UT Austin&快手提出Once-for-All对抗学习算法实现运行时可调节模型鲁棒性

作者:UT Austin三年级博士生 王浩韬

NeurIPS 2020 文章专题
第·8·期



论文链接:
https://arxiv.org/abs/2010.11828
代码链接:
https://github.com/VITA-Group/Once-for-All-Adversarial-Training
一、 背景和动机
深度神经网络广为人知地容易被对抗样本攻击。随着深度网络在风险敏感场景(比如自动驾驶、生物特征识别等任务)下逐渐广泛的应用,衡量模型性能时不仅要考虑模型在正常样本上的准确率 (accuracy),同时也要考虑模型针对对抗样本的鲁棒性(robustness)。
在众多提升模型鲁棒性的算法中,对抗训练 (adversarial training) 的效果是最顶尖的。虽然传统对抗防御方法(包括对抗训练)可以提升鲁棒性,但是他们也有明显的缺点:大多数对抗防御方法(包括对抗训练)以牺牲模型准确率为代价获得鲁棒性。这些算法在不同的预设超参数下训练来实现在准确率和鲁棒性之间不同程度的折衷(trade-off)。
然而在实际应用中,用户对于模型准确率和鲁棒性的要求不是一成不变的,而是会随着情境不同而变化。因此,实际应用中的模型需要能够在运行时灵活调整模型准确率与鲁棒性之间折衷度。不幸的是,大多数对抗防御算法的训练耗时很长,因此通过在不同预设参数下训练多组不同折衷度的模型是难以实现的。
基于上述原因,本文首次提出并解决一个新的问题:如何快速原位调整一个已经训练好的模型,无需在不同预设参数下多次训练,即可使其实现在运行时灵活调节准确率与鲁棒性之间的折衷度?
二、方法
1. 核心思路:训练样本与模型条件参数的联合采样
传统对抗学习算法的损失函数为如下形式,其中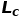
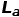
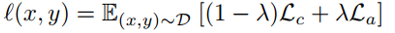
在我们提出的Once-for-all Adversarial Training (OAT) 框架中,超参数λ同时作为网络的条件控制参数(如图1所示)。在训练时,训练样本和模型条件参数λ联合采样。OAT损失函数如下,其中
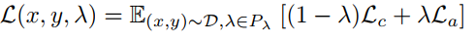
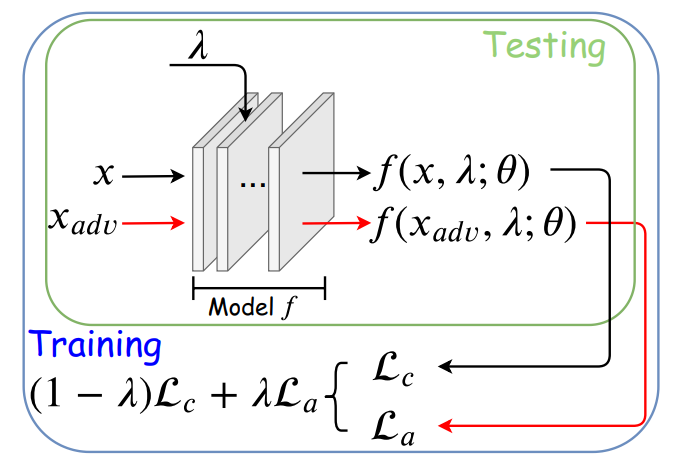
2. 独特的技术瓶颈与解决方案:标准样本和对抗样本统计特征上的差异
通过初步OAT框架得到的结果虽然可以实现通过调整λ来调整折衷度,但是可实现的折衷度远远达不到使用固定λ训练得到的模型效果好。通过观察,我们发现这是由于标准样本和对抗样本在统计特征上存在明显差异(参见图2)而导致的。
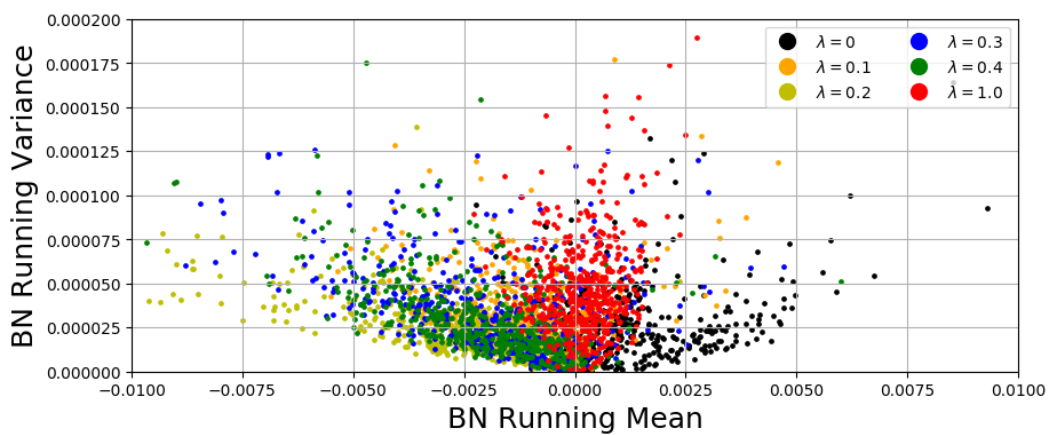
图2. CIFAR10数据集上正常样本 (λ=0) 和对抗样本 (λ≠0) 的Batch Normalization层的均值 (x轴) 和方差 (y轴)。可见正常样本与对抗样本统计分布差异很大。
基于上述观察,我们利用双Batch Normalization (BN) 模型结构[1] (参见图3) 来解耦正常样本和对抗样本的BN统计参数:

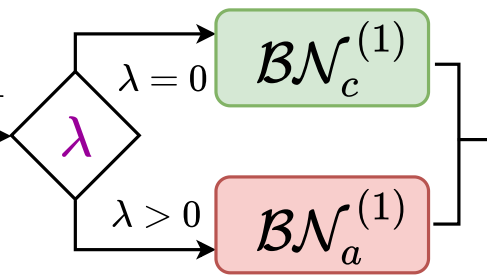
图3. 双BN结构:每个样本根据λ值的不同选取不同的传播路径。
3. 从OAT到OATS:加入模型运行效率作为第三个折衷维度
很多资源紧缺型设备(比如移动端设备,智能摄像头,户外机器人等)上部署的深度网络对与模型准确度 (accuracy),鲁棒性 (robustness) 以及运行效率 (efficiency) 都有严格要求。并且近期工作[2][3]指出在同一个模型上同时实现三者的重要性。
鉴于此,我们将OAT框架拓展到Once-for-all Adversarial Training and Slimming (OATS) 框架,来实现自由调整模型在准确度、鲁棒性、运行效率三者之间的运行时折衷的目的。我们借鉴Slimmable Network [4]中的switchable BN来实现模型宽度的调整。OATS框架如图4所示。
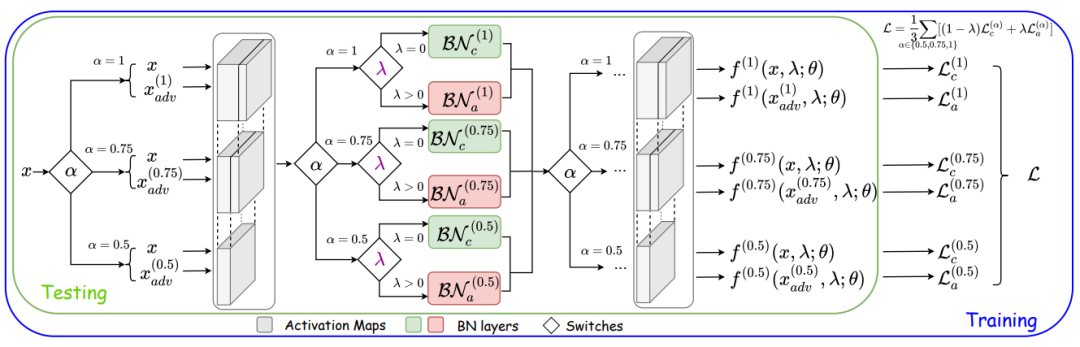
图4. OATS框架。超参数λ与α(神经网络宽度参数)均为模型输入参数。λ控制模型使用
OATS算法概要如下:

三、实验结果
在双BN (dual BN) 的帮助下,OAT算法只需一次训练即可得到与固定不同λ训练多个模型 (PGD-AT) 相近甚至更好的准确率-鲁棒性帕累托最优 (Pareto Frontier) 曲线,如图5所示。
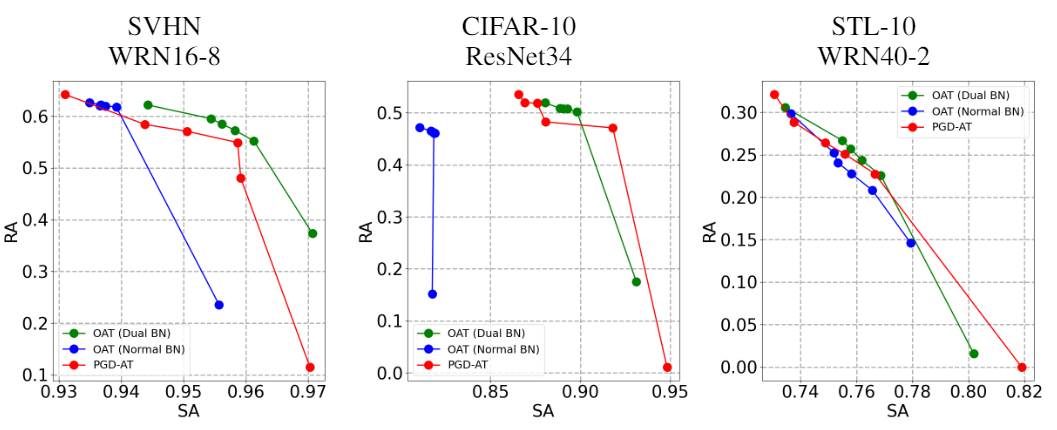
图5. 准确率 (SA) -鲁棒性 (RA) 帕累托最优 (Pareto Frontier) 曲线。OAT比传统固定λ的对抗训练算法 (PGD-AT) 效果相当甚至更好。
OATS框架下也有相同的结论,如图6所示:
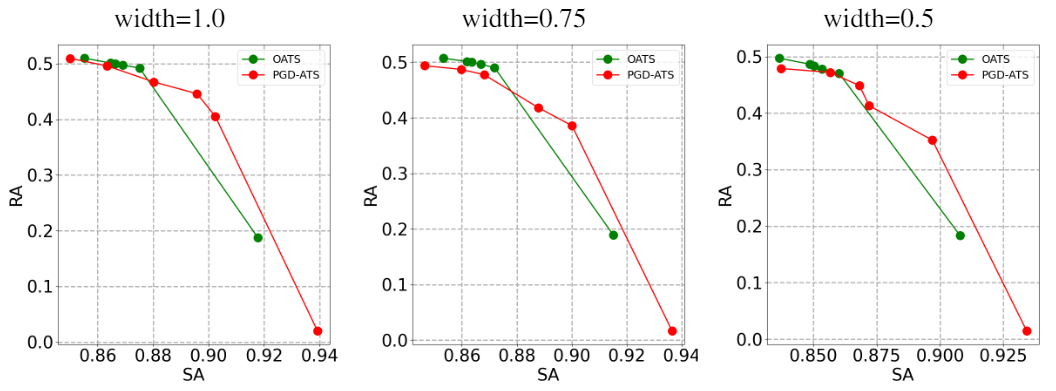
图6. 准确率 (SA) -鲁棒性 (RA) 帕累托最优 (Pareto Frontier) 曲线。OATS对比传统固定λ的对抗训练算法 (PGD-ATS) 效果相当甚至更好。
更多实验结果与可视化结果请参看原文。
四、总结
本文尝试解决一个新的问题:如何在运行时自由原位调整模型准确率和鲁棒性之间的折衷度。我们提出的OAT算法基于创新性的模型条件化对抗训练算法,并且使用双BN模型来解决标准样本和对抗样本之间统计特征冲突的问题。我们进一步将OAT拓展到OATS框架,实现了在运行时自由原位调整准确率、鲁棒性、运行效率三者之间折衷。大量实验验证了我们方法的有效性。
点击标题阅读往期精彩👇
NeurlPS 2020 论文解读 ●●
// 1
// 2
// 3
// 4
// 5
// 6
// 7
将门TechBeat社区
点击下图报名!
👇


扫码观看!
本周上新!

关于我“门”
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给“门”:
bp@thejiangmen.com

点击右上角,把文章分享到朋友圈

扫二维码|关注我们
让创新获得认可!
微信号:thejiangmen
点击“❀在看”,让更多朋友们看到吧~
