自学习 AI 智能体第一部分:马尔科夫决策过程

本文为 AI 研习社编译的技术博客,原标题 :
Self Learning AI-Agents Part I: Markov Decision Processes
翻译 | 老赵 校对 | Peter_Dong 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/self-learning-ai-agents-part-i-markov-decision-processes-baf6b8fc4c5f
注:本文的相关链接请点击文末【阅读原文】进行访问
这是关于自学习AI智能体系列的第一篇文章,或者更准确地称之为 - 深度强化学习。 本系列的目的不仅仅是让你对这些主题有所了解。 相反,我想让你更深入地理解深度强化学习最流行和最有效的方法背后的理论,数学和实现。
自学习AI智能体系列 - 目录
第一部分:马尔可夫决策过程(本文)
第二部分:深度Q学习
第三部分:深入(双重)Q-Learning
第四部分:继续行动空间的策略梯度
第五部分:决斗网络
第六部分:异步行为者-批评者

图1. AI智能体学会了如何运行和克服障碍。
马尔可夫决策过程(本文) - 目录
0. 简介
1. Nutshell中的强化学习
2. 马尔可夫决策过程
2.1 马尔可夫过程
2.2 马尔可夫奖励过程
2.3 价值函数
3. Bellman 方程
3.1 马尔可夫奖励过程的Bellman方程
3.2 马尔可夫决策过程 - 定义
3.3 策略
3.4 行动-价值函数
3.5 最优策略
3.6 Bellman最优化方程
0. 简介
深层强化学习正在兴起。 近年来,世界各地的研究人员和大众媒体都没有更多关注深度学习的其他子领域。 在深度学习方面取得的最大成就是由于深度强化学习。来自谷歌的Alpha Go在棋盘游戏Go中击败了世界上最好的人类玩家(这一成就在DeepMind'sAI主体之前几年被认为是不可能的,他们自学走路,跑步和克服障碍(图1-3)。)

图2. AI主体学会了如何运行和克服障碍。

图3. AI主体学会了如何运行和克服障碍。
自2014年以来其他人工智能主体在老式Atari游戏(如突破)中的水平性能表现提高了(图4)。 在我看来,关于所有这一切的最令人惊奇的事实是,这些AI主体中没有一个是由人类明确编程或教导如何解决这些任务。 他们通过深度学习和强化学习的力量自学。 这系列的第一篇文章的目标是为你提供必要的数学基础,以便在即将发表的文章中解决AI这个子领域中最有希望的领域。

图4.AI主体学习了如何玩Atari的突破。
1. Nutshell中的强化学习
深度强化学习可以概括为构建一个直接从与环境的交互中学习的算法(或AI主体)(图5)。 环境可能是现实世界,计算机游戏,模拟甚至是棋盘游戏,如Go或国际象棋。 就像人类一样,AI 主体从其行为的后果中汲取灵感,而不是明确地教导。
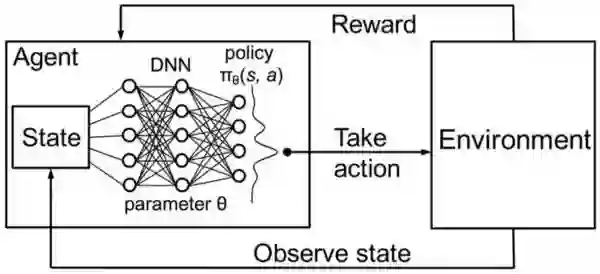
图5深层强化学习的示意图
在深度强化学习中,主体由神经网络表示。 神经网络直接与环境相互作用。 它观察当前的环境状况,并根据目前的状态和过去的经验决定采取哪些行动(例如左,右等)。 基于所采取的行动,AI主体收到奖励。 奖励决定了解决给定问题所采取行动的质量(例如学习如何行走)。主体的目标是学习在任何特定情况下采取行动,以最大化累积的奖励。
2. 马尔可夫决策过程
马尔可夫决策过程(MDP)是离散时间随机控制过程。 MDP是我们现在为止为AI主体的复杂环境建模的最佳方法。 主体解决的每个问题可以被认为是状态序列S1,S2,S3,... Sn(状态可以是例如Go /象棋板配置)。 主体执行操作并从一个状态移动到另一个状态。 在下文中,你将学习确定主体在任何给定情况下必须采取的操作的数学。
2.1 马尔可夫过程
马尔可夫过程是描述一系列可能状态的随机模型,其中当前状态仅依赖于先前状态。 这也称为Markov Property(Eq.1)。 对于强化学习,这意味着AI主体的下一个状态仅取决于最后一个状态而不是之前的所有先前状态。
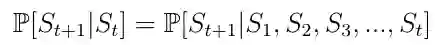
等式1 Markov 属性
马尔可夫过程是一个随机过程。 这意味着从当前状态s到下一个状态s'的转换只能以某个概率Pss'(等式2)发生。 在马尔可夫过程中,被告知要离开的主体只会以一定的概率如0.998离开。 由很小的概率环境来决定主体在何处结束。
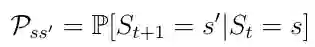
等式2 从状态s到状态s'的转换概率。
Pss'可以被认为是状态转移矩阵P中的条目,其定义从所有状态s到所有后继状态s'(等式3)的转移概率。
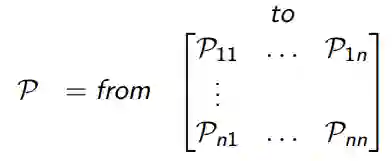
等式3. 转移概率矩阵
记住:马尔可夫过程(或马尔可夫链)是一个元组
2.2 马尔可夫奖励过程
马尔可夫奖励过程是元组
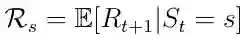
等式4. 状态的预期奖励
感兴趣的主要话题是总奖励Gt(等式5),它是主体将在所有状态的序列中获得的预期累积奖励。 每个奖励都由所谓的折扣因子γ∈[0,1]加权。 折扣奖励在数学上是方便的,因为它避免了循环马尔可夫过程中的无限回报。 除了折扣因素意味着我们未来越多,奖励变得越不重要,因为未来往往是不确定的。 如果奖励是金融奖励,立即奖励可能比延迟奖励获得更多利息。 除了动物/人类行为表明喜欢立即奖励。
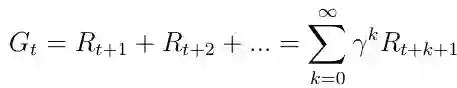
等式5. 所有状态的总奖励
2.3 价值函数
另一个重要的概念是价值函数v(s)之一。 价值函数将值映射到每个状态s。 状态s的值被定义为AI主体在状态s中开始其进展时将获得的预期总奖励(等式6)。

等式6. 价值函数,从状态s开始的预期收益。
价值函数可以分解为两部分:
主体接收的处于状态s的直接奖励R(t + 1)。
状态s之后的下一状态的折扣值v(s(t + 1))。
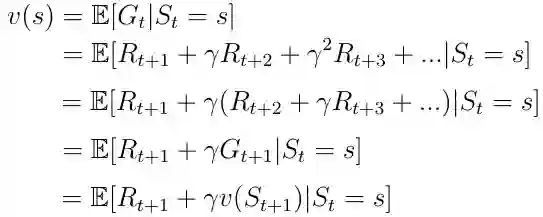
等式7. 价值函数的分解

3. Bellman 方程
3.1 马尔可夫奖励过程的Bellman方程
价值函数的分解(公式8)也称为马尔可夫奖励过程的 Bellman 方程。 该函数可以在节点图中显示(图6)。 从状态s开始导致值v(s)。 处于状态s我们有一定的概率Pss'最终在下一个状态s'。 在这种特殊情况下,我们有两个可能的下一个状态。为了获得值v(s),我们必须对由概率Pss'加权的可能的下一个状态的值v(s')求和,并从状态s中添加直接奖励。 如果我们在等式中执行期望算子E,则得到等式9,这不是等式8。
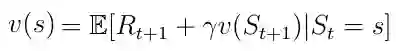
等式8. 分解价值函数
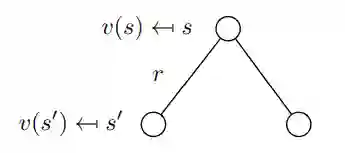
图6. 由 s 到 s' 的随机转移
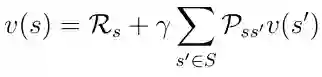
等式9. 执行期望E后的 Bellman 方程
3.2 马尔可夫决策过程 - 定义
马尔可夫决策过程是马尔可夫奖励过程的决策。 马尔可夫决策过程由一组元组
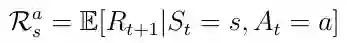
等式10. 预期奖励取决于状态内的行动。
3.3 策略
在这我们将讨论主体如何决定在特定状态下必须采取哪些行动。 这由所谓的策略 π(方程11)决定。 从数一点上,学角度讲,政策是对给定状态的所有行动的分布。 策略确定从状态 s 到主体必须采取的操作 a 的映射。
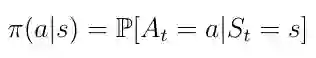
等式11 策略是从 s 到 a 的映射
记住:直观地说,策略 π 可以被描述为主体根据当前状态选择某些动作的策略。
该策略导致状态-价值函数v(s)的新定义(公式12),我们现在将其定义为从状态s开始的预期返回,然后遵循策略 π 。
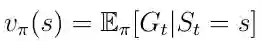
等式12 状态-价值函数
3.4 动作-价值函数
除状态-价值函数之外的另一个重要功能是所谓的动作-价值函数q(s,a)(等式13)。 动作-价值函数是我们通过从状态s开始,采取行动 a 然后遵循策略 π 获得的预期回报。 请注意,对于状态s,q(s,a)可以采用多个值,因为主体可以在状态s中执行多个操作。 Q(s,a)的计算是通过神经网络实现的。 给定状态作为输入,网络计算该状态下每个可能动作的质量作为标量(图7)。 更高的质量意味着在给定目标方面采取更好的行动。
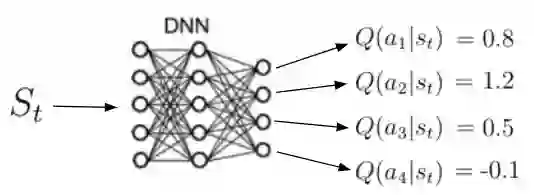
图7 动作-价值函数的图示
记住:动作-价值函数告诉我们在特定状态下采取特定行动有多好。
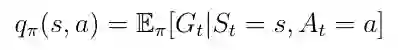
等式13 行动作-价值函数
以前,状态-价值函数v(s)可以分解为以下形式:
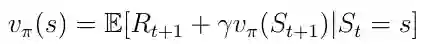
等式14 分解的状态-价值函数
相同的分解可以应用于动作-价值函数:
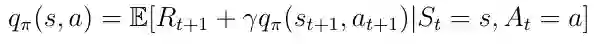
等式15 分解的动作-价值函数
在这一点上,我们讨论v(s)和q(s,a)如何相互关联。 这些函数之间的关系可以在图中再次可视化:
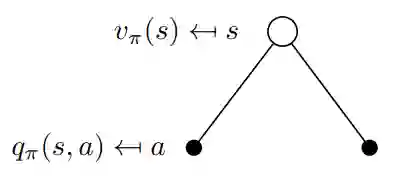
图8 v(s)和q(s,a)之间关系的可视化
在这个例子中处于状态 s 允许我们采取两种可能的动作 a 。 根据定义,在特定状态下采取特定动作会给我们动作值q(s,a)。 值函数v(s)是在状态 s(等式16)中采取动作a的概率加权的可能q(s,a)的总和(其不是策略 π 除外)。
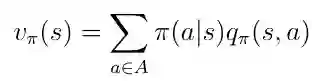
等式16 状态-价值函数作为行动-价值的加权和

现在让我们考虑图9中的相反情况。二叉树的根现在是一个我们选择采取特定动作的状态。 请记住,马尔可夫过程是随机的。 采取行动并不意味着您将以100%的确定性结束您想要的目标。 严格地说,你必须考虑在采取行动后最终进入其他州的概率。 在采取行动后的这种特殊情况下,您可以最终处于两个不同的下一个状态s':
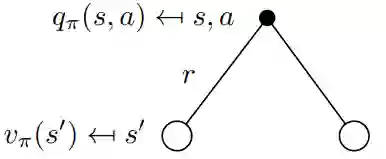
图9 v(s)和q(s,a)之间关系的可视化
要获得动作值,你必须采用由概率Pss'加权的贴现状态值,以最终处于所有可能的状态(在这种情况下仅为2)并添加即时奖励:
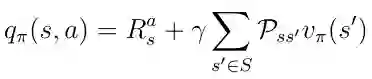
等式17 q(s,a)和v(s)之间的关系
现在我们知道了这些函数之间的关系,我们可以将方程式16中的v(s)插入方程式17中的q(s,a)。 我们得到方程18,可以注意到当前q(s,a)和下一个动作值q(s',a')之间存在递归关系。
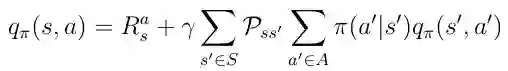
等式18 动作-价值函数的递归性质
这种递归关系可以再次在二叉树中可视化(图10)。 我们从q(s,a)开始,以一定的概率Pss'结束于下一个状态s'从那里我们可以用概率 π 采取行动 a' 并且我们以动作值 q 结束(s', 一个')。 为了获得q(s,a),我们必须在树中上升并整合所有概率,如在 等式 18中可以看到的那样。
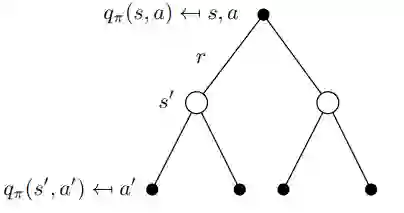
图10 q(s,a)的递归行为的可视化
3.5 最优策略
深度强化学习中最重要的主题是找到最优的动作 - 价值函数q *。 查找q *表示主体确切地知道任何给定状态下的动作的质量。 此外,主体可以决定必须采取哪种行动的质量。 让我们定义q *的意思。 最佳的动作值函数是遵循最大化动作值的策略的功能:
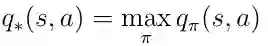
等式19 最佳动作值函数的定义
为了找到最好的策略,我们必须在 q(s,a)上最大化。 最大化意味着我们只从所有可能的动作中选择动作a,其中q(s,a)具有最高值。 这为最优策略 π 产生以下定义:
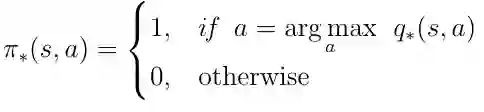
等式20 最优政策,采取最大化 q(s,a)的行动。
3.6 Bellman最优性方程
可以将最优策略的条件插入到方程18中。这样就为我们提供了Bellman最优性方程:
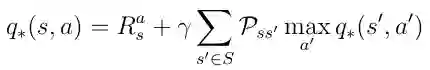
等式21 Bellman最优性方程
如果AI主体可以解决这个等式,那么它基本上意味着解决了给定环境中的问题。 主体在任何给定的状态或情况下都知道关于目标的任何可能行动的质量并且可以相应地表现。
想要继续查看该篇文章相关链接和参考文献?
戳链接或点击底部【阅读原文】:
http://ai.yanxishe.com/page/TextTranslation/1137
AI研习社每日更新精彩内容,观看更多精彩内容:
使用 SKIL 和 YOLO 构建产品级目标检测系统
AI课程/书籍/视频讲座/论文精选大列表
Excel 还能这样玩?轻松搞懂一维 & 三维卷积神经网络
数据科学家应当了解的五个统计基本概念:统计特征、概率分布、降维、过采样/欠采样、贝叶斯统计
等你来译:


