近期必读的七篇 NeurIPS 2020【视觉目标检测】相关论文和代码
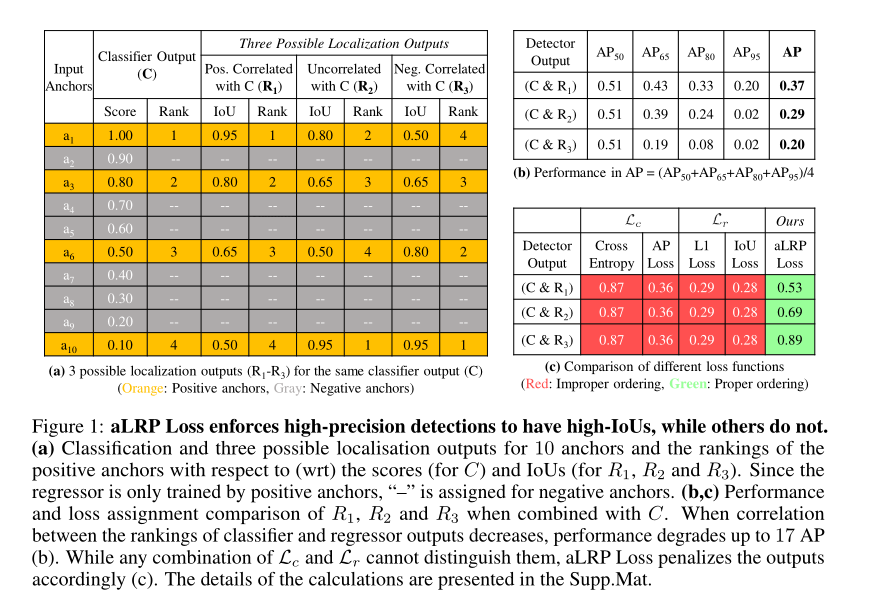
1. A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection
作者:Kemal Oksuz, Baris Can Cam, Emre Akbas, Sinan Kalkan
摘要:我们提出了一个平均定位召回精度(average Localisation-Recall-Precision, aLRP),这是一种统一,有界,平衡和基于排名的损失函数,用于目标检测中的分类和定位任务。aLRP扩展了平均召回率(LRP)性能指标,其idea来自于平均精确度(AP)损失如何将精确度扩展到基于排名的损失函数进行分类。aLRP具有以下明显的优势:(i)aLRP是分类和定位任务中第一个基于排名的损失函数。(ii)由于对两个任务都使用了排名,因此aLRP自然可以对高精度分类实施高质量的定位。(iii)aLRP在正负样本之间提供了可证明的平衡性。(iv)与最先进的检测器的损失函数中平均具有6个超参数相比,aLRP损失只有一个超参数,我们在实验中并未对其进行调整。在COCO数据集上,aLRP 损失改进了其基于排名的AP 损失,最多可增加5个AP点,在不增加测试时间的情况下AP可达到48.9,并且优于所有的先进的检测器。
代码:
https://github.com/kemaloksuz/aLRPLoss
网址:
https://www.zhuanzhi.ai/paper/759846ce7863317513628f858cc9e13f
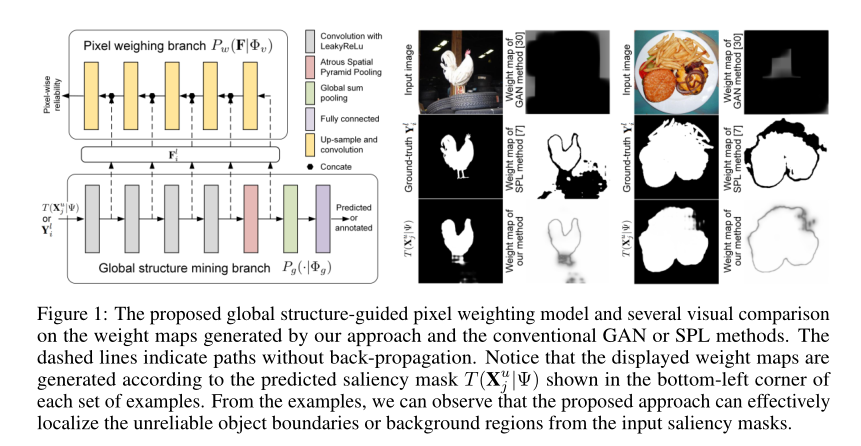
2. Few-Cost Salient Object Detection with Adversarial-Paced Learning
作者:Dingwen Zhang, HaiBin Tian, Jungong Han
摘要:近年来,从给定图像场景中检测和分割显著目标(salient objects)已引起了极大的关注。训练现有深度显著性检测模型的根本挑战是需要大量带标注的数据。尽管收集大量的训练数据变得既便宜又容易,但是从时间,劳动力和人的专业知识方面来说,对数据进行标注是一个昂贵的过程。为了解决这个问题,本文提出仅在少数训练图像上基于人工标注学习有效的显著性目标检测模型,从而大大减轻训练模型中的人工劳动。为此,我们将该任务命名为“成本最低的显著性目标检测”,并提出了一种基于对抗性学习(APL)的框架,以加强其学习场景。本质上,APL源自自主学习(self-paced learning, SPL)机制,与学习正则化的启发式设计不同,它通过数据驱动的对抗性学习机制来推断强大的学习速度。对四个广泛使用的基准数据集进行的综合实验表明,该方法可以仅用1k人工注释训练图像有效地处理了现有的有监督的深度显著性目标检测模型。
代码:
https://github.com/hb-stone/FC-SOD
网址:
https://proceedings.neurips.cc/paper/2020/hash/8fc687aa152e8199fe9e73304d407bca-Abstract.html
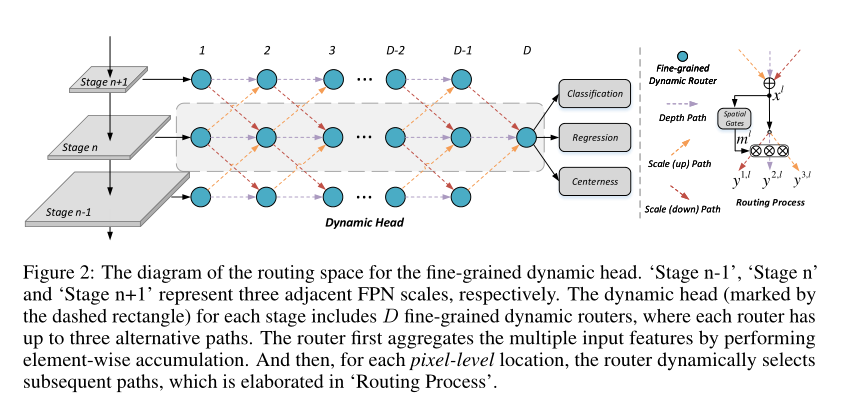
3. Fine-Grained Dynamic Head for Object Detection
作者:Lin Song, Yanwei Li, Zhengkai Jiang, Zeming Li, Hongbin Sun, Jian Sun, Nanning Zheng
摘要:特征金字塔网络(FPN)提出了一种优异的方法,可以通过执行实例级分配来减轻目标表观中的比例差异。然而,这种策略忽略了实例中不同子区域的独特特征。为此,我们提出了一种细粒度的动态头(dynamic head),可以针对每种情况从不同的比例有条件地选择FPN特征的像素级组合,从而进一步释放了多比例特征表示的能力。此外,我们设计了具有新激活函数的空间门,以通过空间稀疏卷积显着降低计算复杂性。大量实验证明了该方法在几种最新检测基准上的有效性和效率。
代码:
https://github.com/StevenGrove/DynamicHead
网址:
https://www.zhuanzhi.ai/paper/51339fa7e73aa6d9fb84b8294e313c62
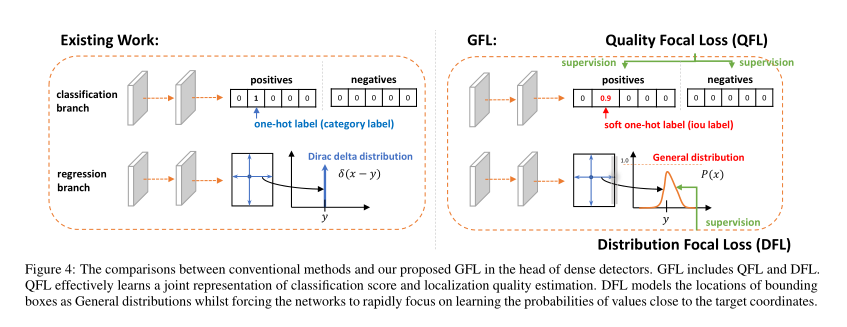
4. Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
作者:Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu, Jun Li, Jinhui Tang, Jian Yang
摘要:一步法(One-stage)检测器基本上将目标检测公式化为密集的分类和定位(即边界框回归)。通常通过Focal Loss 来优化分类,并且通常在狄拉克(Dirac delta)分布下了解其位置。一步法检测器的最新趋势是引入单个预测分支来估计定位质量,其中预测质量有助于分类以提高检测性能。本文研究了以上三个基本元素的表示形式:质量估计,分类和定位。在现有实践中发现了两个问题,包括(1)训练和推理之间质量估计和分类的用法不一致,以及(2)用于定位的不灵活的狄拉克分布。为了解决这些问题,我们为这些元素设计了新的表示形式。具体来说,我们将质量估计合并到类预测向量中以形成联合表示,并使用向量表示框位置的任意分布。改进的表示法消除了不一致的风险,并准确地描述了实际数据中的灵活分布,但这些表示中包含连续标签,这超出了Focal Loss的范围。然后,我们提出 Generalized Focal Loss(GFL),将Focal Loss从离散形式推广到连续版本,以实现成功的优化。在COCO测试开发中,GFL使用ResNet-101主干网络在AP上达到了45.0%,以更高或相当的推理速度超过了最先进的SAPD(43.5%)和A TSS(43.6%)。
网址:
https://www.zhuanzhi.ai/paper/cf418c8cc3f46083aa85c28f23d8e2bb
5. RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder
作者:Cheng Chi, Fangyun Wei, Han Hu
摘要:现有的目标检测框架通常建立在目标表示的单一格式上,即RetinaNet和Faster R-CNN中的锚点/建议矩形框,FCOS和RepPoints中的中心点以及CornerNet中的角点。尽管这些不同的表示形式通常会驱动框架在不同方面表现良好,例如更好的分类或更好的定位,但是由于异构或非均一性,通常很难将这些表示形式组合到单个框架中以充分利用每种优势。本文提出了一种基于注意力的解码器模块,与Transformer中的模块类似,以端到端的方式将其他表示形式桥接到基于单个表示形式格式的典型目标检测器中。其他表示充当一组key实例,以增强vanilla检测器中的主要query表示特征。提出了用于有效计算解码器模块的新技术,包括key采样方法和共享位置嵌入方法。我们将提出的模块称为桥接视觉表示(bridging visual representations, BVR)。并且我们证明了其在将其他表示形式桥接到流行的目标检测框架(包括RetinaNet,Faster R-CNN,FCOS和A TSS)中的广泛有效性,在这些方面在 AP实现了约1.5到3.0 的改进。特别是,我们将具有强大主干的最新框架在AP上改进了约2.0 ,在COCO测试开发中AP达到了52.7 A。我们将生成的网络名为RelationNet ++。
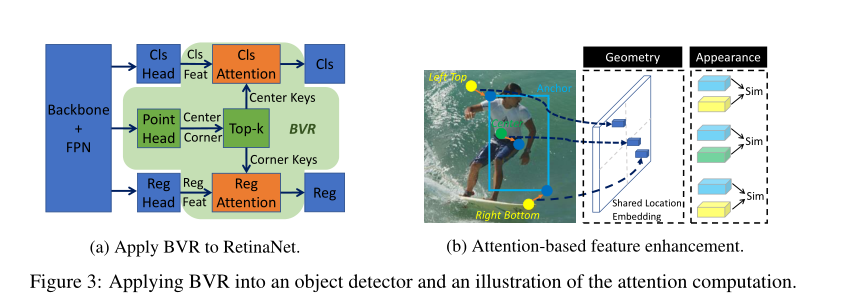
代码:
https://github.com/microsoft/RelationNet2
网址:
https://www.zhuanzhi.ai/paper/7958f98b996040c7c061edc67678b5ea
6. Restoring Negative Information in Few-Shot Object Detection
作者:Yukuan Yang, Fangyun Wei, Miaojing Shi, Guoqi Li
摘要:少样本学习成为深度学习领域的新挑战:与训练带有大量标记数据的深度神经网络(DNN)的常规方法不同,它要求在带有少量标注的新类别上推广DNN。少样本学习的最新进展主要集中在图像分类上,而在本文中,我们着重于目标检测。少样本目标检测的最初探索趋向于通过使用图像中相对于某些物体类别的正proposals而抛弃该类别的负 proposals来模拟分类场景。负样本,尤其是难样本,对于少样本目标检测中的嵌入空间学习至关重要。在本文中,我们通过引入一个新的基于负和正表观的度量学习框架以及具有负和正表观的新推理方案,来恢复少样本目标检测中的负信息。我们基于最近很少使用的pipeline RepMet构建我们的工作,该模型带有几个新模块,可以对负面信息进行编码,以进行训练和测试。在ImageNet-LOC和PASCAL VOC上进行的大量实验表明,我们的方法极大地改进了最新的少样本目标检测解决方案。
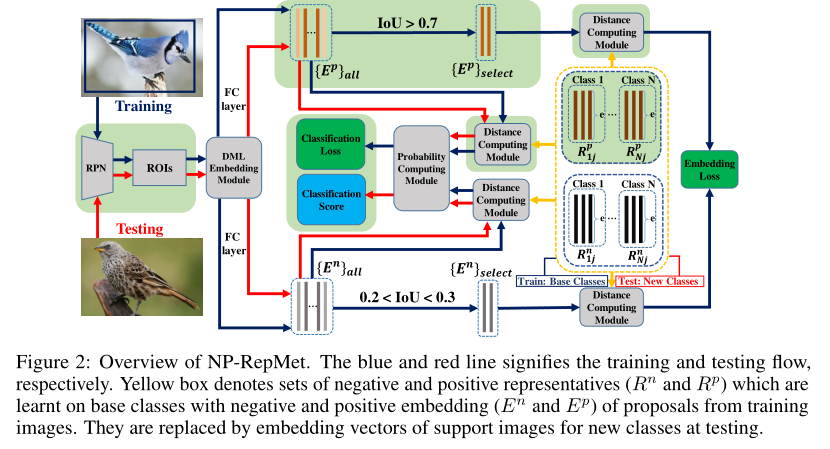
代码:
https://github.com/yang-yk/NP-RepMet
网址:
https://www.zhuanzhi.ai/paper/4ab252388a7a88732c6e4eb793758b82
7. UWSOD: Toward Fully-Supervised-Level Capacity Weakly Supervised Object Detection
作者:Yunhang Shen, Rongrong Ji, Zhiwei Chen, Yongjian Wu, Feiyue Huang
摘要:弱监督目标检测(WSOD)由于具有极大的灵活性,可以利用仅具有图像级标注的大规模数据集来进行检测器训练,因此受到了广泛的研究关注。尽管近年来有了很大的进步,但是WSOD的性能仍然受到限制,远远低于有监督的目标检测(FSOD)。由于大多数WSOD方法依赖于object proposal算法来生成候选区域,并且还面临着诸如质量低下的预测边界框和大规模变化之类的挑战。在本文中,我们提出了一个统一的WSOD框架(称为UWSOD),以构建仅包含图像级标签的大容量通用检测模型,该模型是独立的,不需要外部模块或其他监督。为此,我们利用了三个重要的组件,即object proposal生成,边界框微调和尺度不变特征。首先,我们提出一个基于锚点的自监督的proposa生成器来假设目标位置,该生成器由UWSOD创建的监督进行端到端的训练,以进行目标分类和回归。其次,我们通过逐步选择高可信度object proposal作为正样本,开发了逐步的边界框微调,以精炼检测分数和坐标,从而引导了预测边界框的质量。第三,我们构造了一个多速率重采样金字塔以聚合多尺度上下文信息,这是处理WSOD中尺度变化的第一个网络内特征层次结构。在PASCAL VOC和MS COCO上进行的大量实验表明,所提出的UWSOD使用最新的WSOD方法可获得竞争性结果,而无需外部模块或额外的监督。此外,具有类不可知的ground-truth边界框的UWSOD的上限性能接近Faster R-CNN,这表明UWSOD具有完全受监督级别的能力。
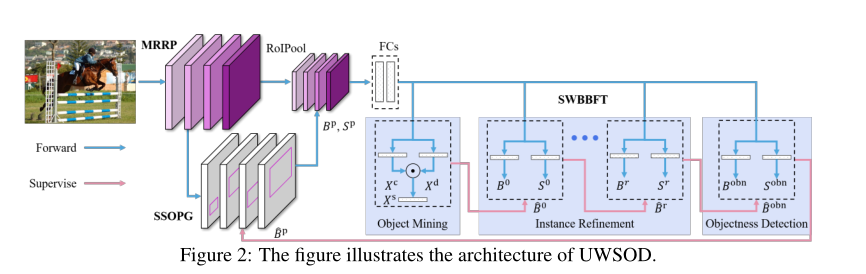
代码:
https://github.com/shenyunhang/UWSOD
网址:
https://proceedings.neurips.cc/paper/2020/hash/4e0928de075538c593fbdabb0c5ef2c3-Abstract.html
请关注专知公众号(点击上方蓝色专知关注)
后台回复“NIPS2020OD” 就可以获取《7篇顶会NeurIPS 2020 目标检测(Object Detection)相关论文》的pdf下载链接~






