个人思考 | 关于推荐模型的四种模式

一 、Wide&Deep
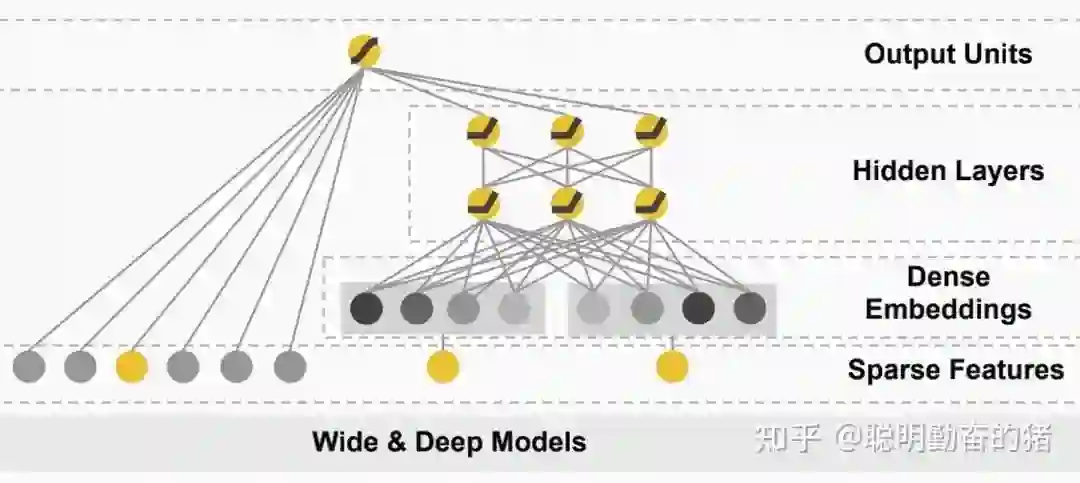
Wide&Deep 作为独立模式的一种,其由 LR(Wide部分)和 MLP(Deep部分)组成,LR负责学习显式的特征(内含部分人工交叉特征),MLP 负责学习隐式的特征关联。两个模块配合,效果更上一层楼。为什么是独立模式呢?因为我们将其拆开,自模块 LR 和 MLP 都可以独立完成点击率预估这个任务,两者互不影响。关于 LR 和 MLP 的介绍见:由Logistic Regression所联想到的...
Wide & Deep Learning for Recommender Systems (2016) Heng-Tze Cheng et al.
二、DeepFM
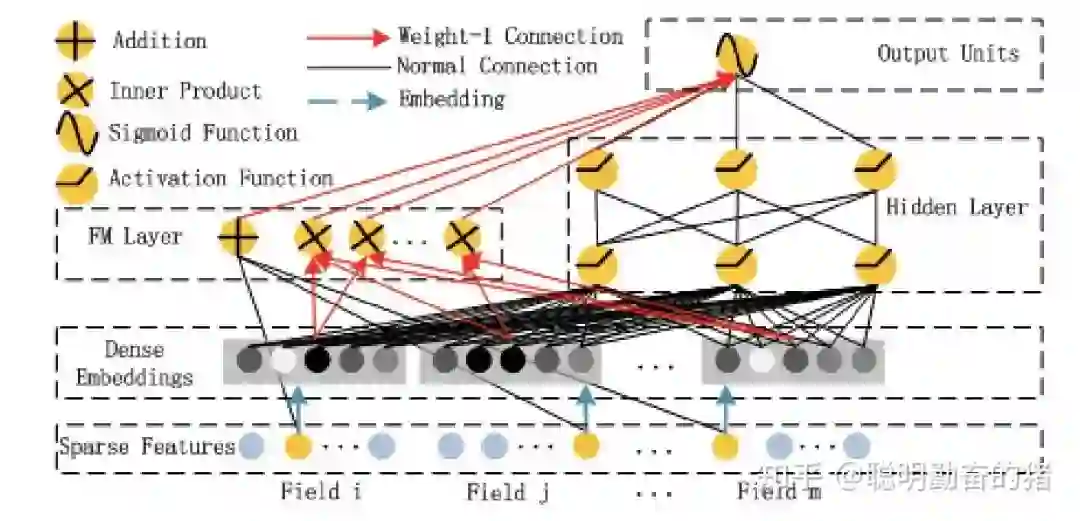
论特征的交叉能力,FM 肯定比 LR 更有话语权,所以自然而然 Wide 部分 LR 被 FM 替换后,效果有了进一步的提升,摇身一变成为 DeepFM。关于 FM 的介绍见推荐系统之FM与MF傻傻分不清楚。
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction (2017) HuiFeng Guo et al.
三、DCN 和 DCNV2
关于交叉特征的建模,FM并不是天花板。谷歌出了一篇 Deep & Cross Network (DCN)更好地建模任意高阶(二阶,三阶,四阶...)交叉特征,当然构建更高阶的特征意味着更大的硬件成本。干这件事的主要就是Cross network了。Cross network其实就是MLP,不过这个MLP每一层的神经元个数都相同,只是为了更好的交叉。每一层等于上一层加上上一层和第一层的交叉,这样就可以通过层数来控制交叉特征阶数。一般取2或3效果应该就挖掘得差不多了,更高阶的特征交叉极大概率和已有的低阶特征冗余,所带来的边际效益逐渐递减,而带来的硬件成本倍增。所以,为了权衡成本和收益,DCN并不可能发挥充分。不过DCN给我们启发还是蛮大的。
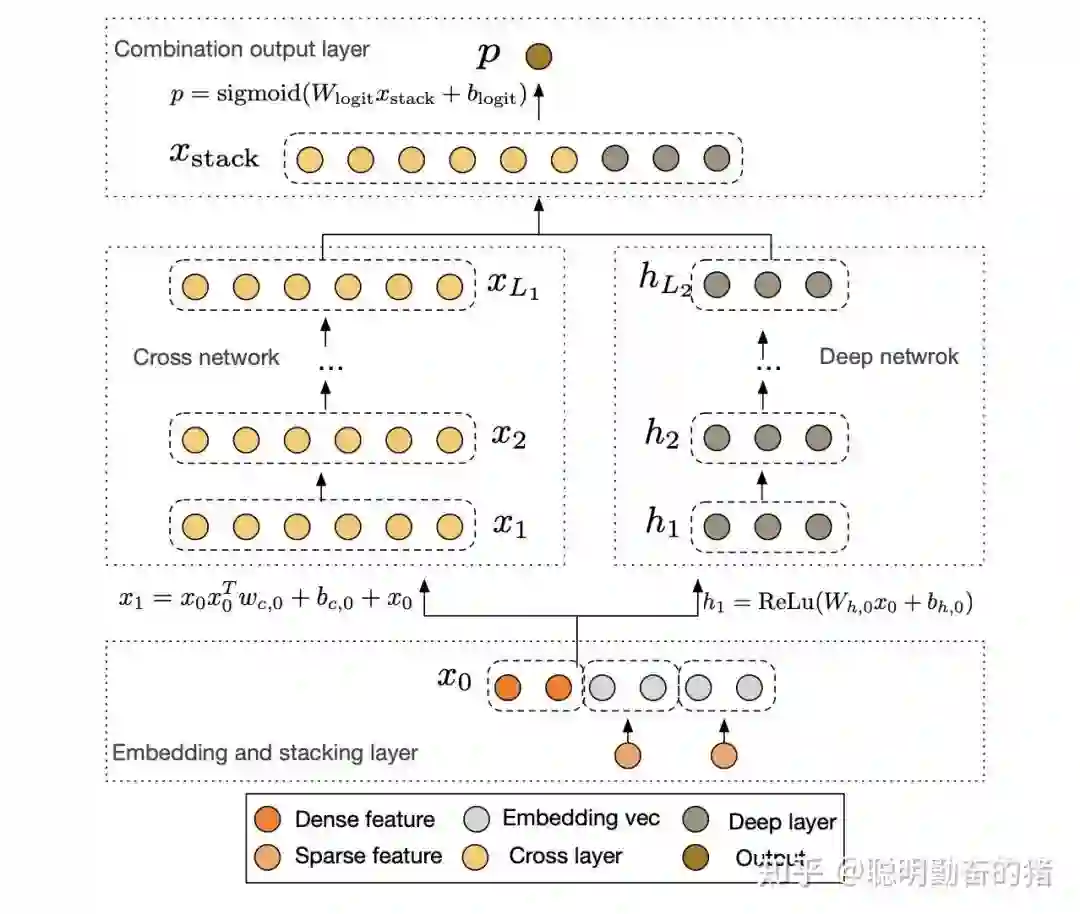
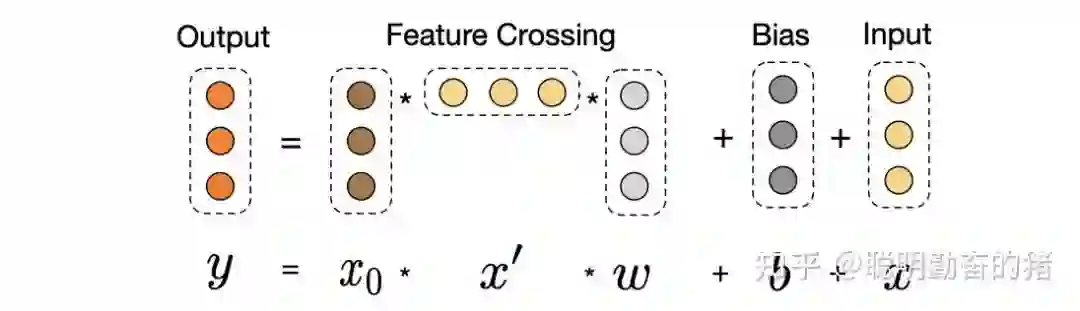
如果你认为 DCN 是交叉特征的天花板了,那谷歌真的是神了。DCN V2版本紧接着问世,直接捅破天花板最后一层板。和DCN不同之处在于交叉网络的权重由一个vector变为矩阵。这样的话,参数量加倍了,表达能力也变强了,不过线上耗时也增加了。耗时增加在于引入了权重矩阵,谷歌不会善罢甘休,发现权重矩阵的低秩性,于是就有将权重矩阵分解为两个低维矩阵的想法,这和 FM 中Cholesky分解有异曲同工之妙。
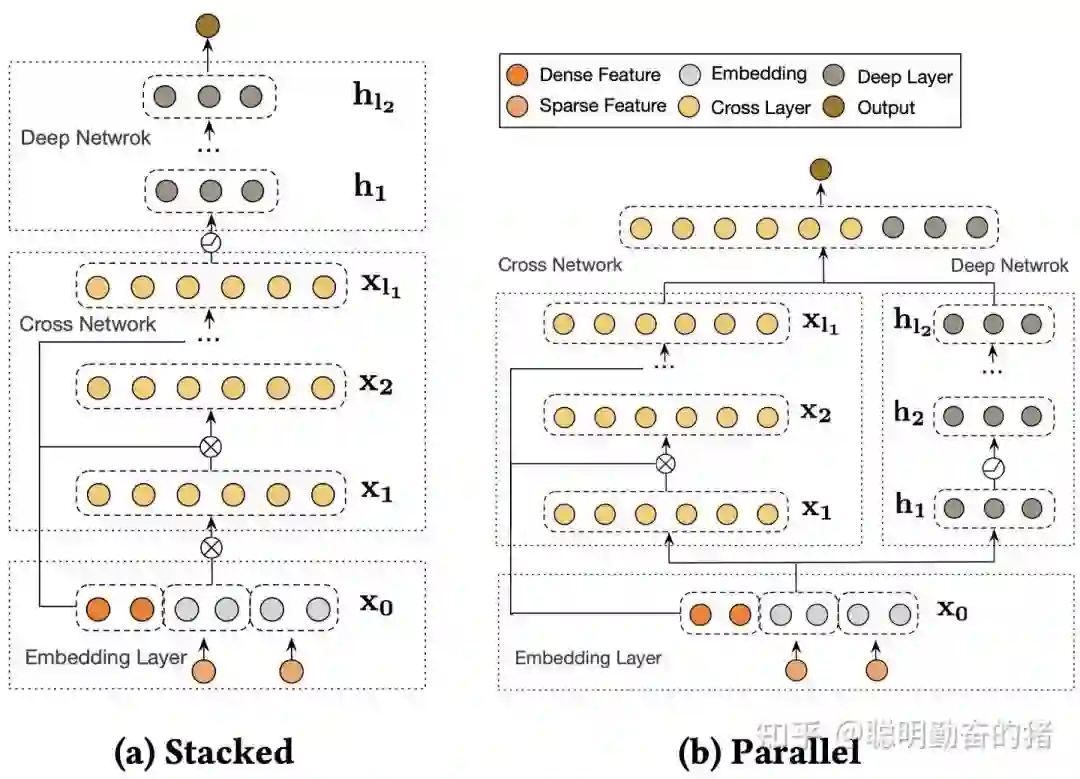
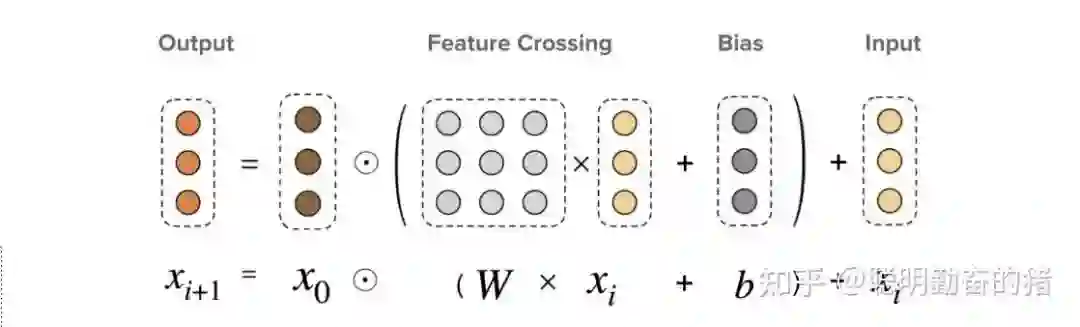
1. Deep & Cross Network for Ad Click Predictions(2017)Ruoxi Wang et al.
2. DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems (2020) Ruoxi Wang et al.
四、联邦学习
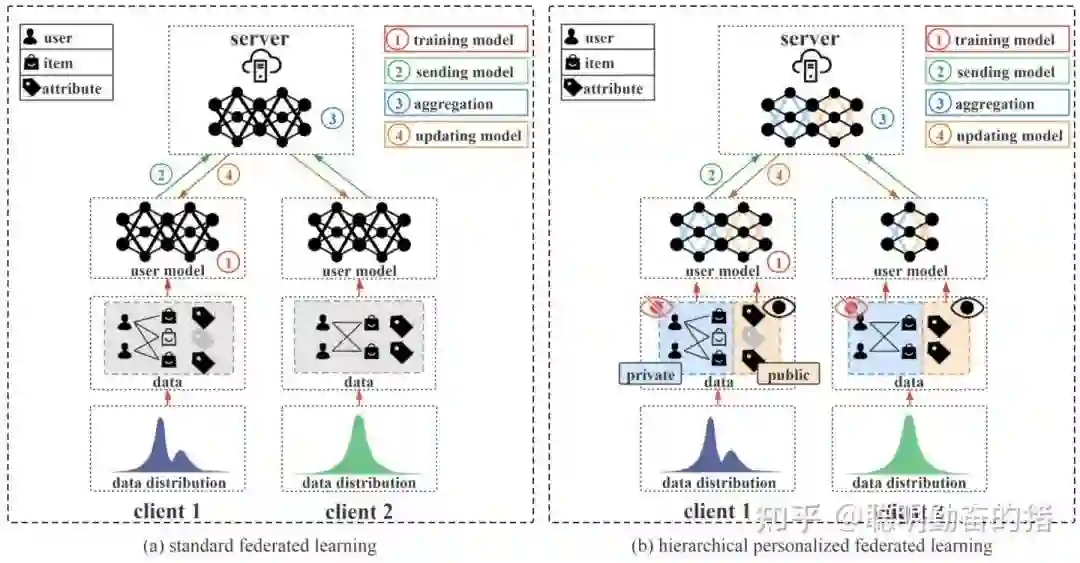
所以联邦学习通过将用户数据保存在本地,然后利用本地数据训练本地模型,然后在服务端协同多个本地模型进行优化,进而聚合多个本地模型的中间参数来得到服务端全局较优的模型,最终下发到每个终端设备上。因此联邦学习实现了模型出域,用户的本地数据不出域的目的,最终达到保护用户原始数据以及隐私的需求。引用知友 @张小磊 一文梳理联邦学习推荐系统研究进展
这样来看,每个公司自己的数据和模型相当于子模块,各个子模块可以完成本公司的推荐业务,彼此互不影响,属于独立模式。
1. Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System. arxiv, 2019.
2. FedFast Going Beyond Average for Faster Training of Federated Recommender Systems. KDD, 2020.
3. Meta Matrix Factorization for Federated Rating Predictions. SIGIR, 2020.
五、知识蒸馏
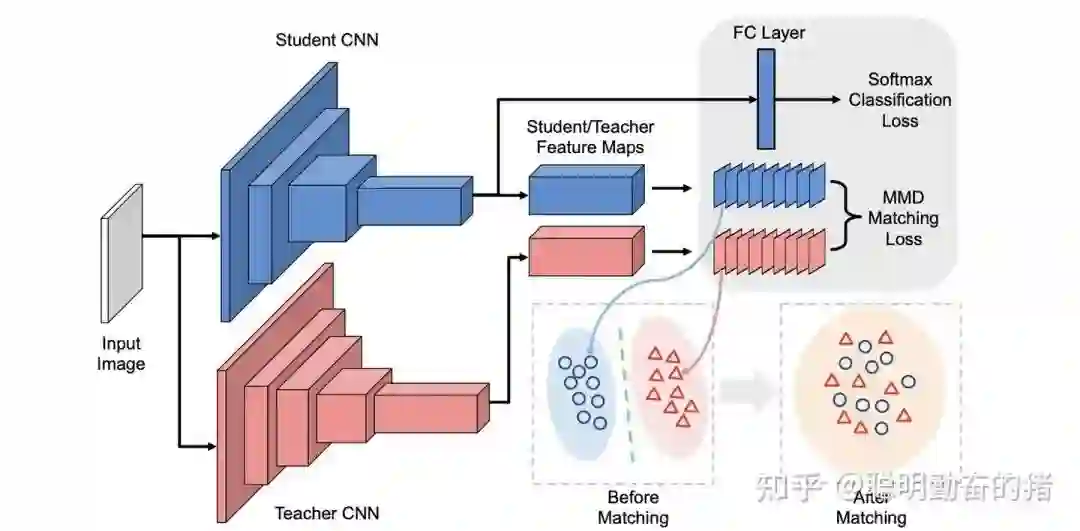
知识蒸馏算是指导模式的典型代表,也是分而治之的思想。其子模块包含两部分:“教师网络”和“学生网络”,关系是教师网络指导学生网络进行学习,而学生不影响教师网络的更新,属于单向影响。那么蒸馏能work的前提是,教师网络是比学生网络更复杂,表达能力更强的网络。关于蒸馏模型的理论很火,但在业界貌似风评不好,很少效果比较好的。其原因可能跟使用条件苛刻,实地业务场景复杂有很大关系。
1. Distilling the Knowledge in a Neural Network (2017)Zehao Huang
2. Rocket Launching: A Universal and Efficient Framework for Training Well-Performing Light Net 2018 Alibaba
六、DSSM双塔
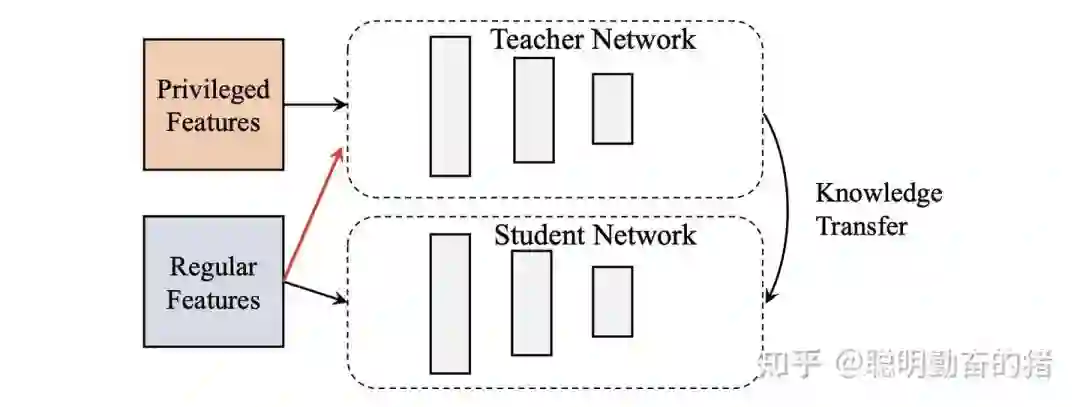
DSSM双塔模型常用于召回或粗排,其将特征划分为用户相关特征和项目相关特征分别处理。即一个MLP塔建模用户相关特征,另一个MLP塔建模项目相关特征,然后对各自学到的用户Embedding和项目Embedding求内积得到预估值。两个子模块缺一不可,共同完成预估任务,属于联合模式。比较有趣的是,由于本人涉及粗排业务,DSSM双塔的优势是可以离线存储大量项目的embedding,在线redis直接读取,节约大量时间,但是带来的是效果的损失。其原因主要是该架构不能使用交叉特征,且用户项目embedding交互较晚。所以就有用蒸馏模型来优化DSSM双塔的想法,找一个强劲的教师网络来指导双塔网络学习,理论上既保证了耗时低的优势,也提升了效果,两全其美,其结构主要如下(Taobao出品):
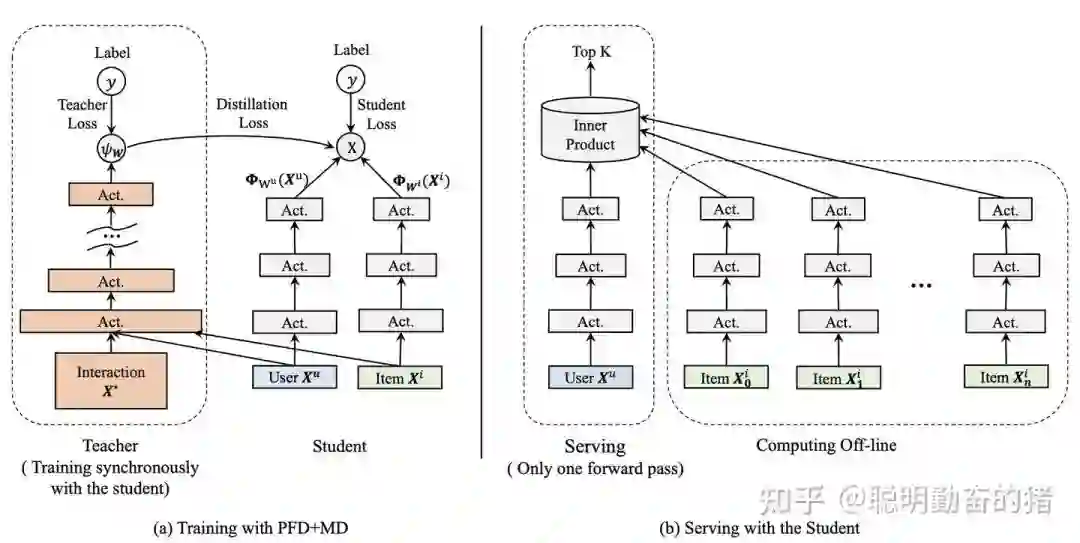
1. Privileged Features Distillation at Taobao Recommendations(2020) 2. Learning Deep Structured Semantic Models for Web Search using Clickthrough Data (2013)Microsoft
七、ESMM多目标
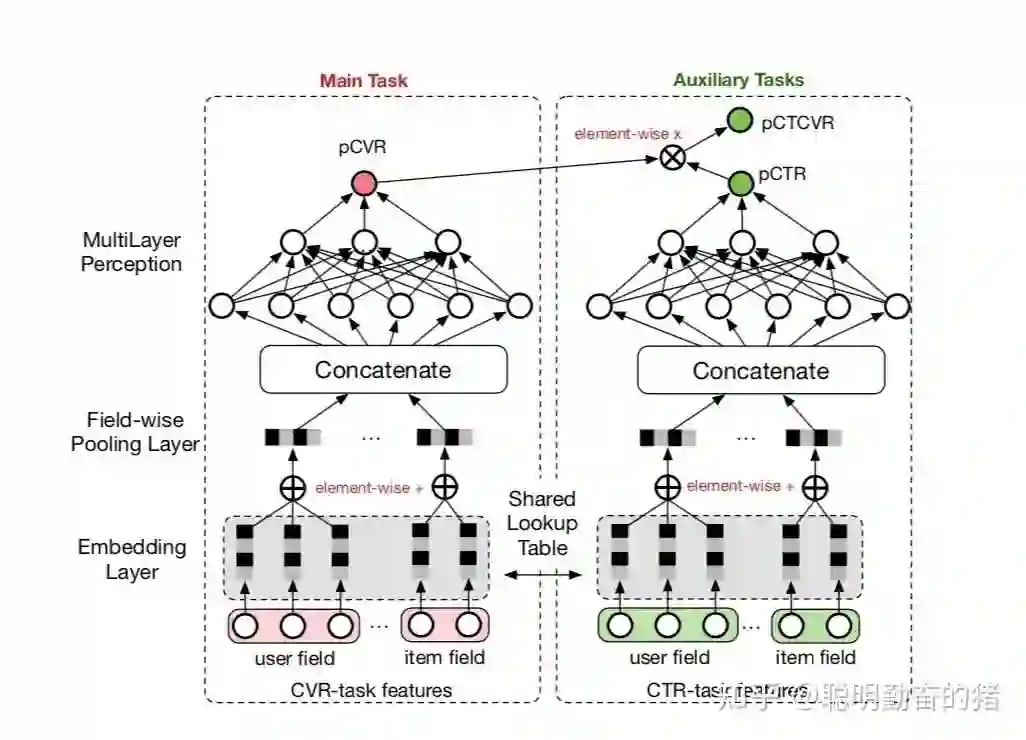
广告推荐业务中涉及的一个最常见的多目标问题:点击率(ctr)和转化率(cvr)双目标。因此分而治之的思想很明确了,一个网络建模 ctr,一个网络建模 cvr。最后对于两个网络的输出进行整合。ESMM认为转化发生在点击的基础上,即点击是转化的充分必要条件。因此构建了新的预估值用于辅助任务。由于是处理多任务,各个单一任务子模块需要联合努力,因此ESSM属于联合模式。
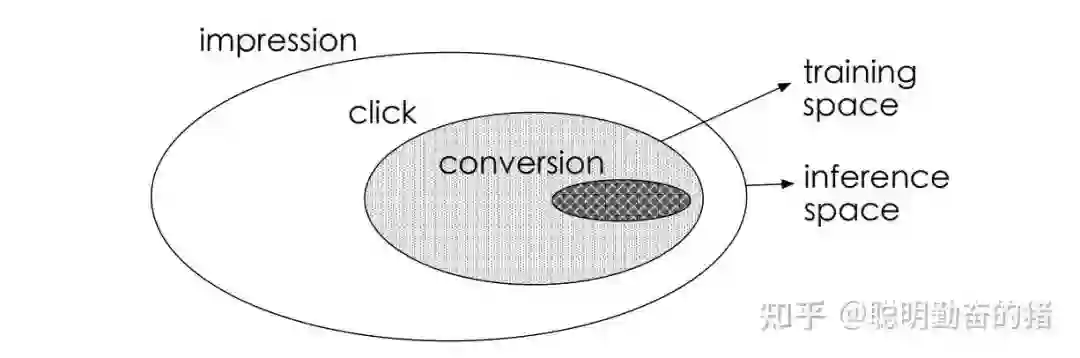
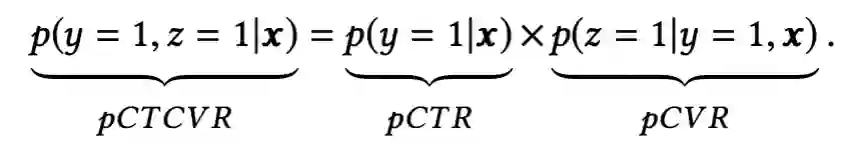
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate (2018)Alibaba
八、对比学习
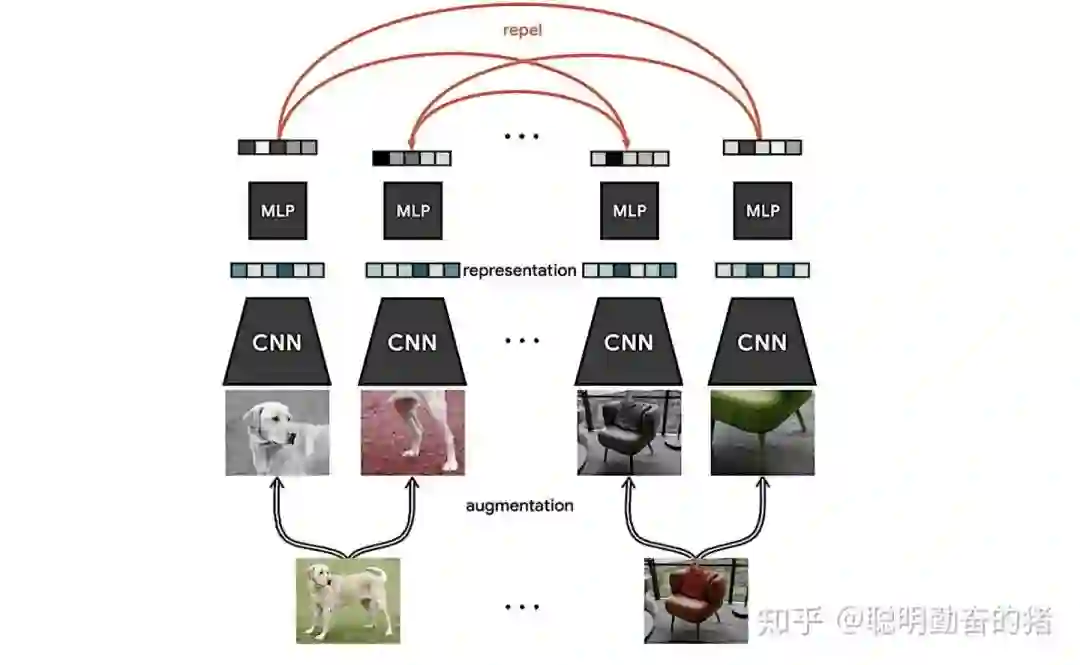
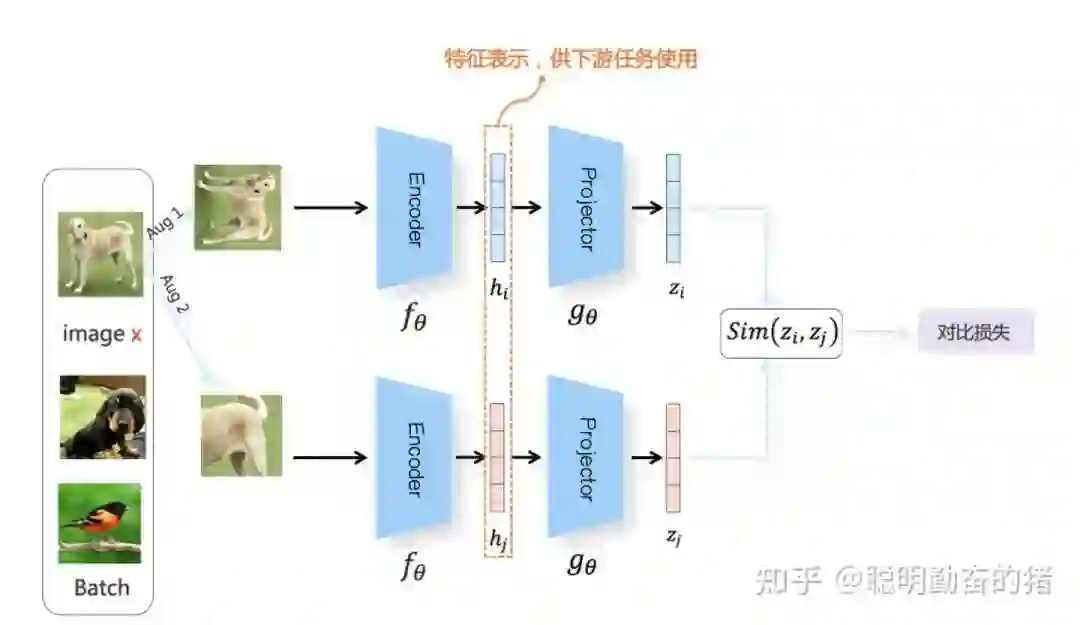
最后一项是压轴戏:对比学习。对比学习常用于预训练过程,目的是得到一个优秀的 embedding 表示器用于下游任务。为什么需要embedding,input层的维度太高太稀疏,直接灌入DNN硬件吃不消,因此需要一个更加稠密的向量表示来近似表示原输入,这个稠密的向量我们称做embedding 嵌入表示。试想,如果embedding向量能够尽可能准确表示原始输入,那么损失的特征信息就更少,训练模型效果也会更好。一般而言,预训练数据是无标记样本,没有label如何训练呢?对比学习通过两个不同视角强化样本,得到来自同一个样本的不同变体。如上面图例,通过裁剪,黑白等数据增强手段可以得到不同的照片,但我们知道这两张照片无论有多么不同都表示同一条狗。因此对比学习的损失第一部分就是要保证不同视角的两张图片(正例)的embedding 是相近的。那另外一部分呢,就是和其他照片(即负例)的embedding要保证低相似度。注意,不同视角的正例和负例过的都是同一个网络,属于共享模式。
1. A Simple Framework for Contrastive Learning of Visual Representations(2020)
2. Momentum Contrast for Unsupervised Visual Representation Learning (2020)
总结思考
以上模型涉及不同的方向,干不一样的事。但都可以归纳为以上四种模式:独立模式,指导模式,联合模式和共享模式,无不体现着“分而治之”的思想。所以除了挤破头皮去想一个牛x的单模型,不如朝着“分而治之”的角度去思考思考目前遇到的问题,说不定能出大作。以上所有内容属个人学习启发,如有理解不对欢迎指正。

