专栏 | 递归卷积神经网络在解析和实体识别中的应用
机器之心专栏
作者:触宝AI实验室Senior Engineer陈崇琛
在本文中,来自触宝科技的工程师介绍了如何在传统的解析算法中用上深度学习的技术。在实践中,深度学习减少了数据工程师大量的编码特征的时间,而且效果比人工提取特征好很多。在解析算法中应用神经网络是一个非常有前景的方向。
解析用户的真实意图
人类语言与计算机语言不同,人类的语言是没有结构的,即使存在一些语法规则,这些规则往往也充满着歧义。在有大量用户输入语料的情况下,我们需要根据用户的输入,分析用户的意图。比如我们想看看一个用户有没有购买某商品的想法,此时就必须使用解析算法,将用户的输入转换成结构化的数据,并且在此结构上提取出有用的信息。
NLP 解析算法的一般步骤是分词、标记词性、句法分析。分词和标记词性等,可以用条件随机场 (Conditional Random Field),隐马尔可夫模型 (Hidden Markov Model) 等模型解决,近年来也有用神经网络来做的,相对比较成熟,所以暂时不讨论。本文主要讨论一下最主要的一步,句法分析。
两种句法分析工具
目前的句法分析工具,主要分为依存文法 (Dependency Grammar) 与成分分析 (Constituency Relation) 两大类。
成分分析将文本划分为子短语。
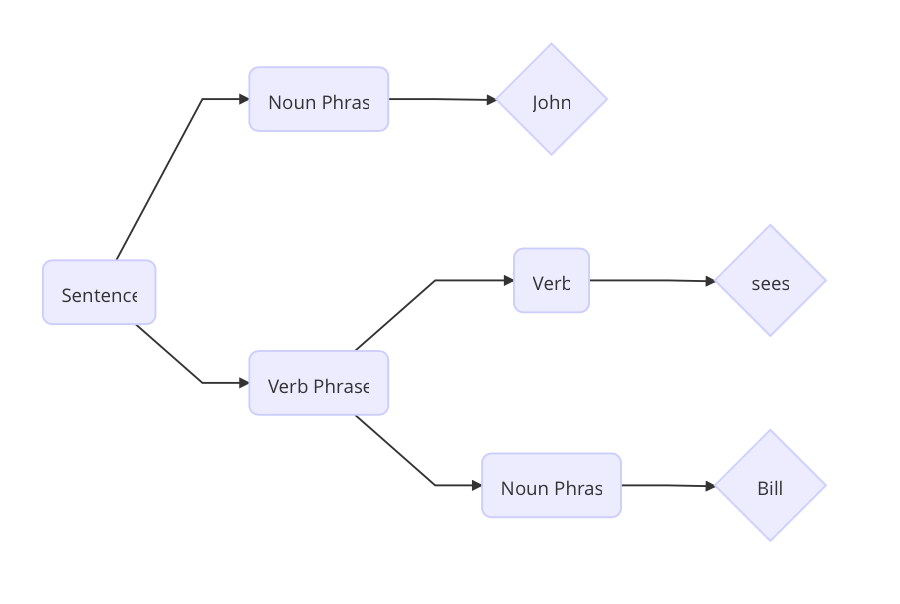
句子 John sees Bill 被划分成了如上图的结构。首先单词 Bill 是一个名词短语,sees 是一个动词,根据预先设置的语法规则,动词 + 名词短语能构成动词短语,然后 名词 + 动词短语能够构成一句完整的句子。
成分分析最著名的要数上下文无关文法 (Context Free Grammar) 及其各种变种,例如概率上下文文法 (Probabilistic Context Free Grammar)。
但是依存文法根据单词之间的修饰关系将它们连接起来构成一棵树,树中的每个节点都代表一个单词。
子节点的单词是依赖于父节点的,每条边标准了依赖关系的类型。上面例句被解析成下面的树。
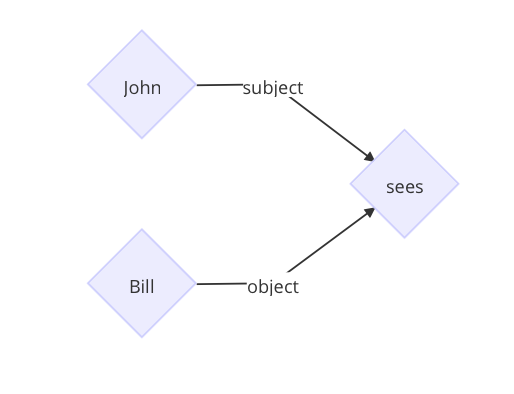
单词 John 是动词 sees 的主语,单词 Bill 是动词 sees 的宾语。
成分分析的缺点是搜索空间太大,构建树的时间往往和可供选择的节点的数目相关,成分分析需要在计算过程中不断构建新的节点,而依存分析不需要构建新的节点。自然语言中有歧义,例如上下文无关文法中有规则「C <- AB」,「D <- AB」, 那么在计算 AB 应该合成什么节点的时候就出现了两种选择,多种歧义组合在一起,使成分分析的搜索空间爆炸增长,必须设计一些算法进行剪枝等操作。而依存分析不会去创建节点,因此没有这些问题。但是成分分析中保存的信息比依存分析更加多一点,因此可以直接通过一些确定的规则将成分的树转化成依存树。
句法分析算法
依存文法树的构建我们可以看成是一个状态转换的序列。当前的状态包括三部分,s 为当前的栈,b 为剩余未解析的词的数组,以及一个依存关系的集合 A。初始的状态是
s=[ROOT], b=[w_1,...,w_n], A=∅ 。终止的状态是 b 为空。S 只有一个节点 ROOT , 解析出来的树就是集合 A 。定义 s_i 为栈顶第 i 个节点。b_i 为第 i 个未解析的词。可以定义如下的状态转移:
LEFT-ARC(l): 添加一个 s_1—>s_2 的标记为 l 的依赖关系,并且将 s_2 从栈里面移除。
RIGHT-ARC(l): 添加一个 s_2—>s_1 的标记为 l 的依赖关系,并且将 s_1 从栈里面移除。
SHIFT: 将 b_1 从未解析词的数组中移出,放入栈。
假设我们需要解析句子「He wants a Mac.」.
解析的过程如下:
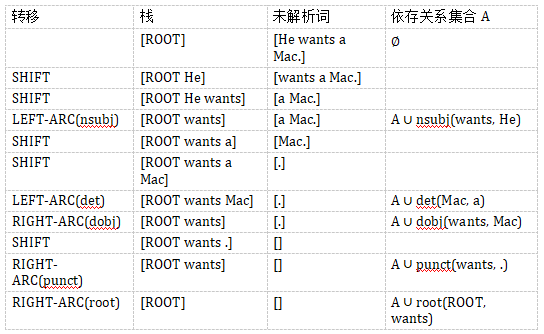
最终得到树
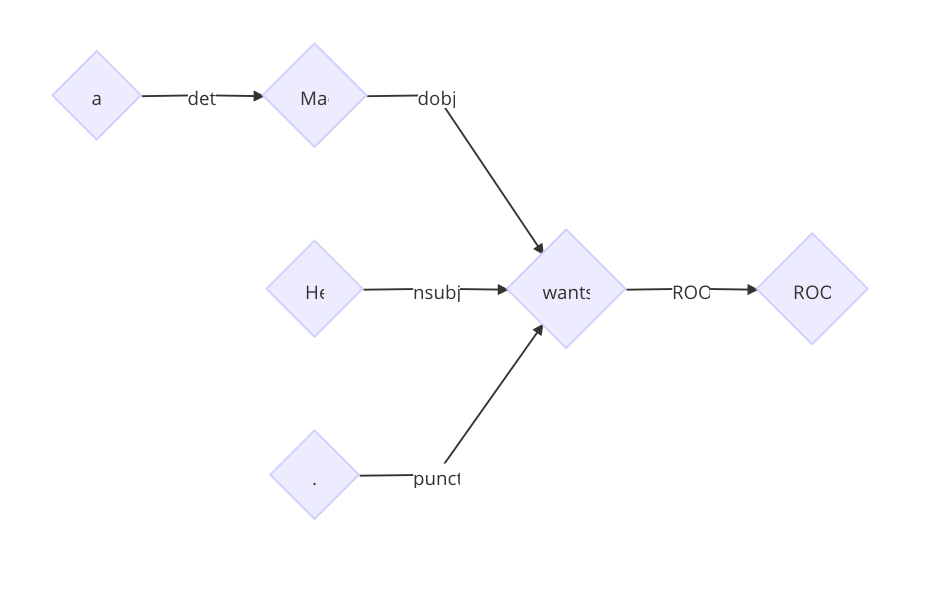
在每个状态下,我们都有很多可选的转移。关于如何选出正确的转移,一般有贪心或者搜索两种策略。目前的结果表明,尽管贪心比搜索的结果稍微差一点,但是解析的速度快非常多,因此,日常使用基本采用贪心算法。
传统解析算法的困境
传统的解析算法需要根据当前的状态以及预先设置好的规则提取出特征。比如当前栈顶的前两个词,当前前几个未解析的词等。
但是这些特征有如下问题:
稀疏。这些特征尤其是词法特征,非常稀疏。依存文法的分析依赖于词之间的关系,有可能两个词距离非常远,那么仅仅提取栈顶前两个词作为特征已经无法满足需要,必须使用更高维度的特征,一旦维度高,势必使得特征非常稀疏。
不完整。人的经验是有偏差的,专家概括的特征提取规则,总是不完整的。
解析算法的绝大部分时间花费在了提取特征中。据统计百分之九十几的时间花费是特征提取。
此时便需要神经网络出场来给我们估计哪个是最优的状态转移了。
递归神经网络 (Recursive Neural Network)
词嵌入是将单词表示成低维的稠密的实数向量。自从词向量技术的提出,到目前为止已经有很多方法来得到句法和语义方面的向量表示,这种技术在 NLP 领域发挥着重要的作用。
如何用稠密的向量表示短语,这是使用词向量的一个难题。在成分分析中,业界使用递归神经网络 (Recursive Neural Network, RNN) 来解决这个问题。RNN 是一种通用的模型,用来对句子进行建模。句子的语法树中的左右子节点通过一层线性神经网络结合起来,根节点的这层神经网络的参数就表示整句句子。RNN 能够给语法树中的所有叶子节点一个固定长度的向量表示,然后递归地给中间节点建立向量的表示。
假设我们的语法二叉树是 p_2—>ap_1 , p_1—>bc ,即 p_2 有子节点a、p_1,p_1 有子节点 b、c 。那么节点表示成
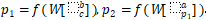
其中 W 是 RNN 的参数矩阵。为了计算一个父节点是否合理,我们可以用一个线性层来打分, score(p_i)=vp_i 。v是需要被训练的参数向量。在构建树的过程中,我们采用这种方法来评估各种可能的构建,选出最佳的构建。
基于神经网络的依存解析
但是 RNN 只能处理二元的组合,不适合依存分析。因为依存分析的某个节点可能会有非常多的子节点。于是有学者提出用递归卷积神经网络 (Recursive Convolutional Neural Network, RCNN) 来解决这个问题。通过使用 RCNN,我们能够捕捉到单词和短语的句法和组合语义的表示。RCNN 的架构能够处理任意 k 分叉的解析树。RCNN 是一个通用的架构,不仅能够用于依存分析,还能对于文章的语义进行建模,将任意长度的文本转化成固定长度的向量。
RCNN 单元
对于依存树上的每个节点,我们用一个 RCNN 单元来表示改节点与其子节点之间的关系,然后用一层 Pooling 层来获得最具信息量的表示。每个 RCNN 单元又是其父节点的 RCNN 单元的输入。
下图展示的是 RCNN 如何来表示短语「He wants a Mac」。
graph LR
a{"W(a)"} --> RCNN_UNit_mac[RCNN UNit]
mac{"W(mac)"} --> RCNN_UNit_mac[RCNN Unit]
RCNN_UNit_mac --> X_mac{"X(mac)"}
He{"W(He)"} --> RCNN_UNit_wants["RCNN Unit"]
wants{"W(wants)"} --> RCNN_UNit_wants
X_mac --> RCNN_UNit_wants
P{"W(.)"} --> RCNN_UNit_wants
RCNN_UNit_wants --> X_wants{"X(wants)"}
X_wants --> RCNN_Unit_root["RCNN Unit"]
root{"W(root)"} --> RCNN_Unit_root
RCNN_Unit_root --> X_root{"X(root)"}
RCNN 单元内部结构如下图所示:
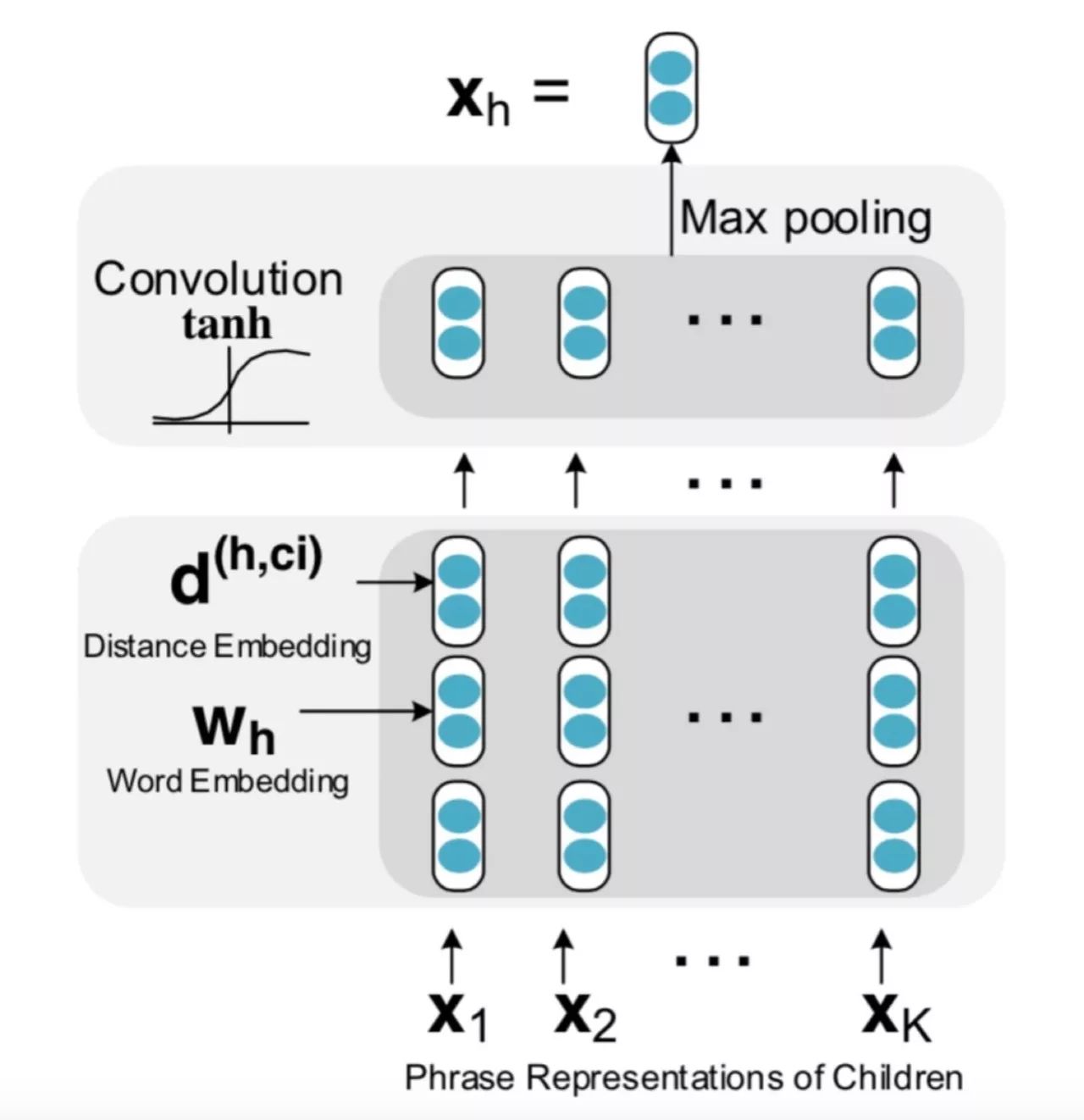
RCNN 单元的构建
首先对于每个词,我们需要将其转换成向量。这一步一开始可以用已经训练好的向量,然后在训练的时候根据反向传播来进行更新。
距离嵌入 (Distance Embedding),除了词需要嵌入,我们还需要将一个词和该词的子节点之间的距离进行编码。很直觉的是距离近的词更有可能发生修饰关系。例如上面的例子中,Mac 到 a 的距离是-1,到 wants 的距离是 -2。距离嵌入编码了子树的更多信息。
最后将词向量和距离向量作为卷积层的输入。
与一般的解析树不同,依存分析的树的每个节点都有两个向量表示。一个是该节点的单词的词向量表示w,另一个是该节点的短语向量表示x。
对于父节点 h,以及某个子节点 c_i,用卷积隐层来计算他们组合起来的表示向量
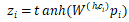
其中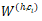
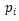
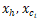
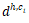
在计算卷积后,对于有 K 个子节点的节点而言,我们得到 K 个向量
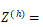
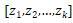
对于 Z 的每一行我们用 Max Pooling 选出最有用的信息。
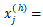
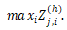
最终得到了该短语的向量表示。
得到向量表示后,计算哪个子树更加合理,这时就也可以用线性层来打分了。
训练
对于 RCNN 可以用最大间距的标准来训练。我们选取打分最高的解析树 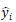
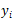
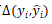
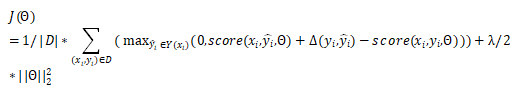
其中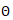
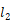
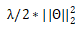
最小化损失的时候,正确的树的打分被提高,错误的树的打分被降低。
实体识别
在使用依存分析得到解析树后,我们就能从树中提取出任意我们想要的短语。
比如我们想要提取出「wants sth」的短语。就可以用如下的算法得到。
def want_phrase(sentence):
result = defaultdict(list)
for token in sentence: # 遍历所有的token
if token.head.lemma == 'want' and token.dep == dobj:
# 如果当前token的依赖指向want及其变形,而且依赖的关系是dobj。那么这是潜在的目标短语
result[token.head].append(token)
for token in sentence: # 遍历所有的token
if token.head in result and token.text == "n't" and token.dep == neg:
# 如果当前的token 是 n't, 依赖指向的词在潜在的目标短语中,而且依赖关系是neg,其实表示的意思是不想要,因此需要从目标短语的集合中剔除。
del result[token.head] # 这是不喜欢的情况
return result
结语
本文介绍了如何在传统的解析算法中用上深度学习的技术。在实践中,深度学习减少了数据工程师大量的编码特征的时间,而且效果比人工提取特征好很多。在解析算法中应用神经网络是一个非常有前景的方向。

本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





