《DA Sequence Labeling using Hierarchical encoder with CRF》阅读笔记
来源:学习ML的皮皮虾
https://zhuanlan.zhihu.com/p/35421555
论文来源:AAAI2018
论文地址:https://arxiv.org/pdf/1709.04250.pdf
本文要解决的问题主要是对话动作的识别问题,对话动作(Dialogue Acts ,简称DA)是指在对话中说话人在说这些话语时的意图。 DA的识别简化了对话语的解释,能够帮助机器理解对话。
DAs的主要应用之一是用来构建一个自然语言对话系统,了解DA过去的话语有助于对当前的话语预测走向,从而当前回合生成的话语添加了限制条件。
例如,如果之前的话语是问候类型,那么下一个话语最有可能是相同类型的,即问候语。下图展示的一个会话片段,显示了这些DA之间的依赖关系。
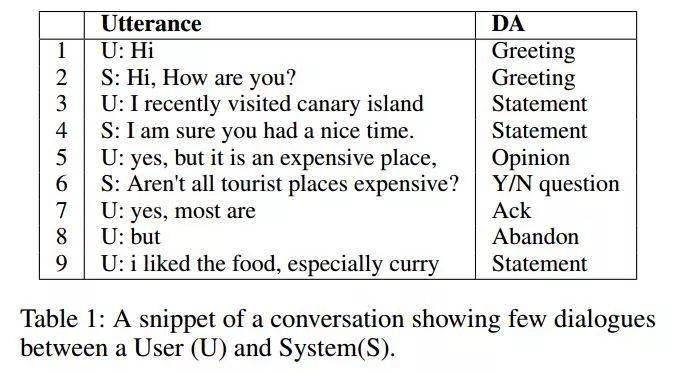
本文将DA识别的问题看做为一个序列标注的问题,通过采用bi-lstm作为基础单元的层级RNN网络提取特征(词级别,话语级别,会话级别,个人认为这里因为多轮对话本身相对丰富的原因无字符级别),顶层通过CRF层将每个话语识别为对应的DA。
采用CRF作为输出层的原因是不仅能够捕捉到语句之间的依存关系,还能够兼顾到DA之间的依存关系(作者论文的立足点)。实验证明在Switchboard和Meeting Recorder Dialogue Act数据及上分别比SoTA提高了2.2%,4.1%。
本文的主要贡献:
采用了一个层级的Bi-LSTM-CRF模型,同时捕捉DA和话语之间的依存关系;
在两个数据及上做了对比,其中一个数据集上已经很接近人工标注了;
分别做了加入语言特征和intra-attention加入原始文本的方法,实验结果显示除了收敛速度加快对模型提升并没有什么用。
Models
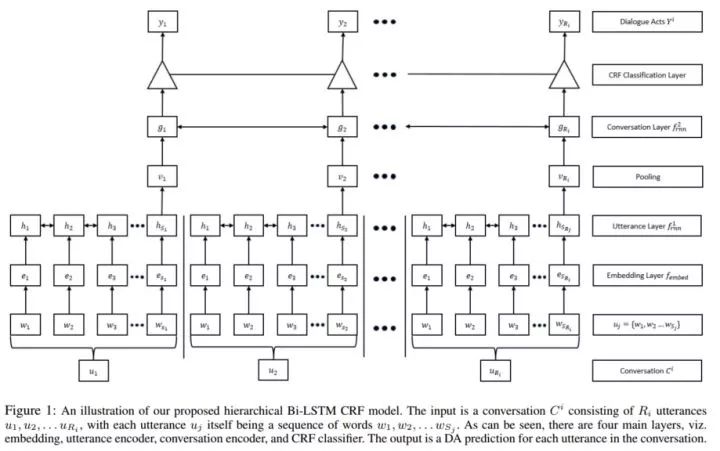
整个回话可以被看做一个非常长的词链,这样会带来在极限长度下的题图消失/爆炸问题。为了消除这个问题,本文采用了层级的递归编码。
编码器第一层采用Bi-LSTM对话语中的每个单词进行编码,通过一个LastPooling(最后一个节点的隐层神经元状态理论上编码了完全的的句子语义),输入第二个Bi-LSTM层作为对话层级的编码,并将其输出作为CRF层的输入,以捕捉标签间的依赖关系,同时捕捉话语和DA标签间的依存关系。
Hierarchical Recurrent Encoder
对于每个话语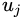
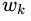
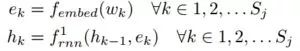
其中,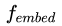
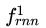
每个话语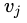
得到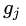
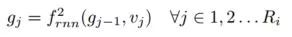
Linear Chain CRF
为了捕捉DA标签之间的依存关系,采用了线性链CRF,给出标签预测的概率:
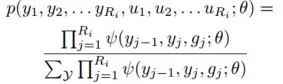
其中, 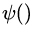
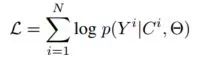
Experiments
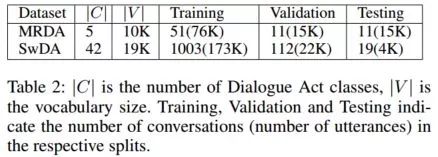
Datasets:MRDA SwDA5
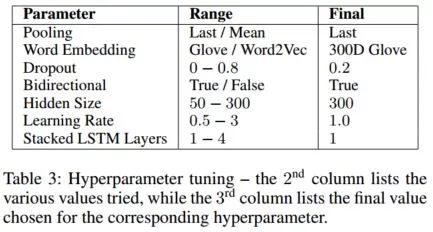
Hyperparameter Tuning
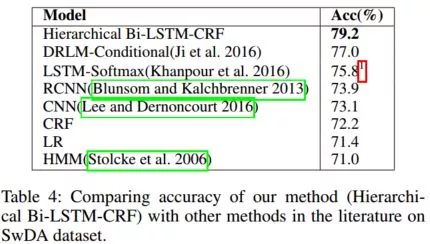

上图中,行表示真正的标签,列表示预测的标签。文中提到通过上图的标签分析,一部分原因是ground truth 中的bias,一部分是标注者的主观判断。
Effect of Hierarchy and Label Dependency
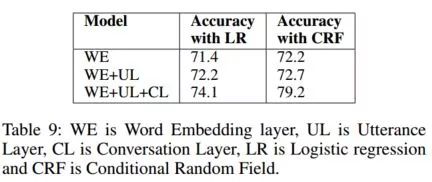
从上表中可以清晰地看出每一层对最终结果的贡献。
Effect of Linguistic Features and Context

语言特征和文本信息在之前的一些研究中都对模型效果的提升产生了一定的贡献。但在这个实验中加入之后并没有产生预期的效果,作者认为本文中的模型已经学到了大多数需要的信息。
Conclusion
本文显示了模型迁移在不同问题上的强大作用,通过丰富的对比试验来证明模型有效性的方法也值得我们学习。
*推荐文章*
PS.极市平台正寻求与开发者视觉算法的合作,欢迎联系小助手(微信:Extreme-Vision)沟通合作~ 填写表单http://form.mikecrm.com/wcotd9,即可加入极市CV开发者群,与CV大牛切磋交流~





