统计挖掘的一些事一些情(一)


浩彬老撕,R语言中文社区特邀作者。
个人公众号:探数寻理

在这里首先要感谢苍天,感谢亚里士多德,感谢维克托·迈尔·舍恩伯格,让“大数据”成为了年度热词,咱们统计学同仁终于体验了一把“农奴翻身做主人”!
在这两千多年的历史当中,咱们这里涌现出一批又一批的风流人物,如卡尔皮尔逊(公认的统计学之父),费舍尔(现代统计学的奠基人之一),贝叶斯(贝叶斯方法对当今的数据挖掘领域影响依然非常的广非常的大,另外概率统计学出现的“频率学派”和“贝叶斯学派”的至今争论的恩恩怨怨还在继续)、高尔顿(这位可是达尔文的表弟)、戈赛特(嗯,这位最早从事的可是酿酒行业,提出了著名的t分布)。

虽然这些只是某一方面的应用,但是我们可以看到,广大人民群众对于利用数据的热情是大大的!
上面说的建立统计学习模型,简单是指利用一个或多个输入变量(一般也称为自变量,预测变量)通过拟合适当的关系式来预测输出变量(也称因变量,响应变量)的方法。其中f(x)是我们希望探求的关系式,但一般来说是固定但未知。尽管f(x)未知,但是我们的目标就是利用一系列的统计/数据挖掘方法来尽可能求出接近f(x)的形式,这个形式可以是一个简单的线性回归模型(y=a+bx),也可能是一个曲线形式(y=a+b(x的平方)),当然也有可能是一个神经网络模型或者一个决策树模型。
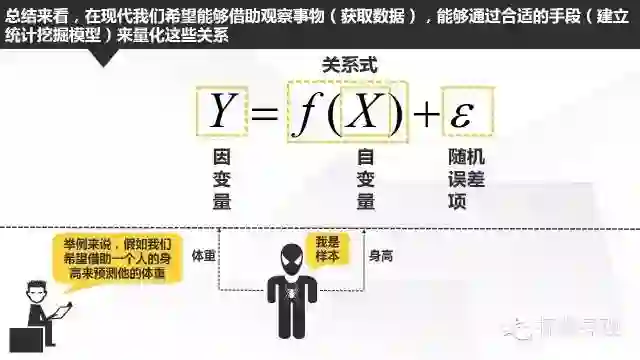
而对于上式中的随机误差项,这是指测试过程中诸多因素随机作用而形成的具有抵偿性的误差,它的产生因素十分复杂,可能是温度的偶然变动,可能是气压的变化,也可能是零件的摩擦。例如咱们在测量身高的时候,就可能因为测量人员的轻微手震带来的随机误差

虽然这些方法很有趣,但在此之前,我们还是要对这些方法有一些系统的划分

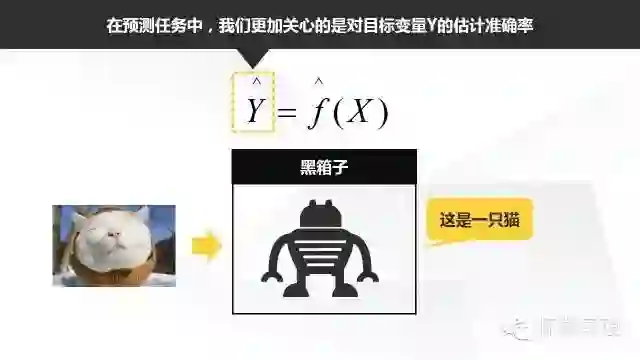
在这里,我们希望模型尽可能地精确,相反预测模型f的形式可能是一个黑箱模型(即模型的本身我们不能很好的解释或者并不清楚,我们更加关心这当中的输入和输出,并不试图考察其内部结构),只要能够提高我们的预测精度我们就认可达到目的了。一般认为,神经网络模型属于黑箱模型,如几年前Google X实验室开发出一套具有自主学习能力的神经网络模型,它能够从一千万中图片中找出那些有小猫的照片。在这里,输入就是这一千万张图片,输出就是对于这些图片的识别。

在这里,预测结果固然重要,但是我们也十分关心模型的形式具体是怎么样,或者借助统计挖掘模型帮助我们生成了怎样的判别规则。例如在银行业,我们希望通过客户的个人信用信息来评价个人的借贷风险,这就要求我们不但能够回答这个客户的风险是高是低,还要求我们回答哪些因素对客户风险高低有直接作用,每个因素的影响程度有多大。
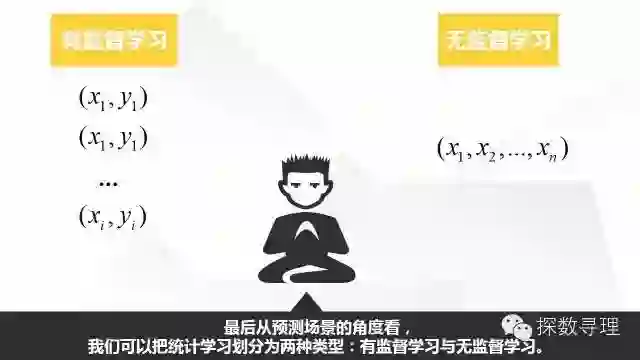
迄今为止上面的讨论内容都属于有监督学习范畴,即对每一个自变量x都有一个因变量y一一对应,我们希望通过拟合预测模型,更好理解预测变量与响应变量之间的关系,例如分析个人信用信息评价信用风险,企业营销费用投入与销量的关系等等。
进一步地,对于有监督学习,响应变量属于定量变量(即连续性变量,如GDP,企业年销售额)的话,我们把它定义为回归问题,而响应变量属于定性变量的话(即分类型变量,如违约客户与不违约客户,患病与不患病),我们定义为分类问题。
而对于无监督学习,则只有自变量x,而没有y。例如我们能够获得零售企业当中每个会员的行为信息,我们可能希望通过无监督学习的方法(聚类)把会员划分为不同的客户细分群体(粉丝客户群,注重性价比客户群)。


公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享
相关内容

社会学/环境学(社会统计学,心理学,人口学,空间统计学,环境统计学等)
工业工程学(质量控制,可靠性分析等)
经济学/金融学(精算学,金融统计学等)
工程学/计算机科学(统计学习,数据挖掘,信号/图像采样/处理等)
基础科学(统计物理学,统计化学等)
