计算高效,时序一致,超清还原!清华&NYU 提出 RRN:视频超分新型递归网络

极市导读
本文为大家介绍一个视频超分方向的最新工作:新颖的递归网络RRN。文章将残差学习思想引入到RNN中,在保持长周期纹理信息的同时降低了训练过程中的梯度消失的风险。该工作在Vid4数据集上超越了EDVR的PSNR指标。同时,文章还对常用的三种时序建模方案进行了系统的对比分析。>>>极市七夕粉丝福利活动:炼丹师们,七夕这道算法题,你会解吗?

paper: https://arxiv.org/2008.05765
code: https://github.com/junpan19/RRN(即将开源)
Abstract
视频超分在监控视频分析与超高清视频显示中扮演着非常重要的作用,它在工业界与学术界获得了非常多的关注。尽管有许多基于深度学习的视频超分方法已被提出,但是往往难以直接对这些方法进行对比,这是因为(1) 不同的损失函数;(2) 不同的训练数据等因素对于超分结果影响非常大。
该文仔细研究并对了视频超分中的三种时序建模方案(2D-CNN, 3D-CNN, RNN),同时还提出了一种新颖的递归残差模块用于高效视频超分,其中残差学习用于稳定训练并提升超分性能。
作者通过充分的实验表明:所提RRN计算高效同时可以生成时序一致的超分结果,且具有更好的纹理细节。除此之外,所提方法在公开基准数据集取得了SOTA性能。
该文的贡献主要包含两方面:
-
精心研究并对比了视频超分中常用的三种时序建模方法; -
提出了一种新颖的隐状态用于递归网络,它在所有时序建模方法中取得最佳性能,并在三个公开数据集取得了SOTA性能。
Method
接下来,我们将重点介绍一下该文所提整理系统方案以及时序建模方法的细节。整个视频超分系统包含两个部分:(1) 时序建模网络;(2) 图像/视频重建网络;(3) 损失函数。该文的重点是1与3两个部分。在时序建模网络方面,作者重点研究了2DCNN快融合(见下图A)、3DCNN慢融合(见下图B)以及RNN(见下图C)三种时序建模方案。基于不同建模方案的分析而提出了该文的RRN建模方案(见下图D)。
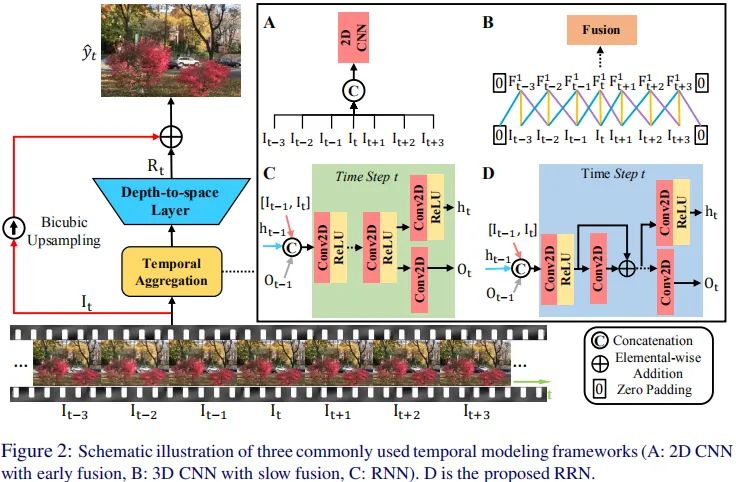
如前所述,该文考虑了三种形式的时序建模方案。接下来,我们就针对这三种方案进行介绍与分析。
2DCNN快融合
该方案以多帧作为输入,直接通过concat方式进行融合,然后采用堆叠2D卷积提取特征。受EDSR启发,作者了采用改进2D残差模块设计了2DCNN快融合模块。该融合过程可以描述为:
的输入维度为
,其中
。
表示2D卷积的权值。该2DCNN的输出残差特征的维度为
,然后通过depth-to-space方式进行上采样,最后将所得残差图与原始输入中间帧的bicubic结果相加得到最终的超分结果。
3DCNN慢融合
该方案以视频序列作为输入,然后采用堆叠3D卷积提取空-时信息。类似2DCNN,作者采用了相似的方式进行空-时信息提取,区别在于卷积由2D编程了3D。相比2DCNN,3DCNN中的时序信息融合更慢,该过程可以描述为:
其他的处理过程与2DCNN的过程基本相似,这里滤过不计。
RNN融合
相比CNN时序建模方法,RNN采用更少的帧与隐状态作为输入,并采用递归方式处理长视频序列。一般而言,时序t的隐状态包含三部分:(1) 前一帧的超分结果 ;(2) 前一帧的隐状态特征 ;(3) 两个相邻帧 。直观上讲,前后帧的像素往往具有非常强的相似性,t时刻的高频纹理可以通过前一帧的补充信息进行进一步精炼调整。类似其他视频处理任务,VSR中的RNN往往存在梯度消失问题。
为解决上述问题,作者提出了一种新颖的递归网络RRN(Residual Recurrent Network),它将残差学习思想引入到RNN中。这种设计确保了流畅的信息流,有助于保持长周期的纹理信息,进而使得RNN可以处理更长序列,同时降低了训练过程中的梯度消失风险。在t时刻,RNN采用如下方式生成隐状态与输出:
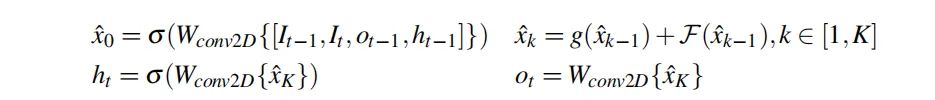
其中 表示ReLU激活函数, 表示恒等映射,即 ,而 表示学习到的残差特征图。
Experiments
之前的方法往往采用不同的训练数据集(比如有的采用Vimeo90K,有的采用REDS,有的采用自己制作的数据)、不同的下采样核(有的采用bicubic,有的采用blur-down),这就导致了不同方法无法公平对比。在该文中,作者采用Vimeo90K作为训练数据集,其中的LR采用blur-down方式制作。作者选用的测试数据集为Vid4、SPMCS以及UDM10三个公开数据集。
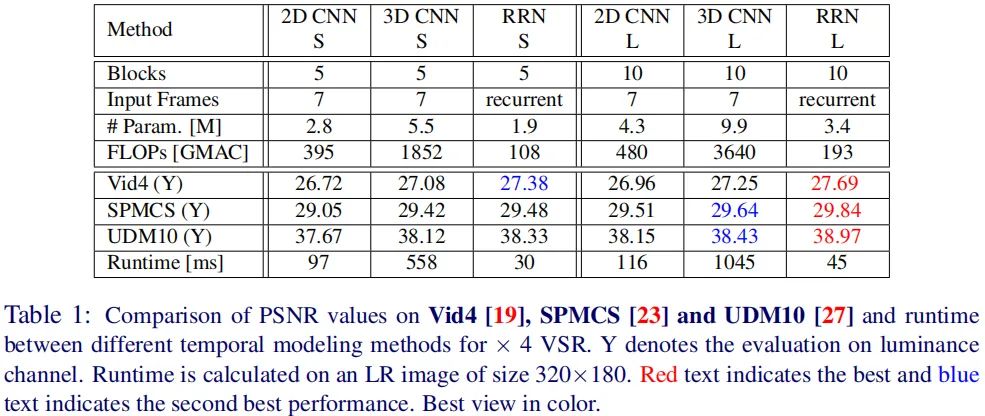
对于2DCNN时序建模方案,作者设计了2DCNN-S与2DCNN-L两种,分别采用5和10个2D残差模块,通道数为128;对于3DCNN时序建模方案,作者的设计类似2DCNN,故略过;为公平对比,对于RNN时序建模,作者也分别采用5和10个残差模块作为隐状态,即RNN-S与RNN-L,通道数同样为128, 时刻的隐状态初始化为0。
在训练过程中,2DCNN的学习率为0.0001,3DCNN的学习率为0.001,每10epoch衰减0.1,总计训练30epoch;RNN的学习率为0.0001,每60epoch衰减0.1,总计训练70epoch。所有模型均采用 损失函数、Adam优化器。CNN建模方案的Batch=64,RNN建模方案的Batch=4
下表给出了不同建模方案在公开数据集上的性能以及耗时对比。很明显,(1) 3DCNN时序建模方案以极大优势优于2DCNN,然而它非常耗时。(2) 相比3DCNN时序建模方案,RNN计算高效,参数量更少,同时具有更好的性能指标。(3)RRN-S能够以33fps生成720p视频,RRN-L能够以22fps生成720p视频。
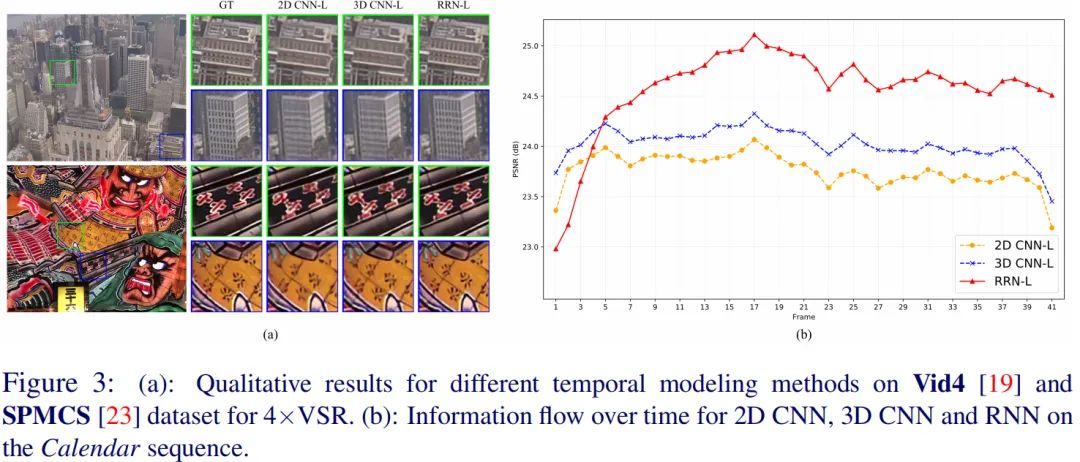
作者同时还对比了不同建模方案的时序一致性,见下图。RRN方案可以生成时序一致的结果同时具有更少的伪影问题。

为更好说明RRN的有效性,作者还对比了不带残差学习时的性能对比,见下表。可以看到不添加残差学习存在严重的梯度消失问题。

最后,作者给出了所提方法与其他视频超分方案的性能与效果对比。
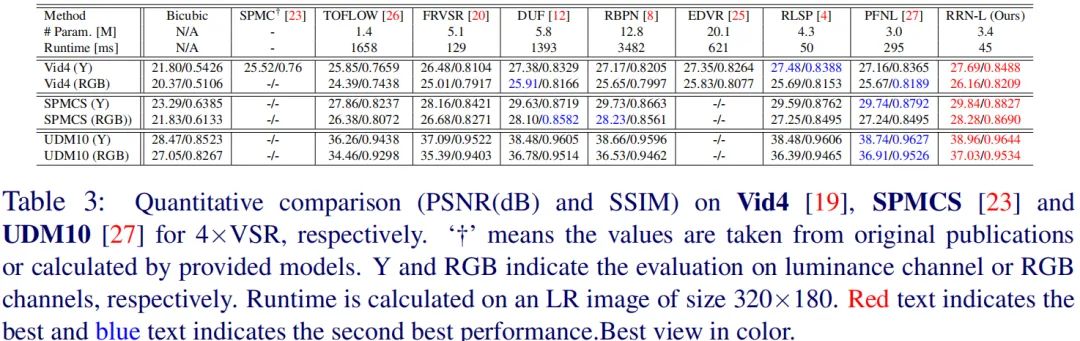

全文到此结束,对该文感兴趣的同学可以去看一下原文。最后,期待作者能尽快开源TGA、RSDN以及RRN的代码以及预训练模型,期待ing!
推荐阅读
图像超分最新记录!南洋理工提出图神经网络嵌入新思路,复原效果惊艳
NTIRE2020冠军方案RFB-ESRGAN:带感受野模块的超分网络
你一定从未看过如此通俗易懂的YOLO系列(从V1到V5)模型解读!






