CNN可视化最新研究方法进展(附结构、算法)

译者 | reason_W
责编 | 明 明
出品 | AI科技大本营(公众号ID:rgznai100)
【AI科技大本营导读】深度学习一直被看做是一个难以解释的“黑匣子”。一方面在于其缺乏数学上的优雅,缺乏基础理论的支撑,另一方面在工程上缺乏解释性,其潜在的安全隐患一直为人们所诟病。因此,如何更好地对 CNN 进行可视化理解一直是学术界和工业界关注的重点。本文为 CNN 可视化理解的最新综述,AI科技大本营将重点内容摘选如下。
目前,学术界已经提出了很多和 CNN 可视化相关的工作,在早期的研究阶段,可视化主要集中在低层特征。 随着 CNN 的快速发展和实施,可视化已经扩展到解释 CNN 的整体工作机制。这些工作主要是从网络结构,算法实施和语义概念的角度来对其进行解释。这其中几种代表性的方法有:
1、Erhan 等人提出 Activation Maximization 来对传统的浅层网络进行解释。后来,Simonyan 等人通过将单个 CNN 神经元的最大激活可视化合成一个输入图像模式( input image pattern ),进一步改进了这种方法。后续出现了很多工作都是基于这种方法,再利用不同的正则项进行扩展,以提高合成图像模式的可解释性。
2、Mahendran 等人提出了 Network Inversion 重建基于多个神经元激活的输入图像,以此说明每个 CNN 层学习到的综合特征图,揭示了 CNN 网络在网络层层面的内部特征。Network Inversion 根据特定层的特征图中的原始图像重建输入图像,这可以揭示该图层所保存的图像信息。
3、没有选择对输入图像进行重建以实现特征可视化,Zeiler 等人提出了基于反卷积神经网络的可视化方法(Deconvolutional Neural Network based Visualization, DeconvNet),该方法利用 DeconvNet 框架将特征图直接映射到图像维度,利用反卷积 CNN 结构(由反卷积层和反卷积层组成)在特定神经元激活的原始输入图像中查找图像模式。通过直接映射, DeconvNet 可以突出显示输入图像中的哪些模式激活特定神经元,从而直接链接神经元和输入数据的含义。
4、周博磊等人提出了 Network Dissection based Visualization,它从语义层面对 CNN 进行了解释。通过引用异构图像数据集——Borden,Network Dissection 可以有效地将输入图像分割为多个具有各种语义定义的部分,可以匹配六种语义概念(例如场景,目标,部件,材质,纹理和颜色)。由于语义直接代表了特征的含义,神经元的可解释性可以显著提高。
下面,我们将详细对这四种代表性的方法进行介绍。
▌通过 Activation Maximization 进行可视化
Activation Maximization(AM)的提出是为了可视化每层神经网络中的神经元的首选输入。首选输入可以指示神经元已经学习到的特征。这些学到的特征将由一个可以引起神经元激活最大化的综合输入模式表示。为了合成这样的输入模式,CNN 输入的每个像素都将被迭代地改变以最大化神经元的激活。
AM 背后的想法很直观,其基本的算法也早在 2009 年就已经被 Erhan 等人提了出来。他们将 Deep Belief Net 中隐藏神经元的首选输入模式和 MNIST 数字数据集中学习到的 Stacked Denoising Auto-Encoder 进行了可视化。
后来,Simonyan 等人利用这种方法最大化了输出层 CNN 神经元的激活。 Google也为他们的 Inception Network 合成了类似的可视化模式。 Yosinksi 等人进一步将 AM 用于大规模应用,可以将 CNN 各层的任意神经元可视化。 最近,很多优化工作都在这个想法的基础上开展,以提高可视化模式的可解释性和多样性。 通过所有这些工作,AM 已经显示出很好的解释神经元首选性的能力,并确定了 CNN 学到的层次特征。
输入层网络可视化
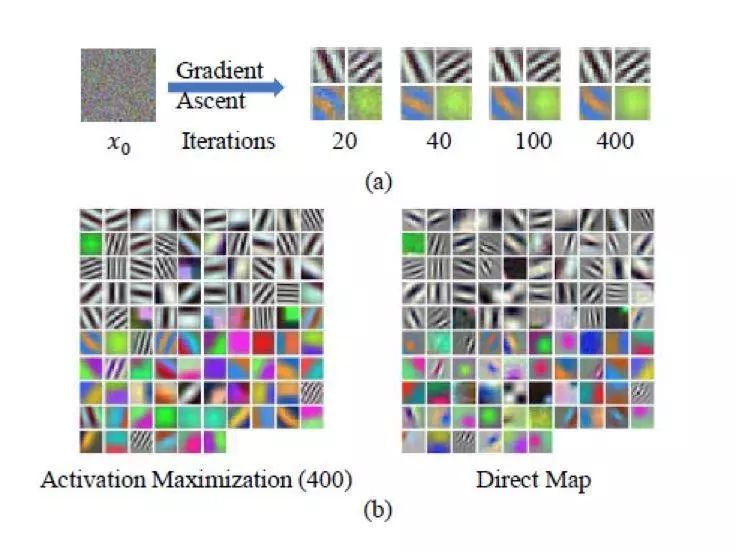
通过 AM 对 CaffeNet 的输入层网络进行可视化
(a)图显示了四个不同神经元合成的不同模式的可视化结果;
(b)图显示了通过 AM 和直接映射方法合成的可视化模式。正如我们所看到的,大多数由 AM 合成的可视化模式与相应的直接映射模式几乎相同。
可视化的模式可以分为两组:
1)彩色模式代表对应的神经元对待测图像中的颜色分量非常敏感;
2)黑白模式指代表该部分神经元对形状信息非常敏感。
另外,通过与直接映射方法的比较,AM 可以准确地揭示每个神经元的首选输入。
这一有趣的发现揭示了 CNN 试图模仿人类视觉皮层系统的机制,即底层视觉区域中的神经元对基本模式(如颜色,边缘和线条)更敏感。
隐藏层网络可视化

通过 AM 对 CaffeNet 的隐藏层网络进行可视化
从图中我们可以看到,每行中从第二卷积层(CL 2)到第二全连接层(FL 2)的 6 个隐藏层的可视化。我们随机选取了每层中的几个神经元作为我们的 AM 测试目标。可以观察到:
1)一些重要的模式是可见的,例如边缘(CL2-4),脸部(CL4-1),轮子(CL4-2),瓶子(CL5-1),眼睛(CL5 -2)等,它们展示了神经元学习到的丰富特征。
2)同时,即使应用了多种正则化方法,也并非所有的可视化模式都是可解释的。
3)可视化模式的复杂性和变化从低层到高层逐渐增加,这表明神经元学习到了越来越多的不变特征。
4)从 CL 5 到 FL,我们可以发现有一个较大的模式变化增量,这可能表明 FL 层对特征有更全面的评估能力。
输出层网络可视化

通过 AM 对 CaffeNet 的输出层网络进行可视化
上图展示了 AM 和 DGNAM 对五种物品在 FL3 中合成的可视化模式。对第一行 AM 的效果,尽管我们可以猜出可视化模式代表的是哪一类,但在每个可视化图案中都有多个重复和模糊的物体,例如第三列(AM-3)中的三个口红,并且图像远没有照片逼真。
对于第二行所示的 DGN-AM,通过利用生成器网络,DGN-AM 从颜色和纹理方面大大提高了图像质量。这是因为全连接层包含了来自图像所有区域的信息,并且生成器网络对实际可视化提供了一个强偏置。
通过输出层可视化,我们可以清楚地看到哪些目标组合可能会影响 CNN 分类的决策。例如,如果 CNN 将人手中持有的手机图像分类为手机,我们其实不清楚这个分类决策是不是受到了人手的影响。通过可视化,我们可以看到手机这一类别中有手机和人手。 可视化表明 CNN 已经学会了在一幅图像中检测到两个目标信息。
小结
作为最直观的可视化方法,AM 方法显示出 CNN 可以学习在无需手工指定的情况下检测出重要的特征,例如脸部,轮子和瓶子。与此同时,CNN 试图模仿视觉皮层的层级组织,并进而成功地构建了层级特征提取机制。此外,这种可视化方法表明,单个神经元会以更局部的方式提取特征而不是分布式,并且每个神经元都对应于特定的模式。
▌通过反卷积网络(Deconvolutional Network)进行可视化
从给定的输入图像中找出激活卷积图层中特定神经元的选择性模式。
Activation Maximization 从神经元的角度解释了 CNN,而基于 CNN 的 Deconvolutional Network(DeconvNet)则是从输入图像的角度解释了 CNN。 它从输入图像中找出激活卷积层中特定神经元的选择性模式。通过将低维神经元的特征图到图像维度来重构图案。
该映射过程由 DeconvNet 结构实现,DeconvNet 结构通过反卷积层和反池化层,执行卷积层和池化层的反向计算。 基于 DeconvNet 的可视化并不是纯粹分析神经元首选特征,而是在图像层次上进行一个更为直接的特征分析。
DeconvNet 结构的研究主要由 Zeiler 等人主导。他们首先提出了 DeconvNet 结构,旨在通过将高度多样化的低维特征图映射到高维来捕获重建自然图像的某些一般特征。后来他们利用 DeconvNet 结构分层次分解图像,从而可捕捉到从低级边缘到高级目标部分所有尺度的图像信息。
最终,他们通过解释 CNN 隐藏特征应用 DeconvNet 结构进行 CNN 可视化,这使它成为了一种可视化 CNN 的有效方法。
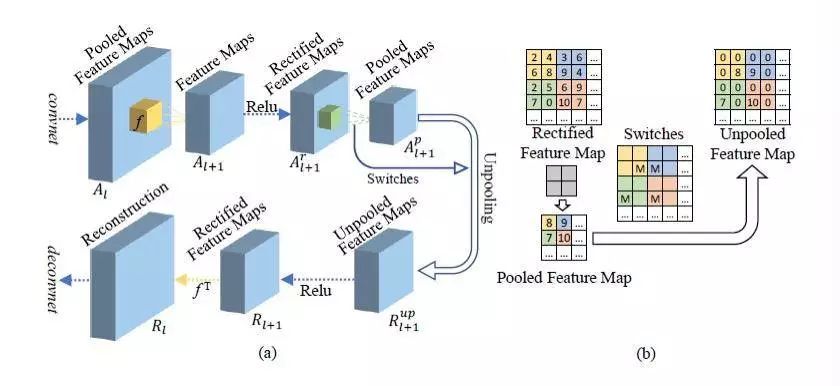
Deconvolutional Network 的网络结构
基于这些层形成的反向结构,DeconvNet 可以很好地对 CNN 进行可视化。 可视化过程可以描述如下:
(1)当通过 CNN 处理特定输入图像时,该网络可以捕获所有神经元的特征图。
(2)网络将选择出用于可视化的目标神经元的特征图,同时将其他所有神经元的特征图设置为零。
(3)为了获得可视化模式,DeconvNet 会将目标神经元的特征图映射回图像维度。
(4)为了将所有神经元可视化,该过程会被重复应用于所有神经元并获得一组用于CNN 可视化的相应模式图像。
这些可视化模式可以表明输入图像中的哪些像素或特征有助于神经元的激活,并且还可以用于检查 CNN 设计缺陷。

通过 DeconvNet 对 CaffeNet 进行可视化
上图是一个基于 DeconvNet 的可视化示例,包含了 CaffeNet 从 CL1 到 CL5 的 5 个卷积层。在每一层中,我们随机选择两个神经元的可视化模式与原始图像中相应的局部区域进行比较。从这些例子中,我们可以看出:每个单独的神经元都以更局部的方式提取特征,其每一层中的不同神经元负责不同的模式,例如嘴,眼睛和耳朵。 低层(CL1,CL2)捕捉小边缘,角落和部件。 CL3 具有更复杂的不变性,可捕捉纹理等类似的网格模式。较高层(CL4,CL5)更具有类别性,可以显示出几乎整个目标。
与 Activation Maximization 相比,基于 DeconvNet 的可视化可以提供更加明确和直接的模式。
用于网络分析和优化的 DeconvNet 网络可视化
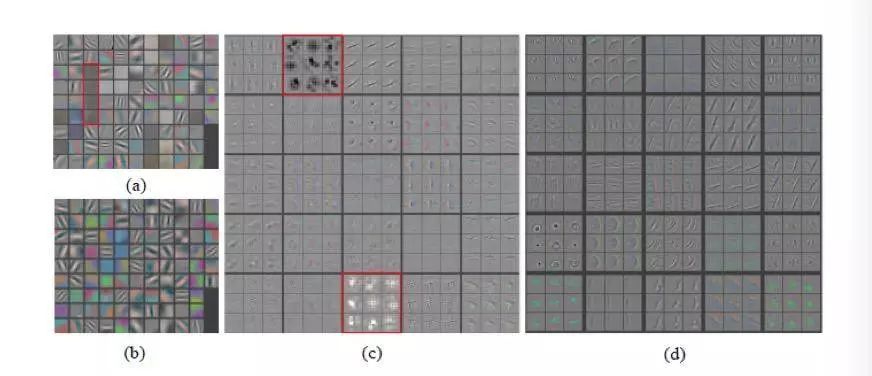
AlexNet和ZFNet网络第一层(输入层)和第二层可视化
除了用于解释分析的卷积层可视化之外,DeconvNet 还可用于检查 CNN 设计以进一步优化。上图(a)和(c)显示了 AlexNet 的第一层和第二层的可视化。 我们可以发现:
1)在第一层有一些没有任何特定模式的“死亡”神经元(用纯灰色表示),这意味着它们对于输入没有激活,这可能是高学习率的表现或者是权值初始化不是很好。
2)第二层可视化显示了混叠的假象,用红色矩形突出显示,这可能是由于第一层卷积中使用的步长较大引起的。
这些来自可视化的结果可以很好地应用于 CNN 优化。 因此,Zeiler 等人 提出了 ZFNet,它减少了第一层滤波器的尺寸,缩小了 AlexNet 的卷积步长,从而在前两个卷积层中保留了更多特征。
图(b)和(d)展示了 ZFNet 引入的改进,它显示了 ZFNet 的第一层和第二层的可视化。我们可以看到第一层中的图案变得更加独特,而第二层中的图案没有混叠假象。 因此,可视化可以有效应用于 CNN 分析和进一步优化。
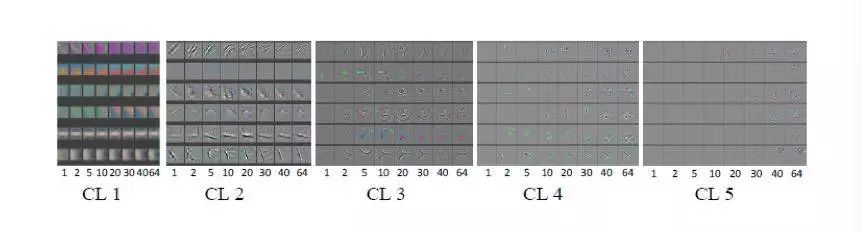
训练 ZFNet 期间的特征演变
除了 CNN 网络优化之外,可解释性分析还可以帮助监视 CNN 训练过程以获得更好的训练效率。
上图显示了在 ZFNet 训练期间的可视化模式。每一行分别代表卷积层中的不同神经元。每一列则是在不同训练时期随机选择的可视化模式子集。我们可以发现:
1)在每一行中,颜色对比度会随着训练过程被人为地增强。
2)较低层(CL1,CL2)会很快收敛,因为在几个时期出现了不同的模式。
3)然而,在高层(CL4,CL5)中这些显著的模式需要经过相当长的一段的时期才会出现,这意味着这些层需要一直训练到完全收敛。
另外,如果在训练过程中观察到噪音模式,则可能表明网络训练时间不够长,或者正则化强度低,从而导致训练结果过拟合。通过在训练期间的几个时间点可视化特征,我们可以发现设计缺陷并及时调整网络参数。一般来说,训练过程的可视化是监控和评估训练状态的有效方法。
小结
DeconvNet 强调了输入图像中哪些选定的模式可以以更具可解释性的方式对神经元的激活作出贡献。另外,这种方法可以用来检查 CNN 的优化问题。 训练监测可以在调整训练参数和停止训练时为 CNN 研究提供更好的参照。然而,AM 和 DeconvNet 的这两种方法都只将神经元层面的 CNN 进行了可视化,缺乏从更高层次结构(如网络层和整个网络)的综合视角。在下面的部分,我们将进一步讨论高层次的 CNN 可视化方法,这种方法可以解释每个单独的网络层,并将整个网络层中的一组神经元捕获的信息可视化。
▌通过 Network Inversion 进行可视化
在任意图层中重建所有神经元特征图的图像,以突出显示给定输入图像的综合 CNN 图层级特征。
不同于来自单个网络神经元的激活,层级激活可以揭示由层内的所有神经元激活模式组成的更全面的特征表示。因此,和之前对来自单个神经元激活的 CNN 进行可视化不同,基于 Network Inversion 的可视化可用于从层级角度分析激活信息。
在将 Network Inversion 被用于 CNNs 可视化之前,传统的计算机视觉表示研究就已经提出了 Network Inversion 的基本思想,如方向梯度直方图(HOG),尺度不变特征变换 (SIFT),局部二元描述符(LBD)和视觉词袋描述模型。后来,研究人员针对 CNN 可视化提出了两种 Network Inversion 方案:
1)基于正则化的 Network Inversion:由 Mahendran 等人提出,它利用梯度下降法和正则化项重建每一层的图像。
2)基于 UpconvNet的Network Inversion:它由 Dosovitskiy 等人提出。通过训练专用的上卷积神经网络(UpconvNet)重构图像。
总的来说,这两种算法的主要目标都是从一个完整网络层的特征图的特定激活中重建原始输入图像。基于正则化的 Network Inversion 更容易实施,因为它不需要训练额外的专用网络。而基于 UpconvNet 的 Network Inversion 虽然需要额外的专用网络和更高的计算成本,但却可以可视化更多更高层的信息。
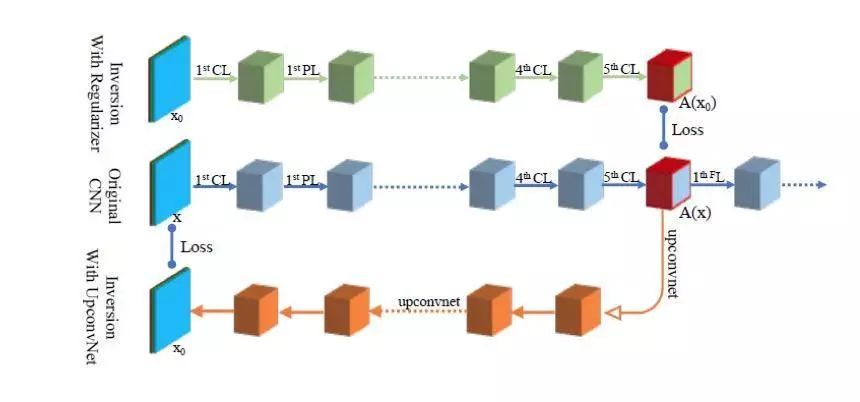
两种 Network Inversion 算法的数据流
上图显示了两种基于 Network Inversion 的可视化方法网络实现与原始 CNN 的比较:基于正则化的 Network Inversion 在上面用绿色表示,基于 UpconvNet 的 Network Inversion 显示在下面用橙色表示,而原始的 CNN 在中间用蓝色表示。
基于正则项的 Network Inversion 在可视化目标层之前具有与原始 CNN 相同的架构和参数。在这种情况下,算法会调整待重构图像 x0 的每个像素以最小化 x0 的目标特征图 A(x0)和原始输入图像x的特征图 A(x)之间的目标损失函数误差。
基于 UpconvNet 的 Network Inversion 会为特征映射返回图像维度提供反向路径。算法会调整 UpconvNet 的参数以最小化重建图像 x0 和原始输入图像 x 之间的目标损失函数误差。
网络层级可视化分析
网络层的可视化可以揭示每个层保留的特征。下图显示了 Regularizer 和 UpconvNet 方法在 AlexNet 各层的可视化。

通过基于正则项和 UpconvNet 的 Network Inversion 对 AlexNet 进行重构
从上图我们可以发现:
1)尽管来自 CL 的可视化比较模糊,但看起来依然与原始图像很相似。 这表明较低层特征可以保留更多详细信息,例如目标的颜色和位置。
2)可视化质量从 CL 到 FL 发生了显著下降。然而,高级 CL 甚至 FL 的可视化可以保存颜色(UpconvNet)和大致的目标位置信息。
3)基于 UpconvNet 的可视化质量优于基于 Regularizer 的可视化,尤其是 FL。
4)无关信息逐渐从低层向高层过渡。
网络层级特征图分析
基于网络层级分析,我们可以进一步利用基于 Network Inversion 的可视化分析特征图特征。 Dosovitskiy 等人对一层中的一部分特征进行了摄动,并从这些摄动特征映射中重建图像。摄动以两种方式进行:
1)二值化(Binarization):保留所有特征图的值的符号,并将它们的绝对值设置为固定数值。这些值的欧几里德范数保持不变。
2)Dropout:50% 的特征图的值被设置为零,然后归一化以保持其欧几里得范数不变。

通过扰动特征图的 ALexNet 重构
上图显示了两个摄动方法在不同层下的重建图像。从图中我们可以看出:
1)在 FL1 中,二值化几乎不改变重建质量,这意味着几乎所有关于输入图像的信息都包含在非零特征图的模式中。
2)Dropout 改变重建的图像幅度很大。但是,Dosovitskiy 等人还通过实验表明,通过丢弃 50% 最不重要的特征图可以显著减少重建误差,这比大多数不应用任何 Dropout 的层更好。这些观察可以证明很多 CNN 压缩技术都可以实现最佳性能,例如量化(quantization)和滤波修剪(Filter pruning),这是由于每层中都存在大量冗余信息。因此,基于 Network Inversion 的可视化可用于评估特征映射的重要性,并剪去最不重要的特征映射以进行网络压缩。
小结
基于 Network Inversion 的可视化将特定图层的特征图投影到图像维度,从而可以对特定图层所保留的特征进行深入了解。另外,通过对一些可视化的特征映射进行摄动,我们可以验证 CNN 在每一层中保存了大量冗余信息,因此进一步优化了 CNN 设计。
▌通过 Network Dissection 进行可视化
用特定的语义概念评估每个卷积神经元或多个神经元之间的相关性。
在之前部分我们介绍的多个可视化方法揭示了单个神经元或可捕捉层的视觉可感知模式。然而,视觉可感知模式和清晰的可解释语义概念之间仍然存在缺失。
因此,Bau 等人提出了 Network Dissection.,它将每个卷积神经元与特定的语义概念直接相关联,如颜色,纹理,材质,部件,物体和场景。神经元和语义概念之间的相关性可以通过具体语义概念寻找对特定图像内容响应强烈的神经元来测量。异构图像数据集—— Borden 为图像提供了与本地内容相对应的特定语义概念。
下图中给出了一组 Broden 示例,其中语义概念被划分为用红框突出显示的六个类别。每个语义类别可以涵盖各种类别,例如植物,火车等。在下图每个示例的右下角,还有识别到的语义对应神经元。我们还可以看到,黑色蒙版覆盖了与指定语义无关的图像内容。Network Dissection 建议生成这些黑色蒙版。

AlexNet 中激活的某些神经元的 BroNet 图像
Network Dissection 的发展逐渐将语义概念连接到了 CNN 中的不同组件级别。 Network Dissection 的基本算法说明了一个语义概念和一个单独神经元之间的相关性。这种相关性是基于每个语义概念都可以分配给单个神经元的假设。
后来,进一步的 Network Dissection 工作表明,特征可以分布表示,这表明一个语义概念可以由多个神经元的组合表示。因此,Fong 等人提出了另一种 Network Dissection 方法,即 Net2Vec,它将基于神经元组合的语义概念可视化。
这两种方法都可以提供解释 CNN 隐藏神经元的全面可视化结果。
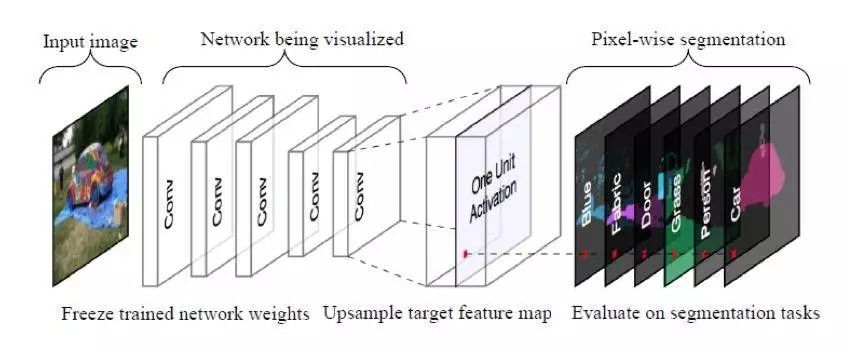
用于测量给定 CNN 中神经元的语义校准的 Network Dissection 图示
单个神经元的 Network Dissection

通过 Network Dissection 进行 AlexNet 可视化
单个神经元的可视化结果下图所示。在每列中,每个 CL 中显示了四个单独的神经元以及两个 Broden 图像。对于每个神经元,左上角是预测的语义概念,右上角代表神经元数量。
从图中,我们可以发现:
1)每幅图像都突出显示了真实图像中引起高度神经激活的区域。
2)预测标签非常匹配突出显示的区域。
3)从检测器总结的数字中我们可以发现,颜色概念在较低层( CL1 和 CL 2)占主导地位,而 CL5 中则出现更多的目标和纹理检测器。
与以前的可视化方法相比,我们可以发现:CNN 的所有层神经元都可以检测到信息,而不仅仅是底层神经元,颜色和纹理这样的信息即使在更高层中也可以保存,因为在这些层中也可以找到许多颜色检测器。
在不同的训练条件下的可解释性
训练条件(如训练迭代次数)也可能影响 CNN 的表示学习。Bau 等人通过使用不同的训练条件,如 Dropout,批量归一化和随机初始化评估了各种 CNNs 模型可解释性的影响。在下图的右侧部分,NoDropout 表示 baseline 模型——AlexNet 的 FC 层中的 Dropout 被移除了。BN 表示批量归一化应用于每个 CL。 而 repeat1,repeat2 和 repeat3 表示随着训练迭代次数随机初始化权重。
我们可以观察到:
1)网络在不同的初始化配置下显示出类似的可解释性。
2)对于没有应用 Dropout 的网络,会出现更多的纹理检测器,但会有更少的目标检测器。
3)批量归一化似乎显著降低了可解释性。
总体而言,Dropout 和批量归一化可以提高分类准确度。从可视化的角度来看,在没有 Dropout 时,网络倾向于捕获基本信息。而且批量归一化可能会降低特征多样性。
通过这样的评估,我们可以发现基于 Network Dissection 的可视化可以有效地应用于从网络可解释性的角度对不同 CNN 优化方法的评估。
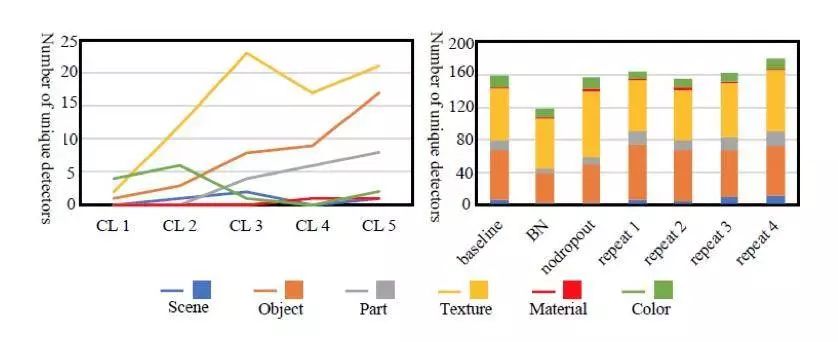
每个层次和不同的训练条件下的语义概念
神经元组合的 Network Dissection

单个神经元和神经元组合的 Network Dissection
通过使用组合神经元的可视化结果如上图所示。第一行和第三行是单个神经元的分割结果,而第二行和第四行由神经元组合分割的结果。正如我们所看到的,对于使用加权组合方法的“狗”和“飞机”的语义可视化,预测掩码对于大多数示例来说都是显著的。这表明,尽管我们可以找到对应于某个概念的神经元,但这些神经元并未最佳地表现或完全涵盖这个概念。
小结
Network Dissection 是一种用于解释 CNN 的独特可视化方法,可以自动将语义概念分配给内部神经元。通过测量未采样的神经元激活和具有语义标签的真实图像之间的校准,Network Dissection 可以可视化由每个卷积神经元表示的语义概念的类型。Net2Vec 证实 CNN 的特征表示是分布式的。此外,Network Dissection 可用于评估各种训练条件,这表明训练条件可以对隐藏神经元学习表示的可解释性产生重大影响。这种方法可以看做 CNN 可视化和 CNN 优化的另一个代表性例子。
▌总结
在本文中,我们回顾了 CNN 可视化方法的最新发展。并从结构,算法,操作和实验方面多个角度呈现了四种具有代表性的可视化方法,以涵盖 CNN 可解释性研究的最新成果。
通过对代表性可视化方法的研究,我们可以发现:CNN 确实具有模仿人类视觉皮层层级组织的层级特征表示机制。另外,为了揭示 CNN 内部的解释机制,可视化工作需要针对不同的 CNN 组件采取不同的分析角度。此外,CNN 通过可视化获得的更好的可解释性实际上有助于 CNN 优化。
作者:Zhuwei Qin, Funxun Yu, Chenchen Liu, Xiang Chen
源链接:https://arxiv.org/abs/1804.11191
本文由 AI科技大本营编译,转载请联系小助手(微信1092722531),备注:转载
精彩预告
◆
公开课
◆
时间:5月31日 20:00-21:00
扫描海报二维码,免费报名
添加小助手微信csdnai,备注:公开课,加入课程交流群



☟☟☟点击 | 阅读原文 | 查看更多精彩内容



