受疫情影响,人工智能顶级学术会议 NeurIPS 2020 将通过线上的形式进行。随着会议召开时间临近,该会议承办的竞赛也陆续揭晓结果。今年新增的电网调度竞赛(Learning To Run a Power Network Challenge)共包含两个赛道:鲁棒能力赛道和泛化能力赛道,经过三个月的激烈比拼,最终来自百度的 PARL 团队拿下全部两个赛道的冠军。同时,这也是该团队在 NeurIPS 上拿下的第三个强化学习赛事冠军,实现三连冠的里程碑。
NeurIPS 2020 电网调度大赛主要是由 RTE(法国电网公司)、EPRI(美国电力研究协会)和 TenneT(德国-荷兰电网公司)等能源企业联合 INRIA(法国国家信息与自动化研究所)、谷歌研究、UCL 和卡塞尔大学等人工智能研究机构共同举办。
赛事共吸引了来自全球的上百支队伍,参赛选手中有来自各个地区的人工智能研究机构,还有来自清华大学、国家电网北美研究院等机构的电网领域专家。本次赛事的举办主旨是探索强化学习在能源调度领域的应用,希望结合强化学习技术实现电网传输的自动化控制,保障整个电网系统在各种突发状况下都能稳定运行。
PARL开源仓库地址:
https://github.com/PaddlePaddle/PARL
竞赛任务
电能是现代化的重要标志之一,与我们每个人的日常生活息息相关。电网在不同地区,国家甚至大洲之间输送电力,是配电的中坚力量,通过向工业和消费者提供可靠的电力来发挥重要的经济和社会作用。但由于受突发状况、自然灾害和人为灾害等不确定性事件的影响,电网系统需要大量的监控人员和电网专家,结合领域知识和历史经验,针对不同突发场景进行干预和维护。
根据主办方发布的竞赛白皮书,电网系统平均每运行一小时便需要实施人工干预操作,不然可能导致局部甚至整个城市的停电。电网调度竞赛的目的便是探索AI在复杂的电网调度场景上的智能决策能力。
本次电网调度竞赛的总体任务目标是维持整个电网仿真系统的供需平衡,并应对各种突发事件。在电网仿真环境运行的每一个时刻,参赛选手需要根据观测到的电网状态(供电/用电数据、电网拓扑结构和电线负载等信息),选择合适的动作(包括变电站拓扑修改和发电厂发电功率修改等)来保持电网的稳定运行。
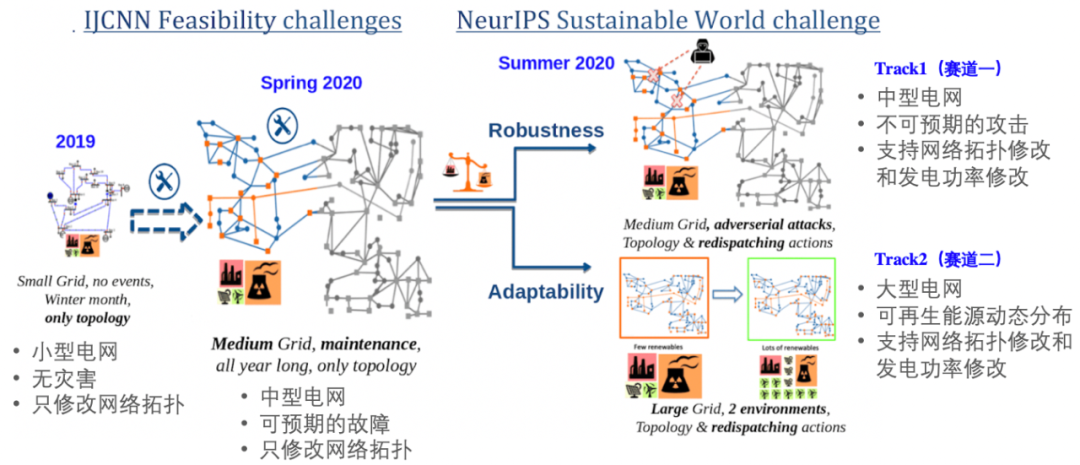
NeurIPS 2020 举办的电网调度赛事相比前两届的电网调度赛事具有更大的挑战难度,不仅电网规模更大,动作空间也更复杂,而且根据电网的真实场景,分别设置了更具有现实意义的鲁棒性(Robustness)和适应性(Adaptability)两个挑战赛道。两个赛道的设置分别如下:
![]()
电网调度系列赛事
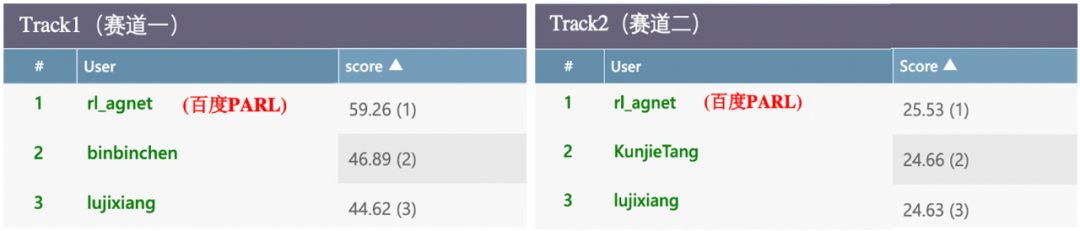
从官方榜单中可以看到,百度 PARL 团队拿下了两个赛道的冠军,在比赛阶段的公榜以及评估阶段的私榜上都名列第一,体现了强大的技术能力,以及针对实际场景的技术实用性。
![]()
百度PARL拿下电网调度大赛双料冠军
在参赛过程中,百度 PARL 团队注意到专家系统方案以及纯强化学习方案很难解决这次的挑战。
传统的专家系统解决方案
主要是利用专家先验知识进行候选动作的筛选,然后根据电网系统的预仿真(simulate)功能来评估不同动作给电网系统带来的影响,这种方案需要有一定的专家经验,并且存在搜索耗时长和无法考虑长远收益等缺点。
纯强化学习方案
虽然可以考虑长远收益,但在大规模电网调度场景中,动作空间复杂,电网系统运行过程中不确定性大,这个方案存在探索难度大和价值函数训练方差大等问题,很难在数万个候选动作中直接选择一个最优动作。
百度 PARL 团队提出了一种融合专家系统和强化学习两者优点的解决方案:
融合专家知识的大规模进化神经网络
,该方案首先采用模仿学习(Imitation learning)来学习专家知识,得到一个用神经网络表示的策略之后,通过进化算法迭代这个策略。
需要注意的是,一般强化学习算法是每次采样一个动作然后根据反馈(reward)进行更新,在该方案的进化算法中,每次会采样多个动作(动作组合)进行优化。当选出动作组合之后,后续的策略依然可以拼接多种专家经验,选出更优的动作。得益于进化算法的黑盒优化特点,整个策略可以直接把电网平稳运行时长作为反馈来更新策略。这个解决方案不仅可以克服强化学习选择单一动作风险高的问题,还可以考虑电网系统的长期奖励,有利于寻找维持电网系统稳定运行的最优解。
![]()
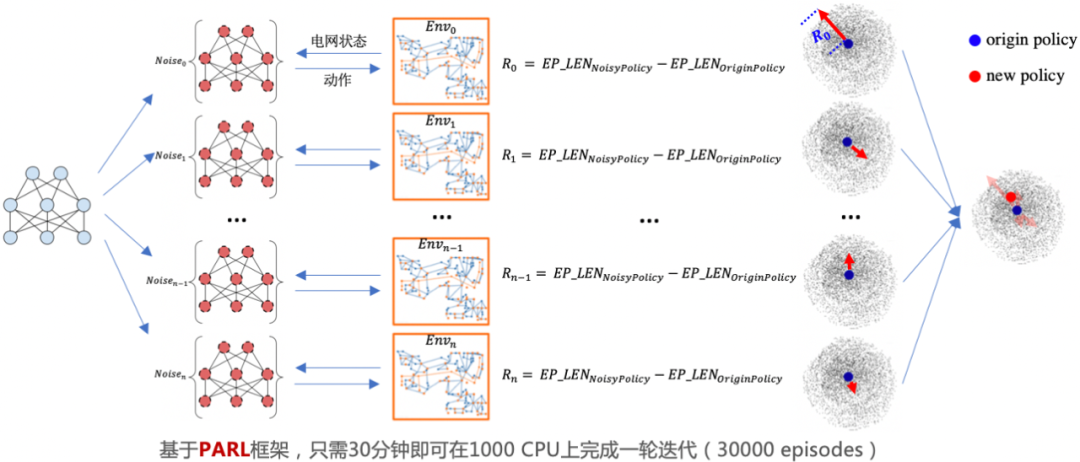
大规模进化算法图示
在大规模进化训练过程中,百度利用 PARL 高性能并行框架同时在
上千 CPU
上对近
500 万参数
的较大规模神经网络进行进化学习。在此过程中,需要先对网络参数进行不同的高斯噪声扰动,然后将扰动后网络作为专家系统新的动作打分模型,分别和电网系统进行交互,并计算噪声扰动后网络相比原始网络在电网系统中的平稳运行时长增益,作为该采样噪声的奖励 R;最后,整合不同噪声方向的奖励来决定下一轮网络参数的进化方向。
据悉,一个这样的电网调度打分模型需要进行 60 万个 episode 迭代, 合计总的电网模拟时长一万多年,包含 10 亿多步探索。而这些仅仅需要 10 个小时左右的时间就能完成。
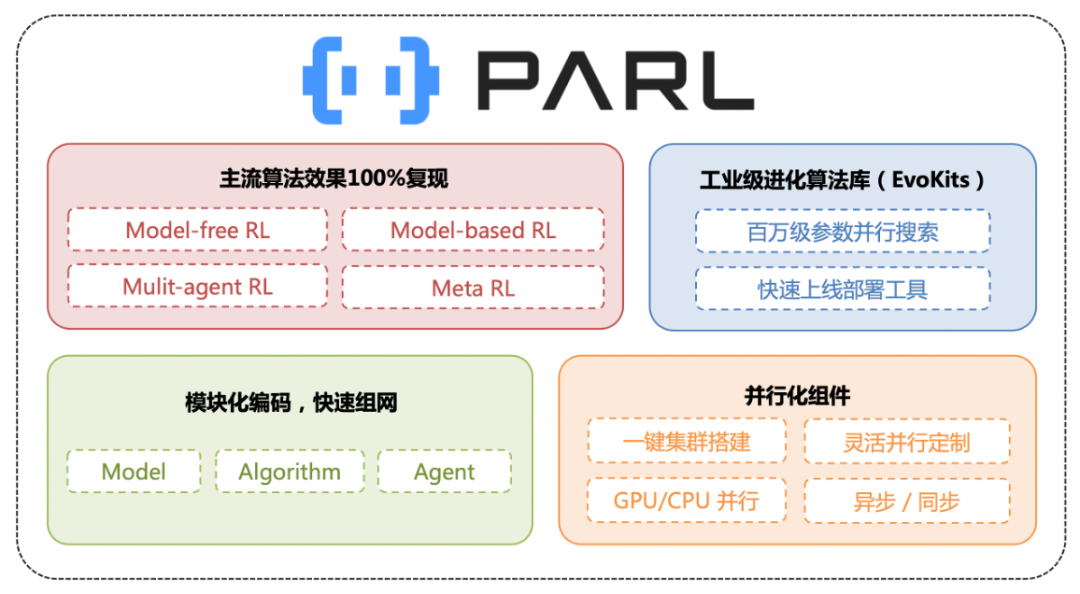
PARL 是基于百度飞桨深度学习平台(PaddlePaddle)自主研发的强化学习框架,汇聚了百度多年来在强化学习领域的技术深耕和产品应用经验。PARL 采用模块式的编码设计,已复现的算法覆盖了包括 Multi-gent、Model-based、Evolution Strategy 和 Distributed RL 等不同方向的主流强化学习算法。
除了强可扩展性和高质量算法复现,PARL 框架更提供了高性能且便捷灵活的并行支持能力。开发者只需要通过数行代码和命令就能搭建起集群,并行调度资源,低成本地实现数百倍的性能加速。正是基于这样的能力,PARL 团队连续拿下了 NeurIPS 2018/2019 仿生人 Learning To Run 挑战和 NeurIPS 2020 L2RPN 挑战三连冠。
据悉,PARL 框架已经应用在信息流推荐、智能打车、智能机器人等多个行业领域,也将致力于把强化学习运用在能源调度、供应链和交通等更多场景,将强化学习独有的决策能力赋予到各行各业。
https://github.com/PaddlePaddle/PARL
https://l2rpn.chalearn.org/competitions
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()