零示例学习中的映射域迁移 (projection domain shift) 问题

AI 科技评论按:本文由上海交通大学副教授牛力为 AI 科技评论提供的独家稿件,未经许可不得转载。
在传统的机器学习中,训练和测试都在相同的种类集合上进行。而在零示例学习 (zero-shot learning) 中,训练种类集合和测试种类集合没有重合,即在属于训练种类集合的数据上训练模型,然后在属于测试种类集合的数据上进行预测。训练种类和测试种类需要通过所有种类的语义信息建立联系,才能把在训练种类的分类模型用于测试种类。常见的种类语义信息包括属性 (attribute) 和词向量 (word vector) 等等。其中属性需要人工标注,但是更精确,因而效果更好。我们把图像的视觉特征称为视觉空间 (visual space),把种类的语义信息称为语义空间 (semantic space)。现有的一大类零示例学习的方法是把视觉空间映射到语义空间,或者把语义空间映射到视觉空间,或者把两者映射到共同的子空间。其中学习到的映射称为视觉语义映射 (visual-semantic mapping)。比如语义空间有一种属性是 has_tail,我们需要学习从视觉空间到该属性的映射,这样给定一张新的动物图片,我们就可以判断它有没有尾巴。在这种情况下,视觉语义映射相当于由若干个属性分类器构成。但是对于不同种类来说,视觉语义映射有很大的差异。比如斑马和猪都有尾巴,但是它们尾巴的视觉呈现差别很大,因而对应的属性分类器差异也很大。如果对于所有种类使用相同的视觉语义映射,在测试种类上得到的效果就会大打折扣。这个问题被称为零示例学习中的映射域迁移 (projection domain shift) 问题。
之前大多数解决映射域迁移的方法都是在训练阶段使用未标注的测试种类数据,为训练种类和测试种类学习一个共同的映射,或者为训练种类和测试种类分别学习一个映射。但是由于各个种类的映射之间差异性都很大,仅仅学习一个或两个映射是远远不够的。所以我们提出为每一个种类都学习一个不同的视觉语义映射 (category-specific visual-semantic mapping),文章发表在期刊 Transaction on Image Processing (T-IP) (https://ieeexplore.ieee.org/document/8476580)。具体来说,我们先提出了一种传统的方法 AEZSL,利用种类之间的相似关系为每一个测试种类训练一个视觉语义映射。但是对于大规模任务来说这种训练成本十分高昂,所以我们又提出一种基于深度学习的方法 DAEZSL,只需要训练一次就可以应用到任意测试种类。下面分别介绍 AEZSL 和 DAEZSL。
(1) Adaptive Embedding Zero-Shot Learning (AEZSL)
我们的方法基于 Embarrassingly Simple Zero-Shot Learning (ESZSL)。ESZSL 的表达式如下,
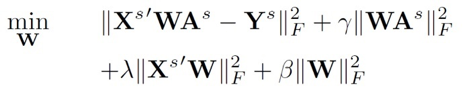
其中 X 是视觉特征,A 是语义信息,W 是视觉语义映射,Y 是种类标签信息。ESZSL 为所有种类学习一个相同的视觉语义映射 W。我们在 ESZSL 的基础上稍作修改,利用每一个测试种类和所有训练种类的相似关系(根据种类的语义信息计算得到),为每一个测试种类学一个单独的视觉语义映射,表达式如下:
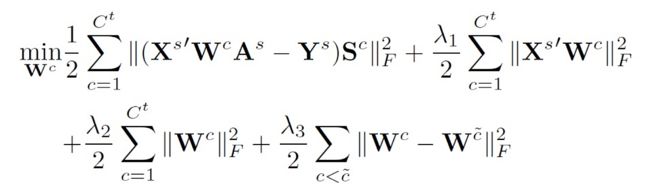
其中 Wc 是第 c 个测试种类的视觉语义映射,Sc 是第 c 个测试种类和所有训练种类的相似矩阵。这样就可以利用种类之间的相似关系把视觉语义映射迁移到各个测试种类。但是我们的 AEZSL 需要对每一个测试种类都训练一个视觉语义映射,对于大规模的任务训练成本非常高昂。因此我们又提出了一种基于深度学习的方法 Deep AEZSL (DAEZSL),只需要在训练种类上训练一次就能应用到任意测试种类,具体介绍如下。
(2) Deep AEZSL (DAEZSL)
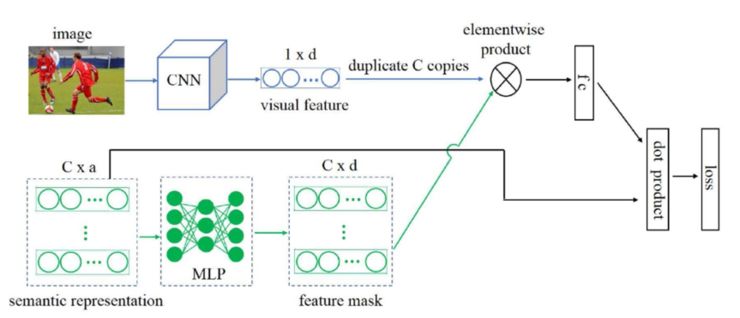
我们旨在学习一个从语义信息到视觉语义映射的映射函数,这样给定任意一个种类的语义信息,我们就能很方便地获得该种类的视觉语义映射。但是这样一个映射函数复杂度较高,所以我们采取一种替代的方式,假设每一个种类都存在学习视觉特征权重,然后学习从语义信息到视觉特征权重的映射函数。学习针对每个种类的视觉特种权重相当于隐性地学习针对每个种类的视觉语义映射,具体解释请参考论文。我们设计的网络结构如下图。在训练阶段,假设共有 C 个训练种类,在上面的子网络中,训练图片的视觉特征被复制成 C 份,在下面的子网络中,所有种类的语义信息通过 MLP 产生所有种类的视觉特征权重,作用于复制了 C 份的视觉特征。加权后的视觉特征通过全连接层(相当于视觉语义映射)后和所有种类的语义信息相乘得到最终的预测值。在测试阶段,测试图片通过上面的子网络,所有测试种类的语义信息通过下面的子网络,相乘得到该测试图片的预测值。
我们在三个小规模数据库 CUB, SUN, Dogs 和一个大规模数据库 ImageNet 上做了大量的实验,实验结果表明我们的方法在小规模和大规模数据库上均取得了最优的结果。除了定量结果,我们也提供了深入的定性分析。我们选择了两张「flea market」种类的图片,这两张图片被我们的 AEZSL 方法成功分类,却被 ESZSL 错分为「shoe shop」。通过对比「flea market」和「shoe shop」的语义信息,「cloth」和「cluttered space」这两个属性更能代表「flea market」。我们在下图列出了两张图片通过 ESZSL 和 AEZSL 方法得到的在「cloth」和「cluttered space」两属性上的投影值。从下图可以看出我们的方法 AEZSL 在两个属性上有更高的投影值,也就是说我们的方法能更好地捕获「flea market」种类在「cloth」和「cluttered space」两属性上的语义信息。

为了更好的解释说明,我们列举了同样包含「cloth」属性的两个种类「badminton court」和「bedchamber」, 以及同样包含「cluttered space」属性的两个种类「recycling plant」和「landfill」。从下图可以看出,同一个属性在不同种类上的视觉呈现和语义信息大相径庭。

对于「flea market」种类,我们列举了和它最相近的几个种类 bazaar, thrift shop, market, general store(如下图所示)。可见对于「cloth」和「cluttered space」两个属性,「flea market」和上述种类更为接近。我们的方法通过关联和「flea market」相近的几个种类,更好地捕获了「flea market」种类的「cloth」和「cluttered space」属性的语义信息,学到了更契合该种类的视觉语义映射。

总结一下,我们提出了为每一个种类学习单独的视觉语义映射,更好地捕获每个种类的语义信息,从而解决零示例学习中的映射域迁移问题。具体来说,我们提出了传统的 AEZSL 方法和基于深度学习的 DAEZSL 方法。AEZSL 方法为每个测试种类训练得到一个视觉语义映射,而 DAEZSL 只需要在训练种类上训练一次便可应用到任意测试种类。在四个数据库上的定量结果和定性分析充分展示了我们方法的优越性。




