一种可用于目标检测的Backbone搜索

转载自:学术头条(ID:SciTouTiao)
作者:Liyang
前言
本文将对NeurIPS 会议论文《DetNAS: Backbone Search for Object Detection》进行解读,这篇论文在目标检测领域的神经网络架构搜索(Neural Architecture Search,NAS)方面有所创新。基于one-shot supernet技术,作者提出了一种用于目标检测网络backbone搜索的框架DetNAS。按照典型的检测器训练步骤来训练网络,包括ImageNet预训练和检测器微调。然后,以检测任务为指导,在经过训练的supernet上执行体系架构搜索。实验结果表明,DetNAS在one-stage的RetinaNet和two-stage的FPN等检测器上的效果较好。
DetNAS: Backbone Search for Object Detection
论文地址:
https://arxiv.org/abs/1903.10979
开源地址:
https://github.com/megvii-model/DetNAS
论文作者:Yukang Chen, Tong Yang, Xiangyu Zhang, Gaofeng Meng, Xinyu Xiao, Jian Sun(中国科学院自动化研究所,Megvii旷视科技)
研究现状
1.目标检测 (Object Detection)
随着深度卷积网络的飞速发展,目标检测器已经在效果上取得了很大进步。目标检测器通常包含backbone网络和“head”两部分。 在过去几年,目标检测的许多进步来自“head”的研究,如体系架构,loss和anchor。FPN 【1】发展了一种具有横向连接的自顶向下架构,用于在所有尺度上构建高级语义特征图,从而成为有效的特征提取器。RetinaNet提出了focal loss 【2】来解决类别不平衡的问题,但这会导致早期训练的不稳定。MetaAnchor【3】提出了一种动态anchor生成机制来提高基于anchor的目标检测器的性能。
Backbone在目标检测中非常重要,目标检测器的性能高度依赖于backbone提取的特征。许多目标检测器直接使用为图像分类而设计的网络作为backbone,但这并非最佳选择,因为图像分类专注于图像分类,而目标检测要兼顾每个目标的位置和分类。如ResNet-101在ImageNet分类上的性能优于DetNet-59 【4】,但在目标检测方面不如后者。
2.神经网络架构搜索(Neural Architecture Search)
用于图像分类的NAS技术引起了越来越多的关注。NAS 【5】和NASNet 【6】使用强化学习(RL)顺序确定神经体系架构。此外, AmeobaNet 【7】证明,没有任何控制器的基本进化算法(EA)也可以达到较好的结果,甚至可以超越基于RL的方法。为了节省计算资源,一些研究者提出使用权重共享或单次使用的方法,如ENAS 【8】和DARTS 【9】。SNAS 【10】,Proxyless 【11】等,在某种程度上也属于one-shot NAS。除图像分类外,NAS在语义分割等方面也得到了很好的应用。
在图像分类【12】上,搜索到的网络可能达到甚至超过hand-crafted网络的性能。然而,用于目标检测器中backbone的NAS仍然具有挑战性。典型的检测器训练要求在ImageNet上对backbone网络进行预训练,这会带来两个问题:(1)难以优化:NAS不能用预训练网络的精度来作为监督信号;(2)效率低下:需要首先对每个候选架构进行预训练(例如在ImageNet上),然后在测试数据集上进行微调,成本太高。
即使不进行预训练(train from scratch)是一种替代方法【13】,但它也需要更多的训练迭代来弥补预训练的不足。
方法
1.概述
受one-shot NAS方法【14】的启发,作者通过将权重训练与架构搜索解耦来解决此问题。以前的大多数NAS方法都以嵌套方式优化权重和体系架构。作者认为只有将它们分解为两个阶段,才能有效地合并预训练步骤。该框架避免了由预训练引起的效率低下的问题,并使backbone搜索变得可行。如下图所示,DetNAS的框架包括三个步骤:
(1)在ImageNet上预训练one-shot supernet;
(2)在测试数据集上微调one-shot supernet;
(3)使用进化算法(EA)在经过训练的supernet上进行体系架构搜索。
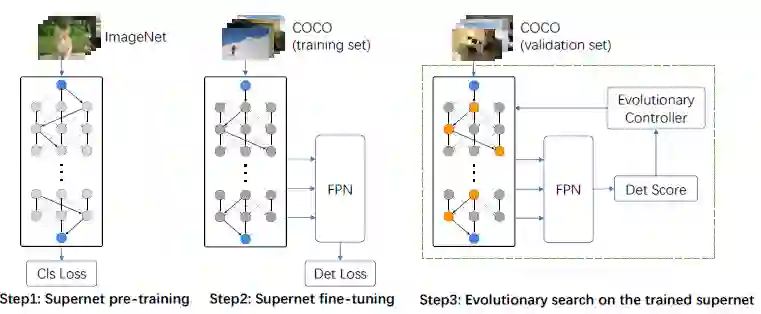
如上图所示,使用进化算法在经过训练的supernet上搜索架构, 验证集实际上是从COCO trainval35k中分离出来的,包含5k张图像。
2.Motivation
一般情况下,架构搜索空间A可以由有向无环图(DAG)表示。图中的任何路径都对应一个特定的体系架构a∈A。对于特定的体系架构,其对应的网络可以表示为N(α,ω),网络权重为ω。NAS旨在找到使验证损失L_val (N(α*,ω* )) 最小的最佳架构。ω*表示架构α*的最佳网络权重。它是通过最小化训练损失而获得的。可将NAS流程表述为嵌套优化问题:
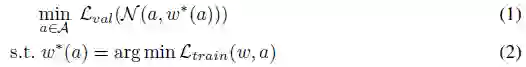
上述公式可以表示在没有预先训练(例如图像分类)的情况下的NAS。但对于目标检测,需要预训练和微调,等式(2)需要变为:
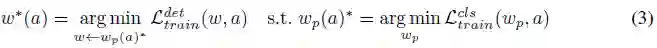
其中, ω←(ω_p (α))* 表示将ω_p (α)*作为初始化来优化ω。预训练权重ω_p (α)*并不能直接用于公式(1),但对 ω(α)*是必要的。因此,不能跳过DetNAS中的ImageNet预训练。在one-shot NAS方法中,搜索空间被编码在由所有候选架构组成的supernet中,它们在其公共节点中共享权重。因此,公式(1)和公式(2)变为:
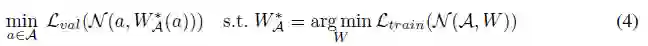
其中所有单独的网络权重ω(α)都从one-shot supernet W_A 继承。supernet训练,W_A优化与体系架构α优化相分离。基于这一点,进一步采取预训练,使NAS可以执行更复杂的任务,即目标检测中的backbone搜索:
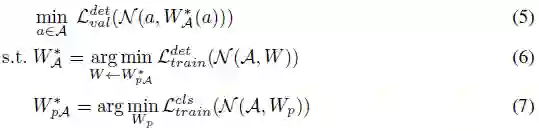
3.NAS Pipeline
Step 1: Supernet预训练
在一些one-shot方法中,它们将实际上离散的搜索空间变换为一个连续空间,这样会导致搜索空间中各个网络的权重耦合严重。在supernet的预训练过程中,作者采用path-wise方案,从而确保了预训练的supernet能够反映候选网络的相关性能。在每次迭代中,只有一条路径会前向或反向传播,其他路径或节点的梯度与权重都不会进行更新。
Step2: Supernet微调
Supernet微调也是以path-wise方式进行,再加上检测head,指标和数据集。另一个需要提及的细节是batch normalization(BN)。通常,在微调过程中BN参数固定为预训练前的batch统计信息。然而,在DetNAS中不同路径上要归一化的features并不相同。另外,与图像分类不同,目标检测器使用高分辨率图像训练,受显存的限制,会严重降低BN的精度。为此,作者在supernet训练过程中使用Synchronized Batch Normalization(SyncBN))作为替代BN。SyncBN可以跨多个GPU上计算批统计信息,增加有效batch的大小。
Step3:使用EA在supernet上搜索
Supernet上用进化算法进行架构搜索。搜索时,不同的子网络会在supernet中进行path-wise采样。由于各个路径上的batch统计相对独立。因此,在评估前,需要重新统计每条路径上的batch信息。作者从训练集抽取出一个小部分子集来重新计算需评估的单条路径的batch统计信息。此步骤仅为BN累计合理的running mean与running variance,并不涉及梯度反向传播。
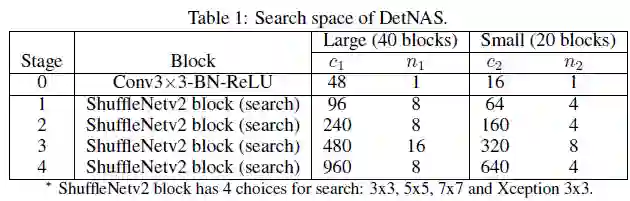
4.空间搜索设计
如下图所示为DetNASNet的架构。表1中描述了有关搜索空间的详细信息。搜索空间基于ShuffleNetv2,作者设计了两个不同大小的搜索空间,其中大搜索空间用于主要结果,小搜索空间用于消融研究。
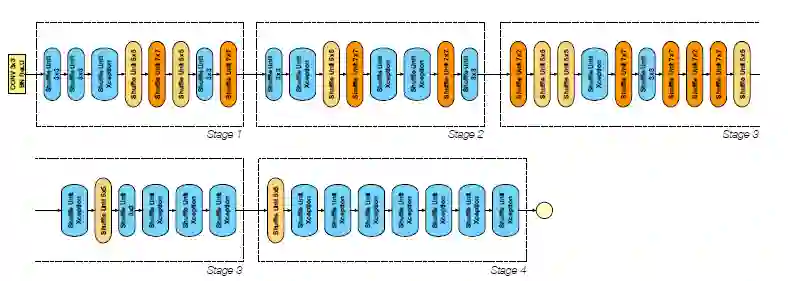
大搜索空间(Large, 40个块)
目的是将主要结果与hand-crafted的backbone比较。每个阶段中的通道和块由c_1和n_1指定。在每个阶段中,第一个块的stride为2进行采样。除第一阶段外,还有4个阶段,共有40个要搜索的块。对于每个要搜索的块,从原始ShuffleNetv2块开始有4个选择:用{3×3 ,5×5 ,7×7}更改kernel大小,或用Xception块替换右分支(三个重复的可分离深度3×3卷积)。该搜索空间包括4^40≈1.2×10^24个候选架构。大部分网络计算量超过1G FLOPs。
小搜索空间(Small, 20个块)
块数 n_1是n_2的两倍。在所有搜索阶段中,通道数c_1是c_2的1.5倍。该搜索空间包括4^20≈1.0×10^12 个候选架构。大多数网络有大约300M FLOPs。
5.搜索算法
与基于RL和梯度的NAS方法相比,进化算法能够很好地满足约束条件(如FLOPs或推理速度)。为了优化FLOPs或推理速度,基于RL的方法需要对反馈函数精细调参。而基于梯度的方法则需要对损失函数精细调参。尽管如此,其输出结果仍然很难全部满足约束条件。为此,DetNAS选择使用进化搜索算法。
首先随机初始化一组网络P,每个网络由其架构P.θ以及其适应度P.f组成。任何违反约束η的架构将会被删除,并选择替代方案。初始化后,作者开始评估各个体系架构,以在验证集上获得其适应度P.f。在这些评估的网络中,作者选择最佳的个架构作为parents以生成child网络。接下来,第二代网络由parents在约束η下变异(mutation)和组合交叉(crossover)所得到。通过在迭代过程中重复此操作,可以找到一条验证集上性能最好的路径。
实验
1.主要结果
DetNASNet在Large空间中的FPN上进行搜索。如下表所示主要结果。作者列出了三个hand-crafted网络进行比较,包括ResNet-50,ResNet-101和ShuffleNetv2-40。DetNASNet仅1.3G FLOPs即可实现40.2%的mAP,优于ResNet-50和 ResNet-101。
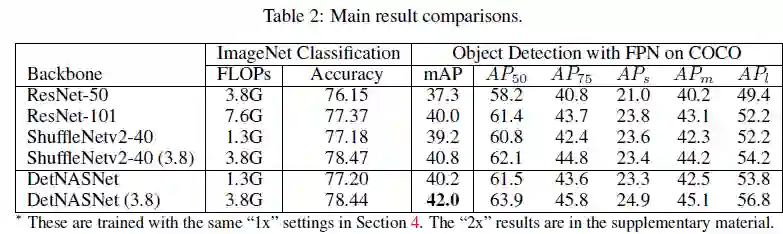
为了消除搜索空间的影响,与 ShuffleNetv2-40(搜索空间的baseline)对比。结果显示,ShuffleNetv2-40在COCO上比DetNAS的mmAP分数低了0.8%。说明DetNAS的效果并未受到搜索空间的影响。
之后,考虑了搜索空间的影响,并将DetNASNet的通道增加了1.8倍,达到3.8G FLOPs即DetNASNet(3.8),达到了42.0%的mmAP,超过ResNet-50 4.7%和ResNet-101 2.0%。
2.消融实验
在FPN和RetinaNet检测器上,DetNAS在COCO中的表现都比ShuffleNetv2-20高出1%左右。这表明NAS在目标检测中也可以实现比hand-crafted网络更好的性能。
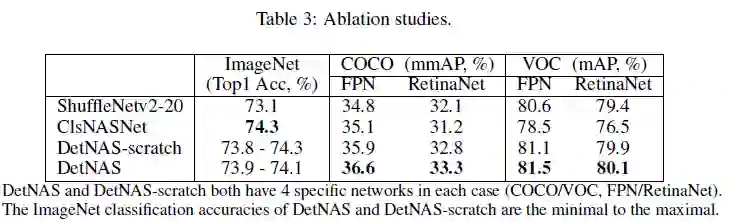
ClsNASNet是ImageNet分类中的最佳搜索框架。搜索方法和搜索空间遵循DetNAS。作者将其用作目标检测器的backbone。如上表所示,DetNAS在目标检测上明显优于ClsNASNet。
在各种数据集上,DetNAS的性能都要比DetNAS-stratch(无预训练)好,这反映了DetNAS预训练的重要性。
总结
本文提出第一个用于目标检测任务backbone搜索的框架—DetNAS,该方法包括三个步骤:在ImageNet上预训练Supernet;在测试测数据集上微调Supernet;用EA算法搜索。实验结果显示,DetNAS的搜索性能在COCO上超越了ShuffleNet和ResNet等传统hand-crafted网络架构。
参考文献
【1】Tsung-Yi Lin, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan, and Serge J.Belongie. Feature pyramid networks for object detection. In CVPR, pages 936–944, 2017
【2】Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV, pages 2999–3007, 2017
【3】Tong Yang, Xiangyu Zhang, Zeming Li, Wenqiang Zhang, and Jian Sun. Metaanchor: Learning to detect objects with customized anchors. In NIPS, pages 318–328, 2018
【4】Zeming Li, Chao Peng, Gang Yu, Xiangyu Zhang, Yangdong Deng, and Jian Sun. Detnet: Design backbone for object detection. In ECCV, pages 339–354
【5】Barret Zoph and Quoc V. Le. Neural architecture search with reinforcement learning. CoRR, abs/1611.01578, 2016
【6】Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. Learning transferable architectures for scalable image recognition. pages 8697–8710, 2018
【7】Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V. Le. Regularized evolution for image classifier architecture search. CoRR, abs/1802.01548, 2018
【8】Hieu Pham, Melody Y. Guan, Barret Zoph, Quoc V. Le, and Jeff Dean. Efficient neural architecture search via parameter sharing. In ICML, pages 4092–4101, 2018
【9】Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: differentiable architecture search.ICLR, abs/1806.09055, 2019
【10】Sirui Xie, Hehui Zheng, Chunxiao Liu, and Liang Lin. SNAS: stochastic neural architecture search. ICLR, abs/1812.09926, 2019
【11】Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware. ICLR, abs/1812.00332, 2019
【12】Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. Learning transferable architectures for scalable image recognition. pages 8697–8710, 2018
【13】Kaiming He, Ross Girshick, and Piotr Dollár. Rethinking imagenet pre-training. page abs/1811.08883, 2019
【14】Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, and Jian Sun. Single path one-shot neural architecture search with uniform sampling. abs/1904.00420, 2019
——END——





