机器学习学不好,90%的原因是这个……

今天刷到一个旧新闻,说的是去年广州有个开小饭店的大叔火了。
因为去他的店铺吃饭,点一份鸭肉+青菜+鸭肉汤,仅仅只要12块,还能免费续饭。
相比附近的店,简直超划算。
于是就有记者问他:“卖这么便宜肯定挣不了什么钱吧”
结果大叔笑了笑,“挣得少,但我活的很开心啊,我有也不是很多钱了,就是有十栋房子收租,每栋房子七层而已啦”
而且,这位大叔,还特地买了辆宝马专门用来买菜。
看完这个新闻,只有这张图能表达我此刻的心情。

唉,一套房也没有的七妹只能默默搬砖了。
说到搬砖,经常有小伙伴在后台给七妹留言:
都说机器学习中数学很重要,那数学到底要学到什么程度才可以呢。
那七妹今天就给大家分享一下,机器学习中数学需要学到什么程度。
对于绝大多数从事于机器学习的人来说,学数学的目的,主要是便于(深入)理解算法的思路。那么问题来了,我们到底要把数学学到什么程度?
这里举两个例子:
1、线性最小二乘法
大家可以随意搜索一下,相关的文章很多。长篇大论的不少,刚入门的朋友一看到那些公式可能就看不下去了。比如下面的解释:

毫无疑问,这样的解释是专业的,严谨的。事实上,这是深度学习圣经里的解释。
我并没有诋毁大师的意思,只是觉得用一个具体的例子来说明,可能会让读者更加容易理解:
小明是跑运输的,跑1公里需要6块,跑2公里需要5块(那段时间刚好油价跌了),跑3公里需要7块,跑4公里需要10块,请问跑5公里需要多少块?
如果我们有初中数学基础,应该会自然而然地想到用线性方程组来做,对吧。
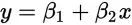
这里假定x是公里数,y是运输成本(β1和β2是要求的系数)。我们把上面的一组数据代入得到这么几个方程:
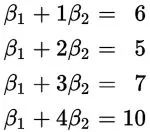
这里假定x是公里数,y是运输成本(β1和β2是要求的系数)。我们把上面的一组数据代入得到这么几个方程:
如果存在这样的β1和β2,让所有的数据(x,y)=(1,6),(2,5),(3,7),(4,10)都能满足的话,那么解答就很简单了,β1+5β2就是5公里的成本,对吧。
但遗憾的是,这样的β1和β2是不存在的,上面的方程组很容易,你可以把前面两个解出来得到一组β1和β2,后面两个也解出来同样得到一组β1和β2。这两组β1和β2是不一样的。
形象地说,就是你找不到一条直线,穿过所有的点,因为他们不在一条直线上。如下图:

可是现实生活中,我们就希望能找到一条直线,虽然不能满足所有条件,但能近似地表示这个趋势,或者说,能近似地知道5公里的运输成本,这也是有意义的。
现实生活当中,有很多这样的例子,想起以前在某公司上班的时候,CEO说我们研发部做事有个问题:一个研发任务,要求三个月做完,因为周期太短,完成不了,就干脆不做,这显然是不对的,要尽全力,哪怕三个月完成了80%,或者最终4个月完成,总比不作为的好。
其实最小二乘法也是这样,要尽全力让这条直线最接近这些点,那么问题来了,怎么才叫做最接近呢?直觉告诉我们,这条直线在所有数据点中间穿过,让这些点到这条直线的误差之和越小越好。
这里我们用方差来算更客观。也就是说,把每个点到直线的误差平方加起来:
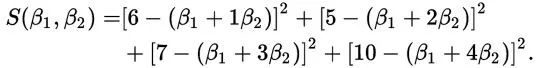
(如果上面的四个方程都能满足,那么S的值显然为0,这是最完美的,但如果做不到完美,我们就让这个S越小越好)
接下来的问题就是,如何让这个S变得最小。
这里有一个概念,就是求偏导数。这里我想提一下,在培训的过程中,我发现机器学习的数学基础课程当中,微积分是大家印象最深刻的,而且也最容易理解:比如导数就是求变化率,而偏导数则是当变量超过一个的时候,对其中一个变量求变化率。
要让S取得最小值(或最大值,但显然这个函数没有最大值,自己琢磨一下),那么S对于β1和β2分别求偏导结果为0,用一个直观的图来表示:
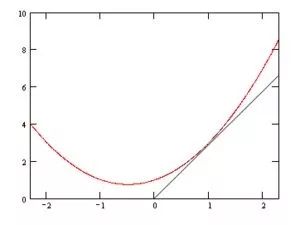
我们看到这条曲线,前半部分是呈下降的趋势,也就是变化率(导数)为负的,后半部分呈上升的趋势,也就是变化率(导数)为正,
那么分界点的导数为0,也就是取得最小值的地方。这是一个变量的情况,对于多个变量的情况,要让S取得最小值,那最好是对β1和β2分别求导(对β1求导的时候,把β2当常量所以叫求偏导),值为0:
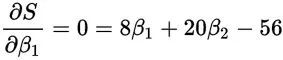
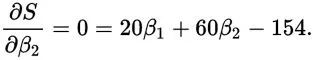
看到这个我们就熟悉了,两个变量,刚好有两个方程式,初中学过,那么很容易得出:
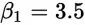
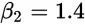
其实也就意味着:
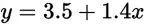
这个函数也就是我们要的直线,这条直线虽然不能把那些点串起来,但它能最大程度上接近这些点。也就是说5公里的时候,成本为3.5+1.4x5=10.5块,虽然不完美,但是很接近实际情况。
2、拉格朗日乘子法
听到拉格朗日乘子法这个名字的时候,很多人的第一反应是:这玩意儿是不是很高深啊,先入为主地有了畏难的情绪。
但我把它讲完以后,大部分人表示并不难,而且现实生活中,我们经常潜移默化会用到拉格朗日乘子法。甚至可以说,不用拉格朗日乘子法的人生都是不完整的人生。
我们来看一下定义:

虽然这个定义应该说是很简洁明了的,但对于大部分人来说,依然还是有点懵。不太清楚为什么要这么做。
拉格朗日到底要搞什么飞机?
我们还是举个例子:某工厂在生产过程中用到两类原材料,其中一种单价为2万/公斤,另一种为3万/公斤,而工厂每个月预算刚好是6万。就像下面的公式:
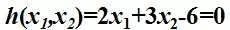
经过分析,工厂的产量f跟两种原材料(x1,x2)具有如下关系(我们暂且不管它是如何来的,而且假定产品可以按任意比例生产):
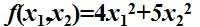
请问该工厂每个月最少能生产多少?其实现实生活中我们会经常遇到类似的问题:
在某个或某几个限制条件存在的情况下,求另一个函数的极值(极大或极小值)。
就好比你要在北京买房,肯定不是想买什么房子就买什么房子,想买多大就买多大,而是跟你手头的金额,是否有北京户口,纳税有没有满五年,家庭开支/负担重不重,工作单位稳不稳定都有关系。
回到工厂的例子,其实就是求函数f的极值。
上面我们提到,极值点可以通过求偏导(变化率为0的地方为极值点)来实现,函数f(x1,x2)对x1,x2分别求偏导。
那么得出的结论是:x1,x2都为0的时候最小,单独看这个函数,这个结论对的,很显然这个函数的最小值是0(任何数的平方都是大于或等于0),而且只有x1和x2同时为0的时候,取得最小值。
但问题是它不满足上面的限制条件。
怎么办呢?拉格朗日想到了一个很妙的办法,既然h(x1,x2)为0,那函数f(x1,x2)是否可以加上这个h(x1,x2)再乘以一个系数呢?任何数乘以0当然是0,f(x1,x2)加上0当然保持不变。
所以其实就可以等同于求下面这个函数的极值:
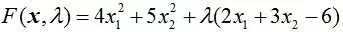
我们对x1,x2以及λ分别求偏导(极值点就是偏导数均为0的点):
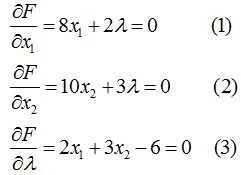
解上面的方程组得到x1=1.071,x2=1.286 然后代入f(x1,x2)即可。
这里为什么要多加一个乘子λ呢,试想一下,如果λ是个固定的数(比如-1),我们也能通过上面的方程式1,2求解得到x1,x2,但是我们就得不到方程式3,其实也就是没有约束条件了。
所以看到没有,拉格朗日很聪明,他希望我们在求偏导(极值点)以后,还能保留原有的约束条件。
我们上面提到,单独对函数求极值不能保证满足约束条件,拉格朗日这么一搞,就能把约束条件带进来,跟求其他变量的偏导结果放在一起,既能满足约束条件,又能保证是约束条件下的极值。
借用金星的一句话:完美!
当然这是一个约束条件的情况,如果有多个约束条件呢?
那就要用多个不同的λ(想想为什么),正如最上面的那个定义那样,把这些加起来(这些0加起来也是0)。
机器学习里的数学,我感觉只需要掌握里面这个核心思想即可,就像拉格朗日乘子法,求条件极值---》转化为求(函数+条件)的极值,每一步都很妙。
其实我想说的是,体会这种妙处以后,再看SVM的算法,会感觉舒服很多,数学主要是为了让人更好地理解算法,并不是为了数学而学数学。
人生苦短,还成天被晦涩的书籍所困扰,“感觉身体好像被掏空”,这样真的好么?
END
作者:Jacky Yang
链接:https://www.zhihu.com/question/36324957/answer/255970074
来源:知乎

今日福利推荐
【涨薪季〡涨薪大作战 】
【数据结构班】
【机器学习应用班】
【机器学习中的数学 第二期】
【python基础入门 第三期】
四门好课免费学,还有VIP年会员、700元京东购物卡免!费!送!
扫描海报二维码,领取吧



扫描下方二维码 关注:七月在线实验室
后台回复:100 免费领取【机器学习面试100题】
后台回复:干货 免费领取【全体系人工智能学习资料】
后台回复: 领资料 免费领取全套【NLP工程师必备干货资料】








