XLNet详解

XLNet论文推荐语:
BERT本身很有效,但它也存在一些问题,比如不能用于生成、以及训练数据和测试数据的不一致(Discrepancy)。在本文中,我们重点介绍比BERT更强大的预训练模型XLNet,它为了达到真正的双向学习,采用了Permutation语言模型、以及使用了双流自注意力机制,并结合了Transformer-XL的相对位置编码。
XLNet的论文:
Yang Z, Dai Z, Yang Y, et al. Xlnet: Generalized autoregressive pretraining for language understanding[C]//Advances in neural information processing systems. 2019: 5754-5764.
目录:
1. Unsupervised Pre-training
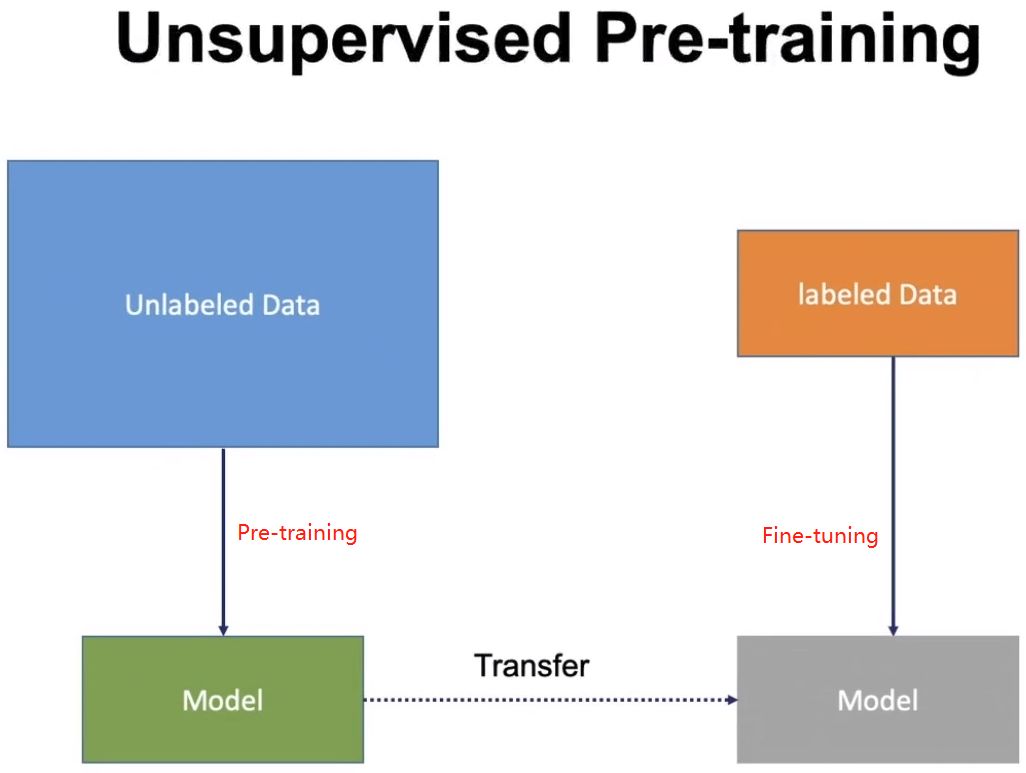
目前神经网络在进行训练的时候基本都是基于后向传播(Back Propagation,BP)算法,通过对网络模型参数进行随机初始化,然后利用优化算法优化模型参数。但是在标注数据很少的情况下,通过神经网络训练出的模型往往精度有限,“预训练”则能够很好地解决这个问题,并且对一词多义进行建模。
预训练是通过大量无标注的语言文本进行语言模型的训练,得到一套模型参数,利用这套参数对模型进行初始化,再根据具体任务在现有语言模型的基础上进行精调。预训练的方法在自然语言处理的分类和标记任务中,都被证明拥有更好的效果。目前,热门的预训练方法主要有:ELMo、OpenAI GPT、BERT和XLNet等。
在NLP中,早期的无监督预训练模型主要是word2vec(SkipGram、CBOW)和Glove,这些模型都使用了不考虑上下文嵌入的方式得到词向量。

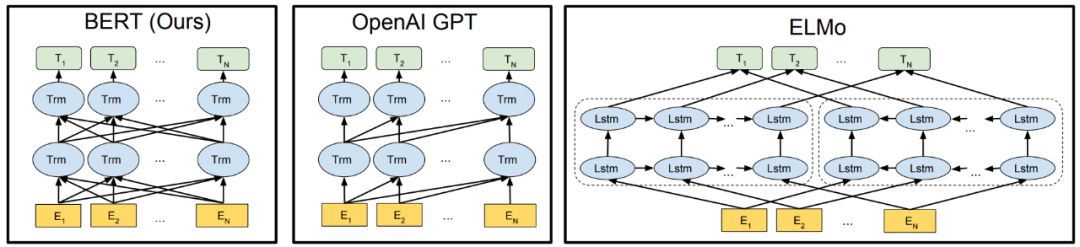
在2018年初,AllenNLP 和华盛顿大学的研究人员在《Deep contextualized word representations》一文中提出了ELMo。相较于传统的使用词嵌入(Word embedding)对词语进行表示,得到每个词唯一固定的词向量,ELMo 利用预训练好的双向语言模型,根据具体输入从该语言模型中可以得到在文本中该词语的表示。在进行有监督的 NLP 任务时,可以将 ELMo 直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。这篇论文提出的 ELMo 模型是 2013 年以来 Embedding 领域非常精彩的转折点,并在 2018 年及以后的很长一段时间里掀起了迁移学习在 NLP 领域的风潮。简单来说,ELMo 是一种基于语境的深度词表示模型(Word Representation Model),它可以捕获单词的复杂特征(词性句法),也可以解决同一个单词在不同语境下的不同表示(语义)。
在ELMo的基础之上,OpenAI的研究人员在《Improving Language Understanding by Generative Pre-Training》提出了OpenAI GPT。与ELMo为每一个词语提供一个显式的词向量不同,OpenAI GPT能够学习一个通用的表示,使其能够在大量任务上进行应用。在处理具体任务时,OpenAI GPT 不需要再重新对任务构建新的模型结构,而是直接在 Transformer 这个语言模型上的最后一层接上 softmax 作为任务输出层,再对这整个模型进行微调。GPT 采用无监督学习的 Pre-training 充分利用大量未标注的文本数据,利用监督学习的 Fine-tuning 来适配具体的 NLP 任务(如机器翻译等)。
ELMo和OpenAI GPT这两种预训练语言表示方法都是使用单向的语言模型来学习语言表示,而Google提出的BERT则实现了双向学习,并得到了更好的训练效果。具体而言,BERT使用Transformer的编码器作为语言模型,并在语言模型训练时提出了两个新的目标:一个是 token-level 级别的MLM(Masked Language Model)和一个是 sentence-level 级别的NSP(Next Sentence Prediction)。MLM是指在输入的词序列中,随机的遮挡上 15% 的词,并对遮挡部分的词语进行双向预测。为了让模型能够学习到句子间关系,研究人员提出了让模型对即将出现的句子进行预测:对连续句子的正误进行二元分类,再对其取和求似然。
自从ELMo、GPT和BERT出现之后,pretrain+finetune的两段式训练方法,成为NLP任务的主流做法。在公开的语料库上对大模型进行自监督或者无监督的预训练,然后在特定任务的语料库上对模型做微调。本文介绍另外一篇类似的算法XLNet。
相关论文:
【1】Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
【2】Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf, 2018.
【3】Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
2. AR与AE语言模型
-
AR:Autoregressive Language Modeling -
AE:Autoencoding Language Modeling

AR语言模型:指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表有 ELMO, GPT等。
forward:
backward:
AE语言模型:通过上下文信息来预测被mask的token,代表有 BERT , Word2Vec(CBOW) 。
二者有着它们各自的优缺点:
AR 语言模型:
-
缺点: 它只能利用单向语义而不能同时利用上下文信息。ELMO 通过双向都做AR 模型,然后进行拼接,但从结果来看,效果并不是太好。 -
优点: 对生成模型友好,天然符合生成式任务的生成过程。这也是为什么 GPT 能够编故事的原因。
AE 语言模型:
-
缺点: 由于训练中采用了 [MASK]标记,导致预训练与微调阶段不一致的问题。BERT独立性假设问题,即没有对被遮掩(Mask)的 token 之间的关系进行学习。此外对于生成式问题, AE 模型也显得捉襟见肘。 -
优点: 能够很好的编码上下文语义信息(即考虑句子的双向信息), 在自然语言理解相关的下游任务上表现突出。
所以,AR方式所带来的自回归性学习了预测 token 之间的依赖,这是 BERT 所没有的;而 BERT 的AE方式带来的对深层次双向信息的学习,却又是像ELMo还有GPT单向语言模型所没有的,不管是有没有替换 [MASK]。于是,自然就会想,如何将两者的优点统一起来?这时就到了XLNet登场的时间。
3. XLNet提出的方法
3.1 Permutation Language Model
作者发现,只要在 AR中再加入一个步骤,就能够完美地将AR与AE的优点统一起来,那就是提出Permutation Language Model(PLM)。
具体实现方式是,通过随机取一句话的一种排列,然后将末尾一定量的词给遮掩(和 BERT 里的直接替换 [MASK] 有些不同)掉,最后用 AR 的方式来按照这种排列依次预测被遮掩掉的词。
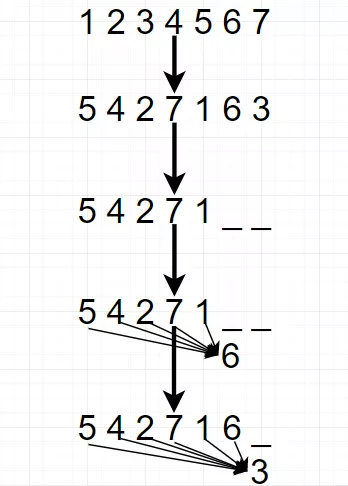
我们可以发现通过随机取排列(Permutation)中的一种,就能非常巧妙地通过 AR 的单向方式来习得双向信息了。
论文中 Permutation 具体的实现方式是通过直接对 Transformer 的 Attention Mask 进行操作。
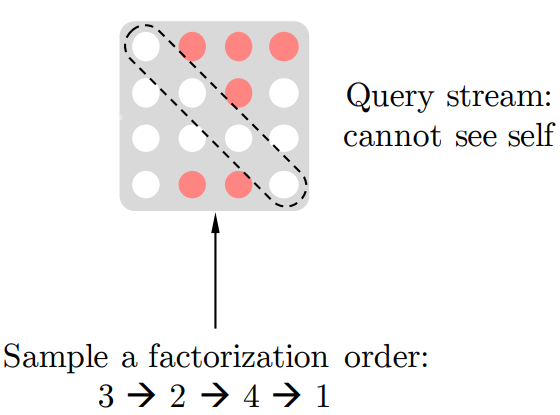
比如说序号依次为 1234 的句子,先随机取一种排列3241。于是根据这个排列我们就做出类似上图的 Attention Mask。先看第1行,因为在新的排列方式中 1 在最后一个,根据从左到右 AR 方式,1 就能看到 234 全部,于是第一行的 234 位置是红色的(没有遮盖掉,会用到),以此类推。第2行,因为 2 在新排列是第二个,只能看到 3,于是 3 位置是红色。第 3 行,因为 3 在第一个,看不到其他位置,所以全部遮盖掉...
3.2 Two-Stream Self-Attention
为了实现 Permutation 加上 AR 预测过程,首先我们会发现,打乱顺序后位置信息非常重要,同时对每个位置来说,需要预测的是内容信息(对应位置的词),于是输入就不能包含内容信息,不然模型学不到东西,只需要直接从输入复制到输出就好了。
于是这里就造成了位置信息与内容信息的割裂,因此在 BERT 这样的位置信息加内容信息输入 Self-Attention (自注意力) 的流(Stream)之外,作者还增加了另一个只有位置信息作为 Self-Attention 中 Query 输入的流。文中将前者称为 Content Stream,而后者称为 Query Stream。
这样就能利用 Query Stream 在对需要预测位置进行预测的同时,又不会泄露当前位置的内容信息。具体操作就是用两组隐状态 和 。其中 只有位置信息,作为 Self-Attention 里的 。 包含内容信息,则作为 和 。具体表示如下图所示:
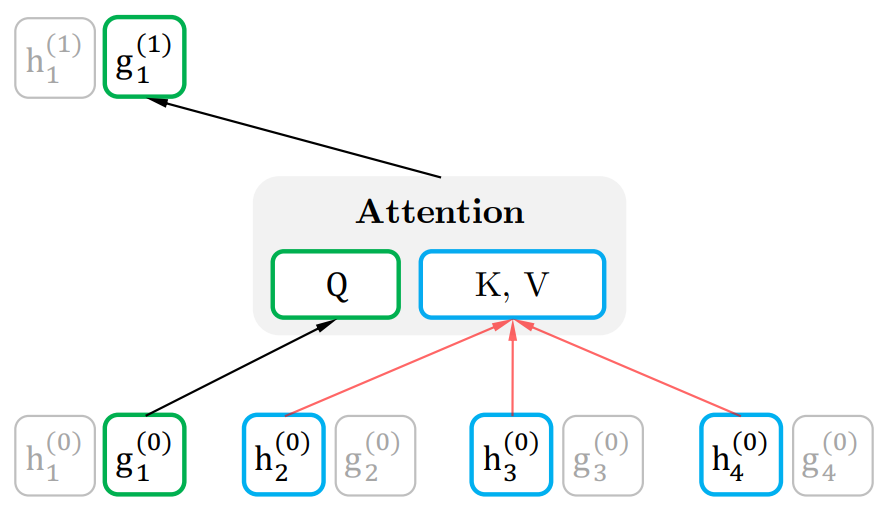
图:Query stream attention
假如,模型只有一层的话,其实这样只有 Query Stream 就已经够了。但如果将层数加上去的话,为了取得更高层的 h,于是就需要 Content Stream 了。h 同时作为 Q K V。如下图所示:
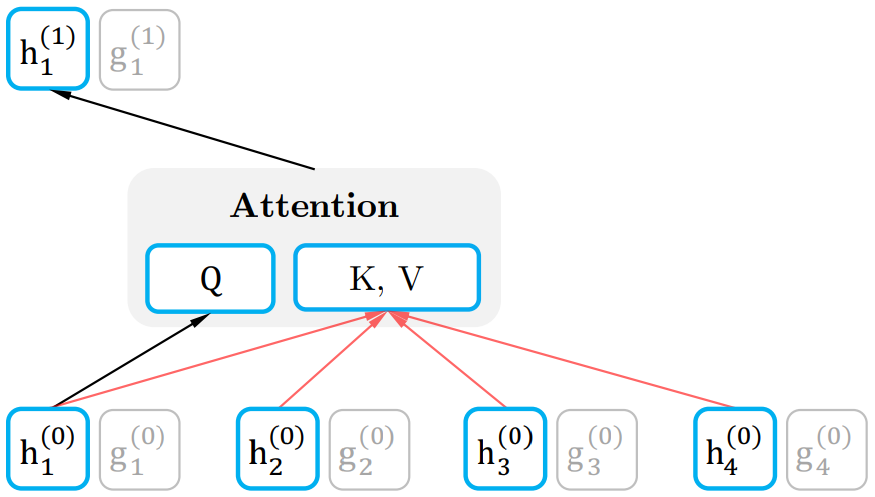
图:Content stream attention
于是组合起来就是这样:
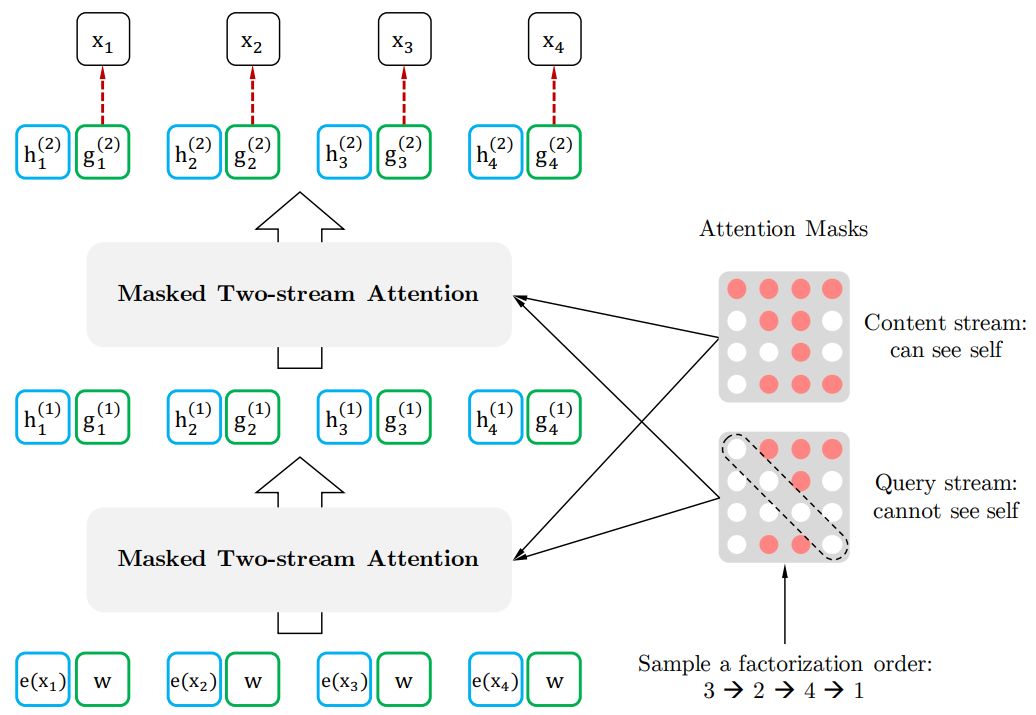
图:基于双流注意力机制的排序语言模型
上图中我们需要理解两点:
-
第一点,最下面一层蓝色的 Content Stream 的输入是 ,这个很好懂就是 对应的词向量 (Embedding),不同词对应不同向量,但看旁边绿色的 Query Stream,就会觉得很奇怪,为什么都是一样的 ?这个和Relative Positional Encoding 有关。 -
第二点,Query stream attention图中为了便于说明,只将当前位置之外的 作为 和 ,但实际上实现中应该是所有时序上的 都作为 和 ,最后再交给上图中的 Query stream 的 Attention Mask 来完成位置的遮盖。
3.3 Partial Prediction
XLNet还使用了部分预测(Partial Prediction)的方法。因为LM是从第一个Token预测到最后一个Token,在预测的起始阶段,上文信息很少而不足以支持Token的预测,这样可能会对分布产生误导,从而使得模型收敛变慢。为此,XLNet只预测后面一部分的Token,而把前面的所有Token都当作上下文。具体来说,对长度为 的句子,我们选取一个超参数 ,使得后面 的Token用来预测,前面的 的Token用作上下文。注意, 越大,上下文越多,模型预测得就越精确。
例如: 只预测 和 ,把 和 当作上下文信息。
3.4 Transformer-XL
为什么会提出Transformer-XL呢?它的提出主要是为了解决transformer的问题。我们首先分析一下RNN以及Transformer的优缺点。
RNN:
-
优点:支持可变长,支持记忆,有序列顺序关系。 -
缺点:gradient vanish,耗时无法并行。
Transformer:
-
优点:并行,考虑到sequence的long term dependency信息(相对于RNN),可解释性。 -
缺点:句子与句子之间的关系,batch size也不能很大,空间占用大(因为每个encoder的score matrix(sequenceLen*sequecenLen是 的空间复杂度) 如下图:
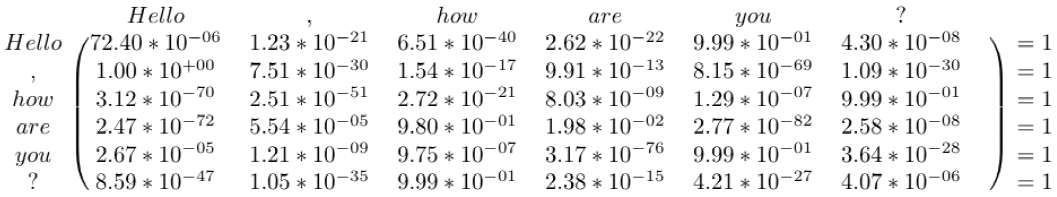
Transformer编码固定长度的上下文,即将一个长的文本序列截断为几百个字符的固定长度片段(segment),然后分别编码每个片段,片段之间没有任何的信息交互。比如BERT,序列长度的极限一般在 。因此Transformer-XL提出的动机总结如下:
-
Transformer无法建模超过固定长度的依赖关系,对长文本编码效果差。 -
Transformer把要处理的文本分割成等长的片段,通常不考虑句子(语义)边界,导致上下文碎片化(context fragmentation)。通俗来讲,一个完整的句子在分割后,一半在前面的片段,一半在后面的片段。
《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》论文围绕如何建模长距离依赖,提出Transformer-XL(XL是extra long的意思):
-
提出片段级循环机制(segment-level recurrence mechanism),引入一个记忆(memory)模块(类似于cache或cell),循环用来建模片段之间的联系。这使得长距离依赖的建模成为可能;也使得片段之间产生交互,解决上下文碎片化问题。 -
提出相对位置编码机制(relative position embedding scheme),代替绝对位置编码。在memory的循环计算过程中,避免时序混淆,位置编码可重用。
Transformer-XL总结: 片段级循环机制为了解决编码长距离依赖和上下文碎片化,相对位置编码机制为了实现片段级循环机制而提出,解决可能出现的时序混淆问题。也可以简单的理解Transformer-XL=Transformer + RNN,即segment-wise的RNN模型,但是RNN模型的组件是Transformer的Encoder模块。
相关论文:
【1】Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
【2】Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive language models beyond a fixed-length context[J]. arXiv preprint arXiv:1901.02860, 2019.
3.5 Relative Segment Encodings
3.5.1 Absolute Positional Encoding
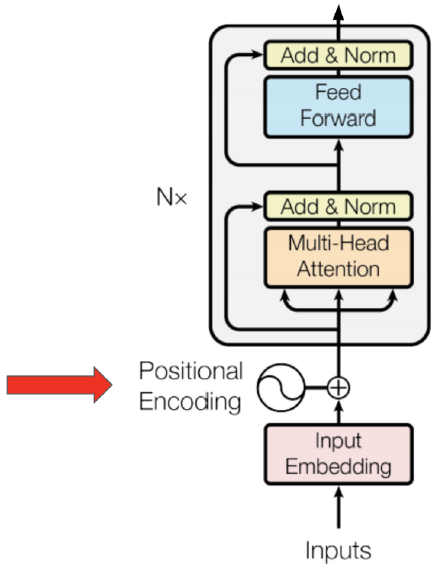
Transformer使用的是绝对位置编码,如果我们继续使用Absolute Positional Encoding的话,对于所有的sequence序列,只要这个字在序列中的位置一样的话,它的position encoding也会一样,这样的话,对于我们concat之后的输出,我们无法区别每个字的位置。如下图:The和that的position encoding完全一样,模型无法区分两者位置区别。
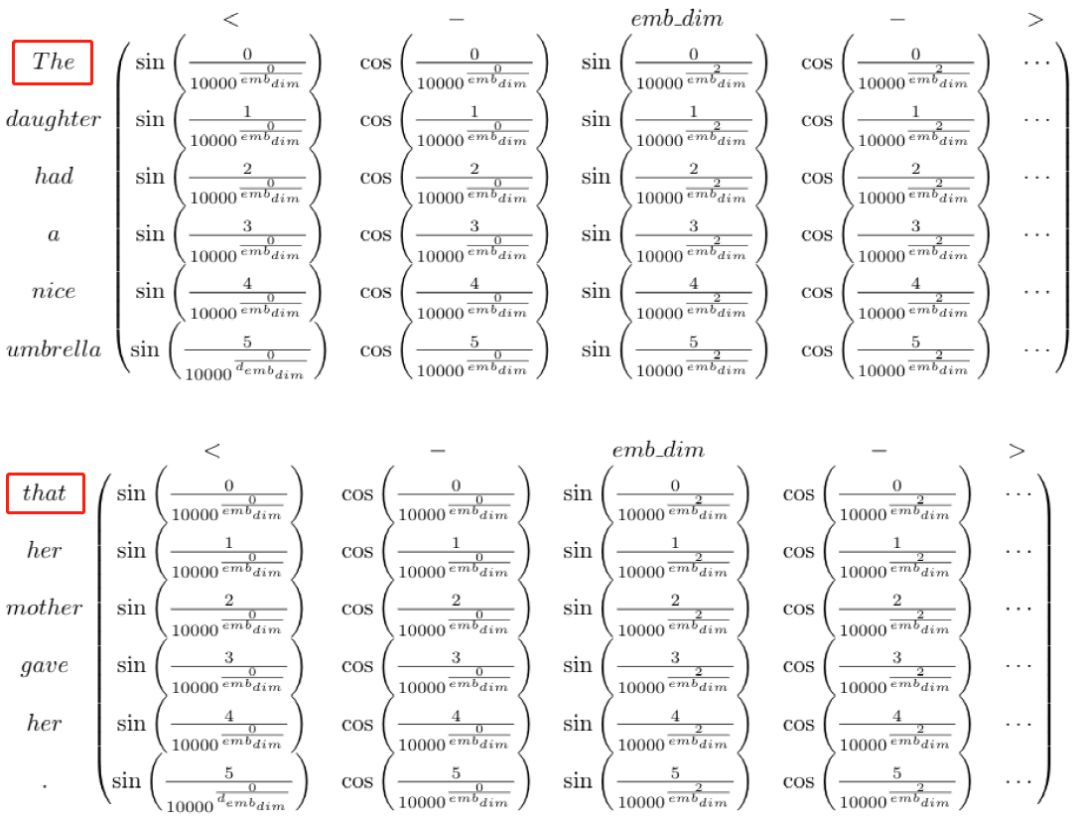
3.5.2 Relative Position Encoding
所以Transformer-XL 首先分析了position encoding在计算中的作用,然后根据这个结果将交互项转化为relative position encoding。
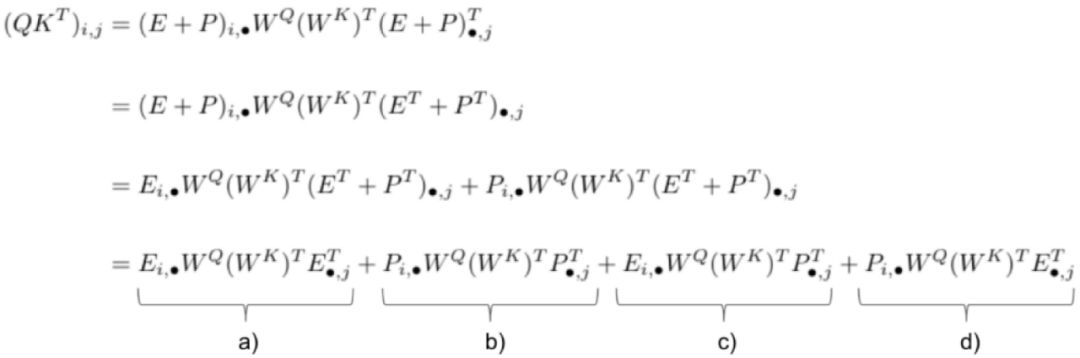
The notation (i, •) refers to the entire row i and (•, j) to the entire column j 。经过计算,这个式子可以分为4项。
-
a) 这一项中没有包含 位置信息,代表的是在第 行的字应该对第 列的字提供多大的注意力。这是不管他们两个字的位置信息的。 -
b) 这一项捕获的是模型的global attention,指的是一个字在position 应该要对 position 付出多大的注意力。例如两个字的位置越远,期望它们之间的注意力越小。 -
c) 这一项捕获的是在row 的字对其他位置的关注信息,例如在position 是一个字"狗", 应该要对 这个位置特别注意,否则可能出现 是“热”, 出现是“热狗”的情况。 -
d) 这个是c) 的逆向表示,指的是 的字要关注位置 的字。
根据这个观测,为了转化relative position, 通过了解了每一项的意义,特别是了解了两个字的相对位置对这个score的作用。我们将 b), c) and d) 替换为如下式子:
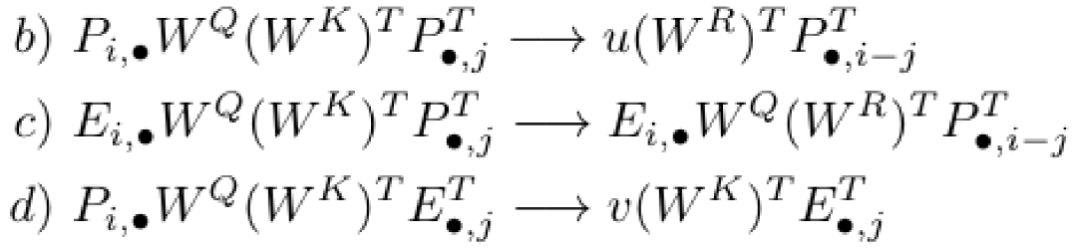
我们可以看到主要的变化:
-
我们将使用的是相对的position encoding i.e. 取消 而采用 相对位置。 -
每次使用 ,我们都将 替换为 (两者的形状相同)。这是为了区别 (仍使用) 和 ,使得两者可以各自捕获有意义的位置信息而不会相互干预,因为 和 相匹配出现,而 和 相匹配出现 。 -
这一项被替代为 和 ,这两个向量的维度为 。因为我们使用的是相对位置编码,所以我们并不需要提供绝对位置 。
所以 的公式被替换为:
3.5.3 Relative Segment Encodings
为了通过输入形式 来处理句子对任务,于是需要加入标识 A 句和 B 句的段信息。BERT 里面很简单,直接准备两个向量,一个加到 A 句上,一个加到 B 句上。
但当这个遇上 Segment Recurrence Mechanism 时,和位置向量一样,也出问题了。万一出现了明明不是一句,但是相同了怎么办,于是我们就需要最后一个技巧,同样准备两个向量, 和 分别表示在一句话内和不在一句话内。
具体实现是在计算 attention 的时候加入一项:
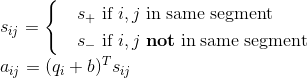
当 和 位置在同一段里就用 ,反之用 ,在 attention 计算权重的时候加入额外项。
4. 总结
从XLNet论文的结果来看,其在问答、文本分类、自然语言理解等任务上大幅超越BERT。除了相比BERT增加了训练集之外,XLNet也在模型设计上有较大的改进,比如引入了新的优化目标Permutation Language Modeling(PLM),使用了双流自注意力机制(Two-Stream Self Attention, TSSA)和与之匹配的Mask技巧。此外,XLNet还使用了Transformer-XL作为Backbone,也使用了Transformer-XL的相对位置编码。所以,相比BERT,XLNet对长文本的支持更加有效。这些改进为BERT类预训练模型难以进行生成任务的问题提供了一个解决思路。可以期待,在不久的将来,NLP预训练模型能够突破一系列生成任务,实现NLP模型结构化的统一。
5. Reference
【1】Larochelle H, Murray I. The neural autoregressive distribution estimator[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. 2011: 29-37.
【2】Uria B, Côté M A, Gregor K, et al. Neural autoregressive distribution estimation[J]. The Journal of Machine Learning Research, 2016, 17(1): 7184-7220.
【3】The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning),Jay Alammar'blog,地址:https://jalammar.github.io/illustrated-bert/
【4】【AI模型】最通俗易懂的XLNet详解,地址:https://www.bilibili.com/video/av73657563?p=1
【5】Dissecting Transformer-XL,地址:https://mc.ai/dissecting-transformer-xl/
【6】你应该知道的transformer - Don.hub的文章 - 知乎 https://zhuanlan.zhihu.com/p/102591791
【7】飞跃芝麻街:XLNet 详解 - Andy Yang的文章 - 知乎 https://zhuanlan.zhihu.com/p/71916499
【8】就最近看的paper谈谈预训练语言模型发展 - 老宋的茶书会的文章 - 知乎 https://zhuanlan.zhihu.com/p/79371603
【9】XLNet:运行机制及和Bert的异同比较 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/70257427
【10】请收好这份NLP热门词汇解读:预训练、Transformer、无监督机器翻译 - 七月在线 七仔的文章 - 知乎 https://zhuanlan.zhihu.com/p/59158735
【11】论文笔记 —— Transformer-XL - 谢玉强的文章 - 知乎 https://zhuanlan.zhihu.com/p/70745925
【12】香侬读 | XLnet:比Bert更强大的预训练模型 - 香侬科技的文章 - 知乎 https://zhuanlan.zhihu.com/p/71759544
【13】从BERT到XLNet,李文哲B站直播视频,地址:https://www.bilibili.com/video/av89296151?p=5
推荐阅读
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




