33个关键点——谷歌研究人员提出全新神经网络BlazePose,可健身跟踪、手语识别

新智元报道
新智元报道
来源:arxiv
编辑:雅新
【新智元导读】谷歌研究人员最近在CVPR 2020上发表的一篇论文提出了用于边缘设备上运行的单人人体姿态估计算法BlazePose。该算法在中端手机CPU上的性能比20核桌面CPU上的OpenPose还要快25-75倍。
 论文地址:https://arxiv.org/pdf/2006.10204.pdf
论文地址:https://arxiv.org/pdf/2006.10204.pdf
用面部检测器代替身体检测器,速度超OpenPose
用面部检测器代替身体检测器,速度超OpenPose
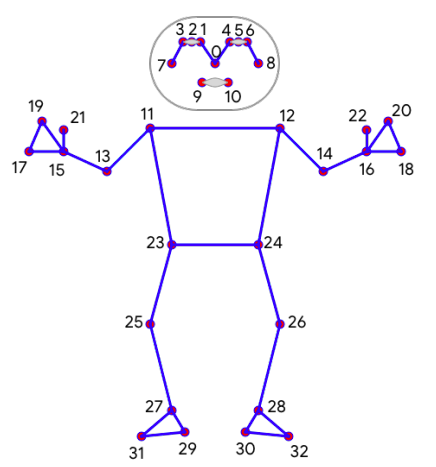
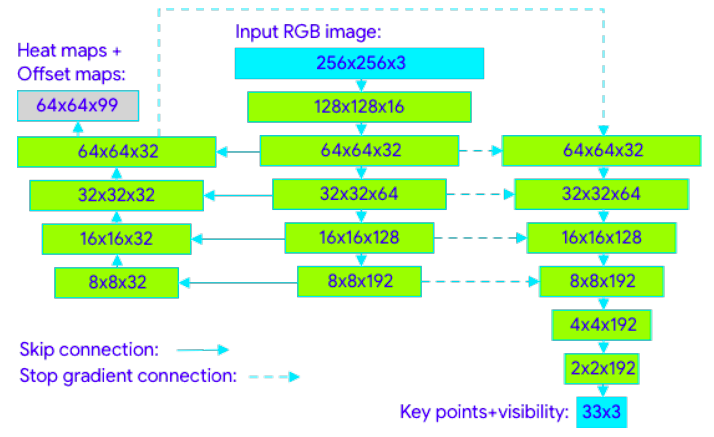
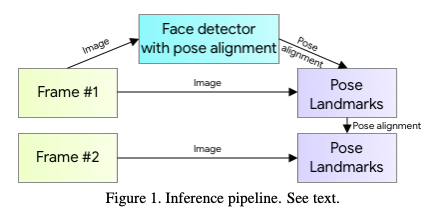
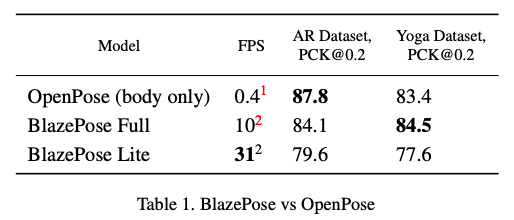

参考链接:
https://www.arxiv-vanity.com/papers/2006.10204/

登录查看更多
相关内容
Arxiv
8+阅读 · 2018年8月22日
Arxiv
6+阅读 · 2018年7月19日
相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2018年8月22日
Arxiv
6+阅读 · 2018年7月19日