据的 TP 和表示错误标注数据的 FP。模型会输出每个句子是正确标注的概率,然后依据该概率抽样,得到 TP,剩余的作为 FP。
判别器:评价生成器生成的数据划分的好坏。评价的方法是:首先使用标注为关系 r 的数据 P 和非 r 的数据 N 对判别器做预训练。在评价生成器的划分 TP FP 时,有意颠倒 TP FP 的标签,即 TP 标记为负例,FP 标记为正例,从而形成错误的训练数据,使用该数据继续训练判别器,看看该判别器性能下降情况。判别器性能下降越多,说明颠倒标签的 TP FP 越错误,也就是 TP FP 越正确。
对抗过程是:生成器生成数据划分之后,判别器通过训练过程来评价该划分的好坏,并将结果反馈给生成器。生成器根据反馈生成更好的数据,从而更大程度地降低判别器的判别能力。
实验
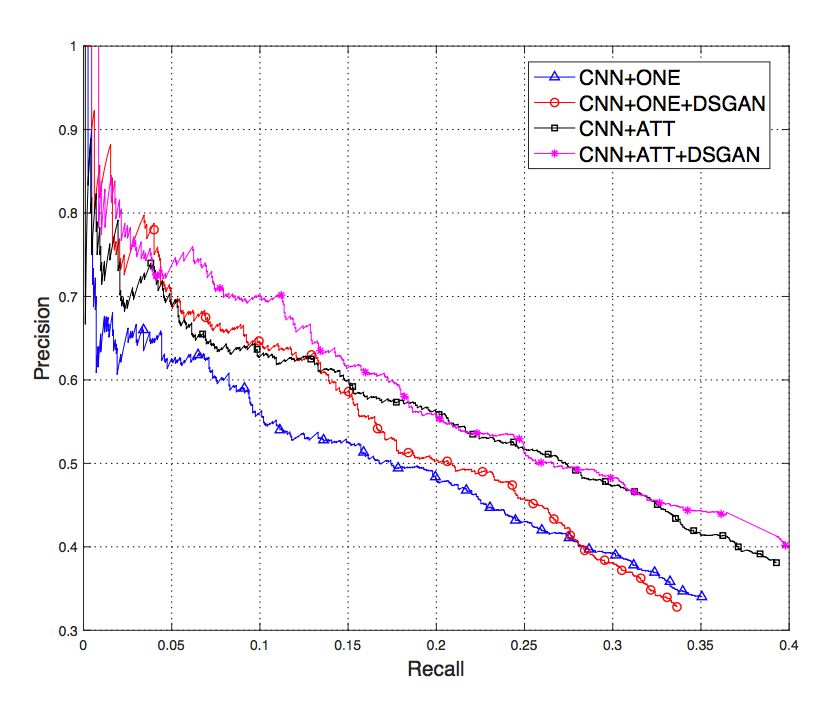
实验部分分析了训练过程中生成器和判别器的收敛情况、以及去噪效果。在去噪效果方面,从下面的 P-R 图可以看出,在去噪后的数据上训练得到的模型比在去噪前的数据上训练的模型效果更好。
AAAI 2018

链接:https://www.paperweekly.site/papers/2109
解读:徐康,南京邮电大学讲师,研究方向为情感分析、知识图谱
任务简介
特定目标的基于侧面的情感分析,在原来基于侧面的情感分析的基础上,进一步挖掘细粒度的信息,分析特定对象的侧面级别的情感极性。具体任务的示例如图 1 所示,给定句子识别该句子描述了哪个目标的哪个侧面,并且识别出关于该侧面的情感极性。


图2 文本描述多个目标的多个侧面的示例
从图 2 的示例中,我们可以看出真实的文本描述中,我们可能同时描述多个目标和关于这些目标的多个侧面,原来基于侧面的情感分析,一般用于评论分析,假定目标实体已经给定,因此该任务只能识别出侧面以及分类该侧面的情感,更一般的情况,该任务并不能解决,因此,需要构建新的任务,特定目标的基于侧面的情感分析,同时抽取文本的描述的目标、它们对应的侧面以及描述这些侧面的情感极性。
例如,给定句子“I live in [West London] for years. I like it and itis safe to live in much of [west London]. Except [Brent] maybe.”包含两个目标 [west London] 和 [Brent]。
我们的目标就是识别目标的侧面并且分类这些侧面的情感。我们想到的输出就是:
关于目标 [WestLondon] 的结果 [‘general’:positive;‘safety’:positive]
关于目标 [Brent] 的结果 [‘general’: negative; ‘safety’:negative]
现有方法的不足:
在一个句子中,同一个目标可能包含多个实例(同一个目标的不同表述方式,例如,同义词、简写等)或者一个目标对应一个句子中的多个词语。但是,现有的方法都假设所有的实例对于情感分类的重要性是一样的,简单地计算所有实例的向量的均值。事实上,同一个目标中的个别实例对于情感分类的重要性明显高于其他的实例。
现有的层次注意力机制模型将关于给定目标、侧面和情感的建模过度简化成一种黑盒的神经网络模型。现有的研究方法都没有引入外部知识(情感知识或者常识知识)到深度神经网络,这些知识可以有助于侧面和情感极性的识别。
模型简述和常识知识
本文提出的神经结构如图 2 所示,包含两个模块:序列编码器和层次注意力模块。给定一个句子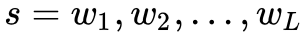
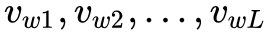
其中序列编码器基于双向 LSTM,将词向量转换成中间隐含层序列输出,注意力模块置于隐含层输出的顶部,其中比较特殊的是,本结构中加入目标级别的注意力模块该模块的输入不是序列全部的中间隐含层输出,而是序列中描述目标对象对应的位置的词语的隐含层输出(如图 2 中的紫色模块),计算这些词语的自注意向量 Vt。
这里目标级别的注意力模块的输出表示目标,目标的表示结合侧面的词向量用于计算句子级别的注意力表示,将整个句子表示一个向量,这个句子级别的注意力模块返回一个关于特定目标和侧面的句子向量,然后用这个向量预测这个目标对应的侧面的情感极性。
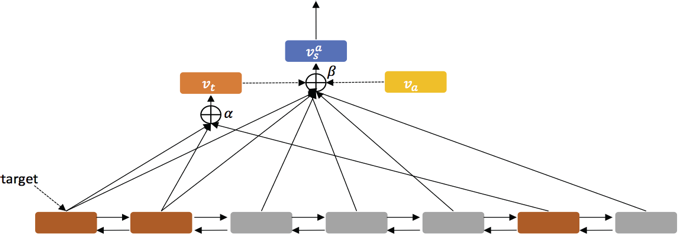
图3 注意力神经结构
为了提升情感分类的精确度,本文使用常识知识作为知识源嵌入到序列编码器中。这里使用 SenticNet 作为常识知识库,该知识库包含了 5000 个概念关联了丰富的情感属性(如表 1 所示),这些情感属性不但提供了概念级别的表示,同时提供了侧面和它们的情感之间对应的语义关联。
例如,概念“rottenfish”包含属性“KindOf-food”可以直接关联到侧面“restaurant”或者“food quality”,同时情感概念“joy”可以支撑情感极性的分类(如图 4 所示)。
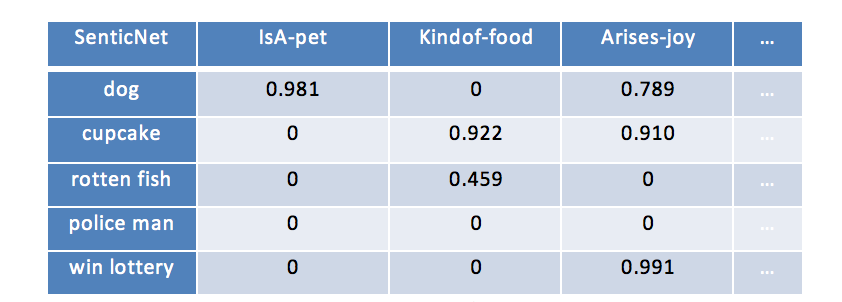
表1 SenticNet 的示例
因为 SenticNet 的高维度阻碍了将这些常识知识融合到深度神经网络结构中。AffectiveSpace 提出了方法将 SenticNet 中的概念转化成连续低维度的向量,而且没有损失原始空间中的语义和情感关联。基于这个新的概念空间,本文将概念级别的信息嵌入到深度神经网络模型中可以更好地分类自然语言文本中的侧面和情感分类。
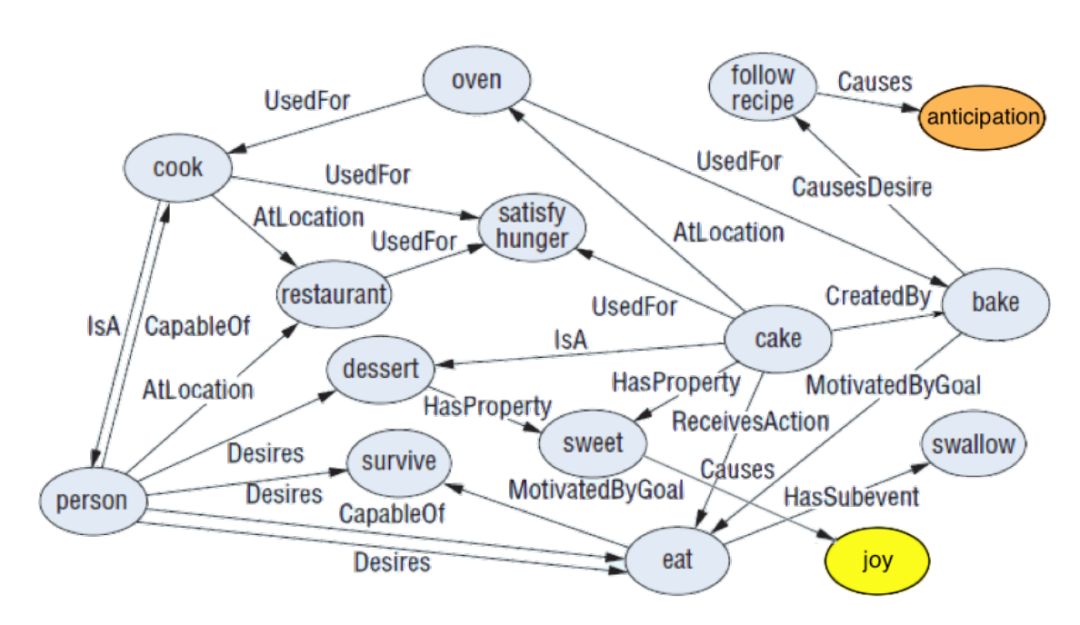
图4 SenticNet 语义网络的部分
实验结果
本文主要评估了两个子任务:
一是侧面分类
二是基于侧面的情感分类
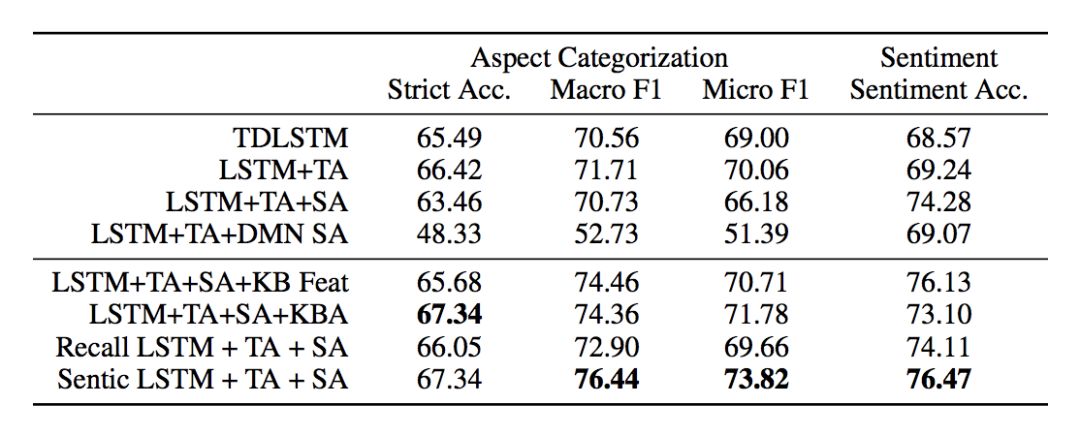
主要评估两个测度,精确度、Macro-F1 和 Micro-F1;实验室的数据集包括 SentiHood 和 Semeval-2015;常识知识库使用 SenticNet 和使用 AffectiveSpace 作为概念 embedding,如果没有抽取到概念,那么使用零向量作为输入。实验结果如图 5 和图 6 所示。
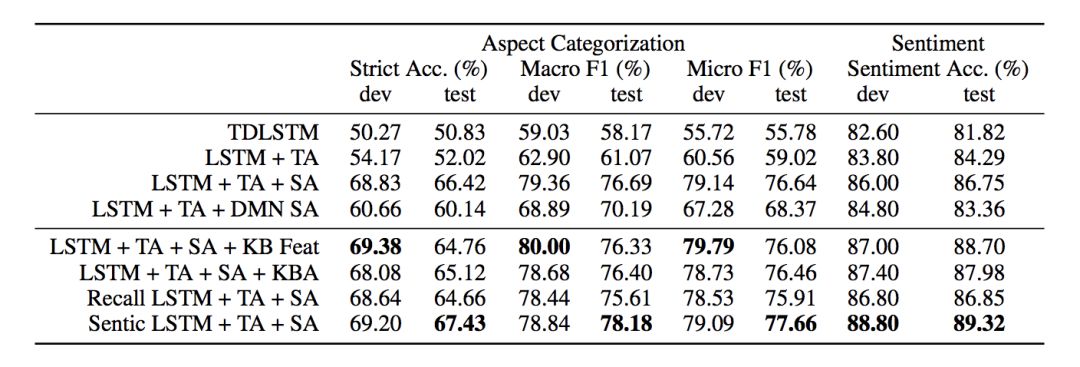
图5 在 SentiHood 数据集上的性能
WWW' 2018

链接:
https://www.paperweekly.site/papers/2097
解读:邓淑敏,浙江大学博士生,研究方向为知识图谱与文本联合表示学习,动态知识图谱,时序预测
动机
推荐系统最初是为了解决互联网信息过载的问题,帮助用户针推荐其感兴趣的内容并给出个性化的建议。新闻具有高度时效性和话题敏感性的特点,一般而言新闻的热度不会持续太久,而且用户关注的话题也多是有针对性的。其次,新闻的语言高度浓缩,往往包含很多常识知识,而目前基于词汇共现的模型,很难发现这些潜在的知识。因此这篇文章提出了 DKN,将知识表示融合到新闻推荐系统中。
模型
首先看一下 DKN 模型的框架,如下图所示:
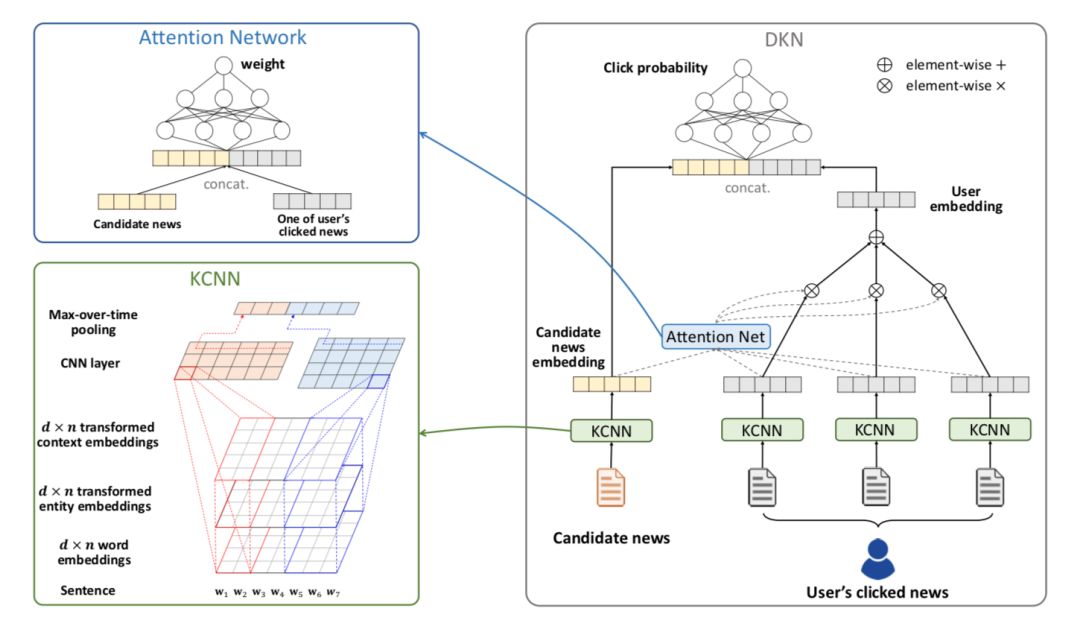
DKN 模型主要分成三部分:
知识抽取(Knowledge Distillation)
知识感知卷积神经网络(KCNN: Knowledge-aware CNN)
用于抽取用户兴趣的注意力网络(Attention Network: Attention-based UserInterest Extraction)
下面对这三部分进行详细的介绍。
1. 知识抽取
知识抽取模块的输入是一些用户点击的新闻标题以及候选新闻的标题。整个过程可以参见下图。
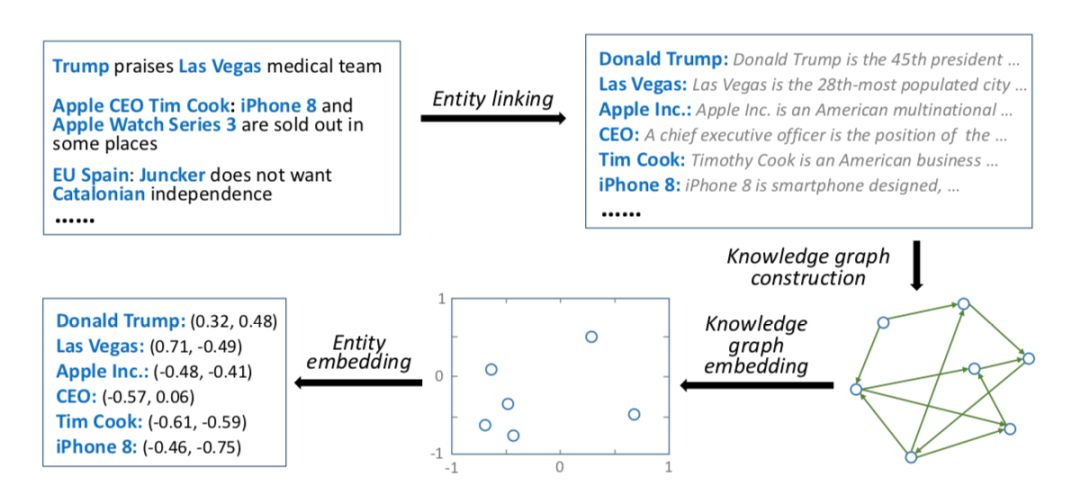
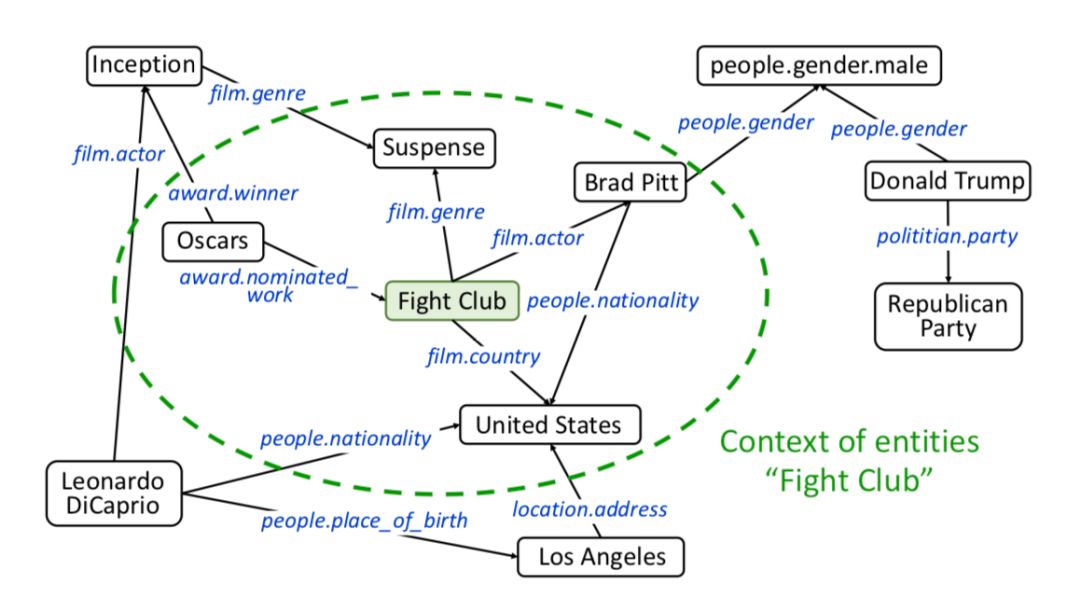
首先将标题拆成一组词,然后将标题中的词与知识库的实体进行链接。如果可以找到词所对应的实体,那么再接着找出距离链接实体一跳之内的所有邻接实体,并将这些邻接实体称之为上下文实体。寻找上下文实体的过程如下图所示。
这样,根据新闻标题可以得到三部分的信息,分别是词,链接实体,以及上下文实体。利用 word2vec 模型可以得到词的向量表示,利用知识图谱嵌入模型(这里用的 TransD)可以得到知识库实体的向量表示。
其中,链接实体的表示就是 TransD 的训练结果,如果链接不上就 padding。上下文实体的表示就是对多个实体的表示进行平均,如果前一步没有链接实体这里也同样 padding。由此分别得到了词、链接实体、上下文实体的向量表示。
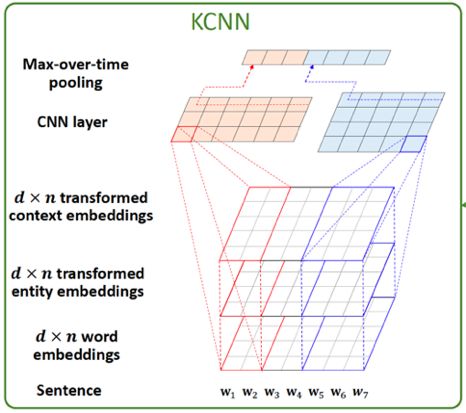
2. 知识感知卷积神经网络
KCNN 在得到新闻标题三方面信息的向量表示之后,下一步是要将它们放到同一个模型中进行训练。但是这里存在的问题是,三者不是通过同一个模型学出来的,直接放到同一个向量空间不合理。这篇文章使用的方法是,先把链接实体、上下文实体的向量表示通过一个非线性变换映射到同一个向量空间:
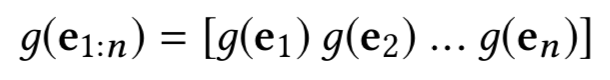
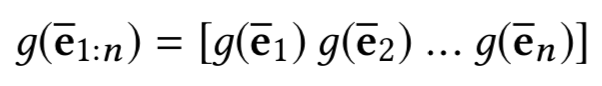
然后类似于图像中 RGB 的三通道,将词、链接实体、上下文实体的向量表示作为 CNN 多通道的输入。这样 KCNN 的输入就可以表示为:
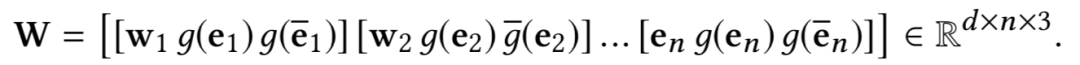
然后通过卷积操作得到新闻标题的向量表示:
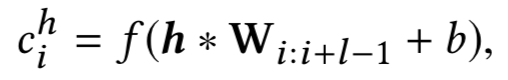
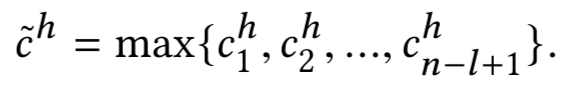
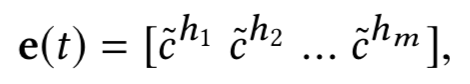
KCNN 的架构可以参考下图。这里还用了不同大小的卷积核进行卷积。
3. 注意力网络
给定用户 i 的点击历史新闻:
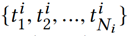
通过 KCNN 得到它们的向量表示:
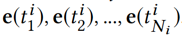
采用一个 DNN 作为注意力网络和一个 softmax 函数计算归一化影响力权重:
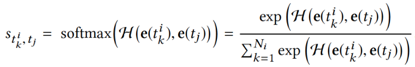
这样可以得到用户 i 关于候选新闻 t_i 的向量表示:
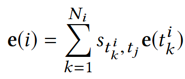
用户 i 点击新闻 t_j 的概率由另一个 DNN 预测:
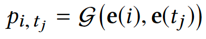
实验
数据集 :这篇文章的数据来自 bing 新闻的用户点击日志,包含用户 id,新闻 url,新闻标题,点击与否(0未点击,1点击)。搜集了 2016 年 10 月 16 日到 2017 年 7 月 11 号的数据作为训练集。2017年7月12号到8月11日的数据作为测试集合。使用的知识图谱数据是 Microsoft Satori。以下是一些统计数据以及分布。
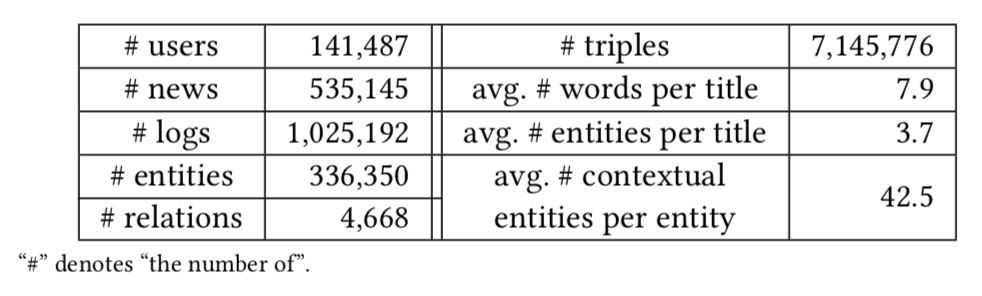
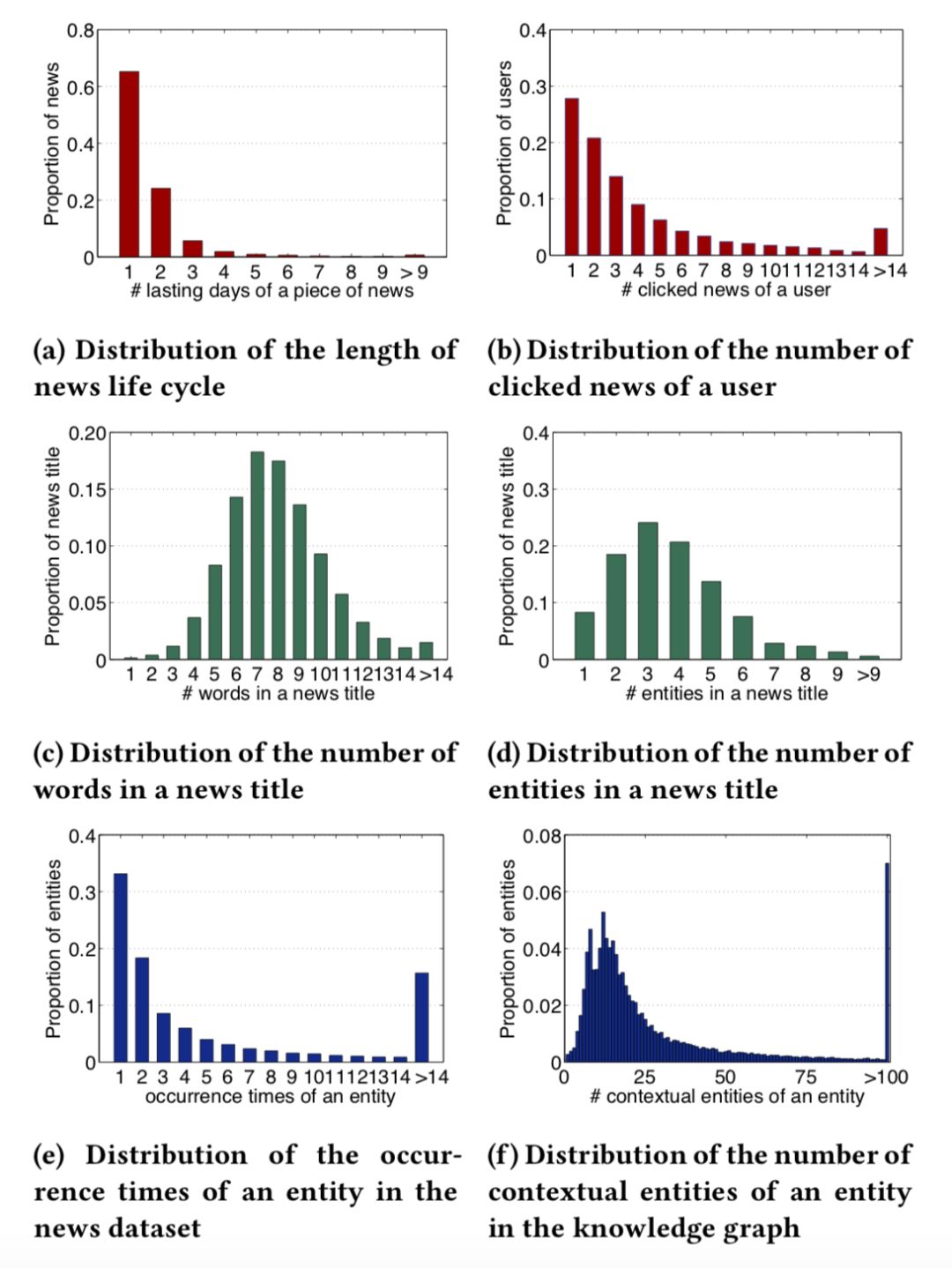
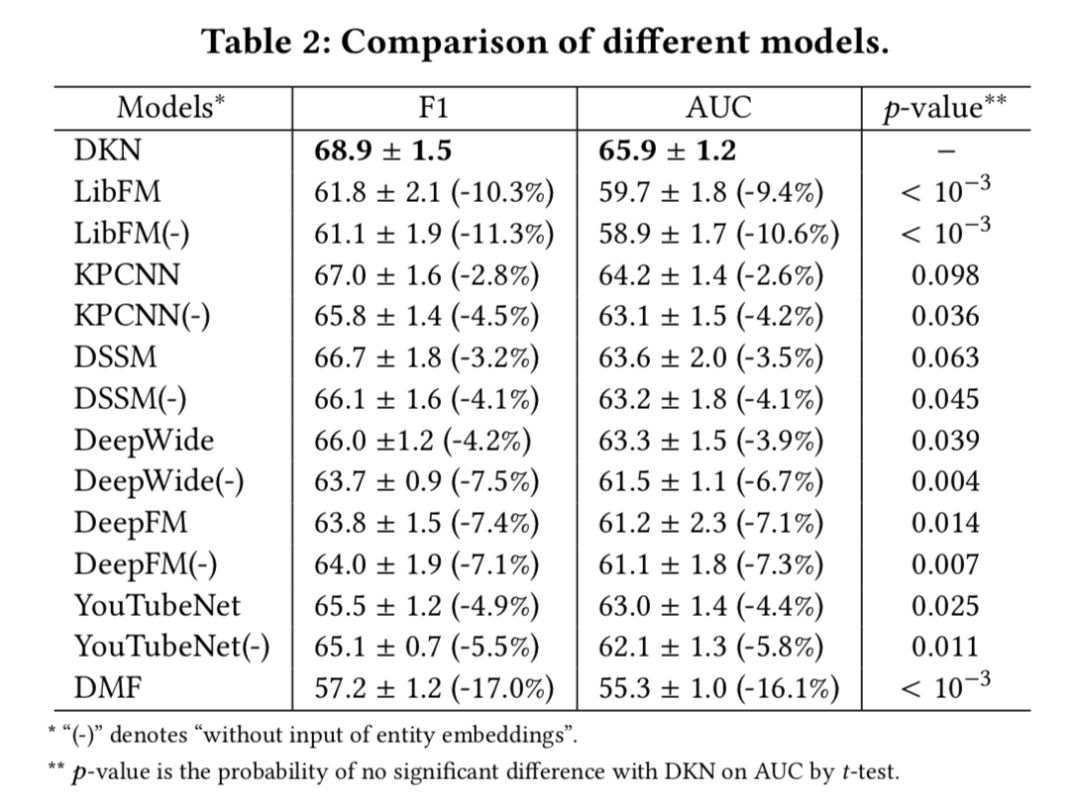
实验用的评价指标是 AUC 和 F1,对比实验结果如下表所示。
下面这张表展示了 DKN 本身的一些变量对实验结果的影响:
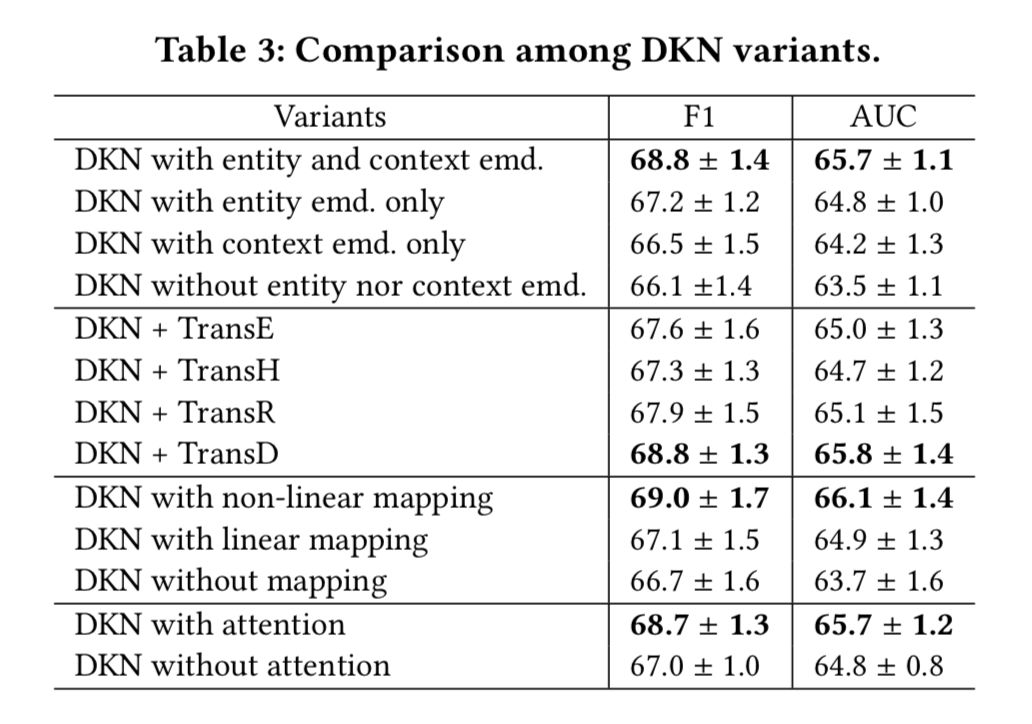
笔者认为,DKN 的特点是融合了知识图谱与深度学习,从语义层面和知识两个层面对新闻进行表示,而且实体和单词的对齐机制融合了异构的信息源,能更好地捕捉新闻之间的隐含关系。利用知识提升深度神经网络的效果将会是一个不错的方向。
AAAI 2018

链接:https://www.paperweekly.site/papers/1988
源码:https://github.com/adityaSomak/PSLQA
解读:杨海宏,浙江大学博士,研究方向为知识问答与推理
论文概述
视觉问答(Visual Question Answering)现有两大类主流的问题, 一是基于图片的视觉问答(ImageQuestion Answering),二是基于视频的视觉问答(Video Question Answering)。而后者在实际处理过程中,常常按固定时间间隔取帧,将视频离散化成图片(frame)的序列,剔除大量冗余的信息,以节省内存。
当前视觉问答的研究主要关注以下三个部分:
延续自然语言处理中,对注意力机制(Attention Mechanism)和记忆网络(Memory Network)的研究,旨在通过改进二者提高模型对文本和图像信息的表达能力,通过更丰富的分布式表示来提升模型的精度。另一方面,也可以视作是对神经计算机(Neural Machine)其中键值模块(Key-value,对应注意力)和缓存模块(Cache,对应记忆网络)的改进。
密集地研究可解释性(Interpretability)和视觉推理(Visual Reasoning)。对同领域多源异构数据,这类研究方向将问答视为一种检索或人机交互方式,希望模型能提供对交互结果(即答案)的来由解释。
将文本或图像,以及在图像中抽取的一系列信息,如场景图谱(SceneGraph),图片标题(Image Caption)等视为是”知识来源”,在给定一个问题时,如何综合考虑所有的知识,并推断出最后的答案。
文章开头提到的论文,便是朝着第三个方向再迈进一步。
模型
本文提出的主要模型,是一个基于一阶谓词概率软逻辑(Probabilistic Soft Logic)的显式推理机。如果你已经训练好了一个用于视觉问答的神经网络模型,那么这个显式推理机可以根据模型的输出结果,综合考虑信息后,更正原本模型的输出结果。这样的后处理能提升模型的精度。下图就是一个这样的例子。
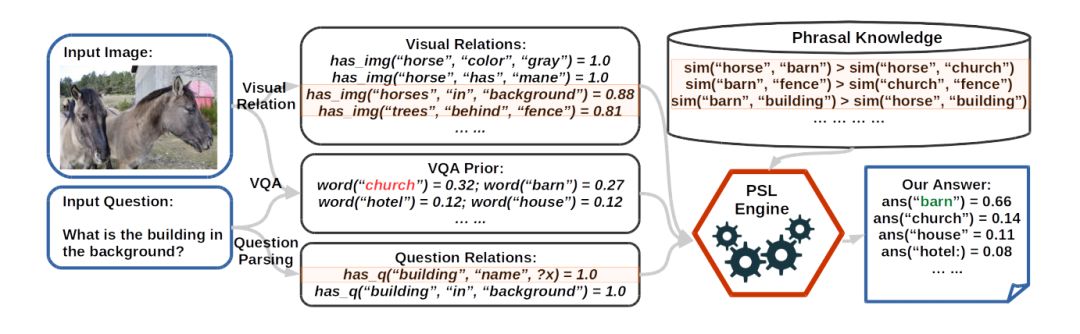
图1 一个正面例子
图 1 中红色六边形标示的 “PSL Engine”,是显式推理的核心部分。通过这一个部分,将 “VQA” 的预测结果与” Visual Relation(视觉关系)”,“Question Relation(问题关键词关系)”和”Phrasal Knowledge(语言常识)”三部分信息综合起来进行推理,更新答案。此处是一个正向例子。
推理过程具体如下:
生成 VQA 答案:存在一个视觉问答的神经网络模型,对于这幅图片和相应问题,预测出最有可能的答案是:教堂(church)和谷仓(barn)。
生成Visual Relation:通过利用 Dense Captioning system (Johnson, Karpathy, and Fei-Fei 2016) 生成图片的文本描述,再用 Stanford Dependency Parsing (De Marneffe et al. 2006) 抽取生成描述中的关键词,再启发式的方法为关键词对添加上关系,构成三元组。这代表了从图片中抽取出有效的结构化信息.。
生成 Question Relation:再次使用 StanfordDependency Parsing 及启发式方法抽取问题中包含的三元组信息。
生成 Phrasal Knowledge:将所有相关关键词在 ConceptNet 和词向量中索引,并计算相似度。
由概率软逻辑推理引擎综合前面四步生成的所有信息,更新 VQA 答案对应的得分并重新排序,得到新的结果。
在推理过程中,使用了概率软逻辑来综合考量各种生成的事实。其核心思想是:由谓词和变元组成的命题,真值不在局限于 1 或 0(真或假),而是可以在闭区间 [0, 1] 上取值。一个简单的例子是:
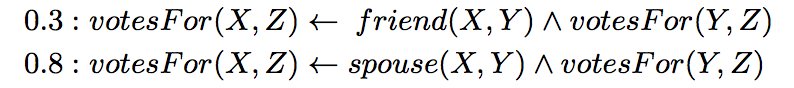
“X 和 Y 是朋友关系且 Y 为 Z 投票,蕴含 X 为 Z 投票”的权重是 0.3。而“X 和 Y 是伴侣关系且 Y 为 Z 投票,蕴含 X 为 Z 投票”的权重是 0.8。回到本文的例子,综合所有生成的命题并进行推理的过程如下:
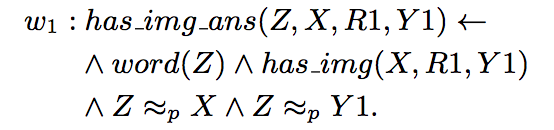
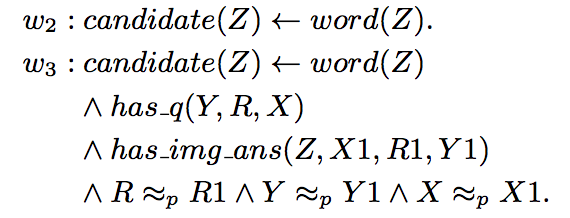
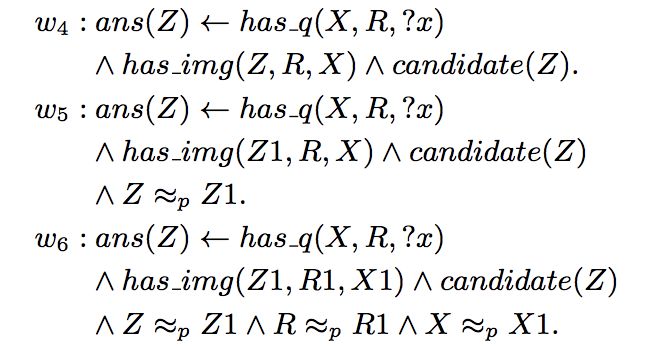
在此,命题的权重 w_i 是需要学习的部分。而优化的目标是使得满足最多条件的正确答案的权重最高。
实验
在数据集 MSCOCO-VQA (Antol et al. 2015) 测试,让我们看看效果:

WSDM 2018

链接:
https://www.paperweekly.site/papers/2110
解读:李林,东南大学硕士,研究方向为知识图谱构建及更新
动机
词语的演化伴随着意思和相关词汇的改变,是语言演化的副产品。通过学习词语的演化,能够推测社会趋势和人类历史中不同时期的语言结构,传统的词语表示技术并不能够捕获语言结构和词汇信息。本文提出了动态统计模型,能够学习到具有时间感知的词向量,同时解决了相邻时间片段中词向量的“对齐”,实现了用来进行语义发现的动态词向量模型。
论文贡献
本文的动态词向量模型可以看作传统“静态”词向量方法(如:word2vec)的提升。
本文通过在所有时间片段上并行的学习临时词向量,实现词向量的联合学习,然后通过正则化项平滑词向量的变化,解决了对准问题。实验结果表明,本文通过正则化项实现对准的方法优于传统动态词向量中分步进行训练和对准的方法。
本文利用块坐标下降方法来解决所有时间序列上词向量联合学习造成的计算问题。
本文的方法在不同的时间片段中,共享了大多数词的信息。这使得本文的方法针对数据稀疏问题,具有健壮性,使得能够处理一些时间片段中的罕见词汇。
模型
本文为不同的时间范围学习到了不同的向量表示,并通过距离的定义,选出和一个词相似的“邻居”。为不同的时间周期训练不同的词向量,一个关键问题,就是不同时间中的词向量如何对准;通常来说训练词向量的 cost function 具有旋转不变性,这样在不同时间对同一个词学习到的向量可能不在相同的潜在空间中,这使得为不同时间片段训练词向量时,词的位置可能变的杂乱无章,无法和上一个时间段的词向量进行对准。
本文通过对所有时间序列上的词向量进行联合学习,避免单独解决对准问题。具体的,通过在所有时间片段上并行的学习临时词向量,然后通过正则化项平滑词向量的变化,最后利用块坐标下降方法来解决时间序列上进行词向量联合学习的计算问题。
对于静态词向量的训练,本文计算了所有词汇之间的点互信息 PMI,把训练词向量中求内积的操作看作是点互信息值,那么类似于负采样这种词向量训练技巧可以看作点互信息 PMI 的低秩分解,真实数据往往非常稀疏,存在高效的低秩分解方法。通过在每一个时间片段上进行低秩分解,来为词向量引入时间参数:
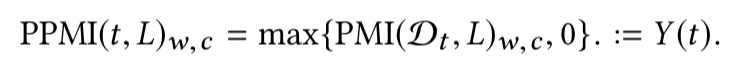
词向量 U(t) 可以通过分解 PPMI(t,L) 得到,通过最小化连续时间片段中词向量的 L2 范数来进行对准;整合以上内容,时态词向量的计算方法通过以下目标函数的最小化来得到:
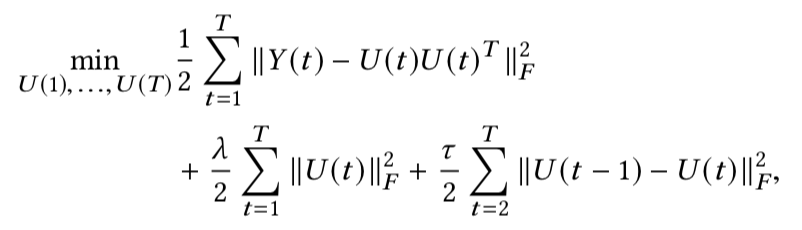
实验
本文使用的数据是从 New York Times 上抓取的 99872 篇文章。在定性分析中,apple,amazon,obama,trump 的词义变化轨迹如下所示:
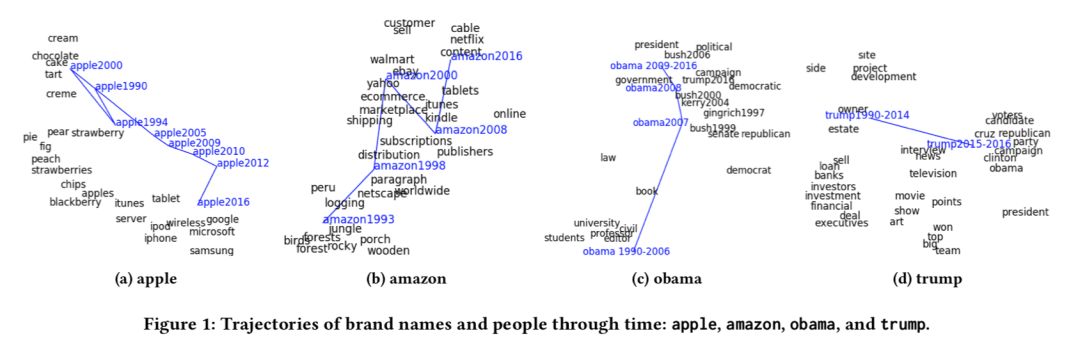
实验结果中,词义的变化轨迹通过“邻居”词汇的变化给出,能够清晰的看到语义的演化过程。表明了本文的动态词向量方法能够有效的捕获词义的演化。





