学界 | UC伯克利联合谷歌推出无监督深度学习框架,模仿人眼实现视频中的自我运动认知
AI科技评论按:无监督学习可以说是深度学习的未来,本文第一作者Tinghui Zhou是加州大学伯克利分校电气工程与计算机科学学院的博士生,师从Alexei (Alyosha) Efros教授。本文是他与谷歌的 Matthew Brown、Noah Snavely与 David Lowe一同合作,此论文入选 CVPR 2017 oral paper。以下为AI科技评论据论文内容进行的部分编译。

论文摘要
为了非结构化视频顺序中的单镜深度和摄像机移动判断任务,我们提出了一个无监督学习框架。我们使用了一个端到端视图合成的学习方法来作为信号监督。和以前的工作相比,我们的方法是完全无监督,只需要单镜视频顺序的训练。我们的方法运用了单视图深度和多视图姿势网络和基于目标附近视图的翘曲损失来计算深度和姿势。通过来训练过程中的损失,网络被联结,但是在测试时可以独立应用。在KITTI数据组以实验为依据的评估也证明了我们方法的有效性。1)单镜深度表现和运用深度训练或groud-truth(真实值)的监督方法对比。2)在可比较输入设置下姿势判断表现和已建立的SLAM系统比较。
论文概述
人类有能力甚至于在一个很短的时刻就能判断自我运动和一个场景中的3D结构。例如,穿过街道,我们可以轻松识别障碍物并能作出快速反应去绕过它们。多年的计算机几何视觉研究并没达到重现真实世界场景的相似的建模能力。
人类为什么在这个任务上具有优势呢?一个假设是我们通过过去的视觉经验进化出了一个丰富的,有结构层次的理解力。大量场景的留心观察和四处走动和我们发现的在发展中的一致模型。通过数百万这样的发现,我们认识到了这个世界的规律性——路是平的,建筑是直立的。汽车需要路面的支撑等等。当我们进入一个新场景,甚至是一个单一的单眼图像,我们可以运用这些认知。
实验:单视图深度和多视图姿势判断。

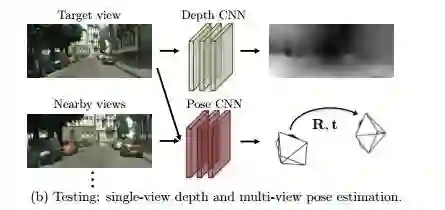
图1
图1,对于我们系统训练数据的无标签图像顺序捕捉是从不同的角度显现,图像的姿势不提供。我们的训练程序产生两个单独运行的模型,一个是单视图深度预测,另一个是多视图摄像机姿势判断。
在这个实验中,我们模仿这个方法,通过训练一个模型,遵循图像和目标的顺序去解释他的观察,我们采用端到端的方法让模型直接从输入的像素绘出一个自我运动的判断和基础的图像结构。我们尤其是受到前期工作的灵感启发,把视图合成作为一个单位度量。并且近期在端对端框架多视图3D案例中解决了标准化问题。我们的方法是无监督的并且只需要使用有先后顺序的图像就可以训练,不需要手工标记甚至摄像机运动信息。我们的方法是建立在对几何视图综合系统的深刻见解之上的。只有当几何场景的中间预测以及摄像机姿势和物理真实值相一致的时候,系统才能运行流畅。
对于特定类型的场景,当未完成的几何或姿势判断会欺骗合理的综合视图。(例如,质感缺失)同样的模型如果呈现给另一类拥有多样布局和外观结构的场景将会非常失败。所以,我们的目标是构想出全部的视图综合传递途径作为卷积神经网络的推断程序。所以,为了视图合成的元任务而基于大规模视频数据来训练网络是被强制来学习中间的深度任务,摄像机姿势判断是为了想出和视觉世界一致的解释。单视图深度和摄像机姿势判断研究方法的有效性已在KITTI上证明。
研究方法
为了能使单视图深度卷积神经网络和摄像机姿势判断从未标记视频序列一起训练,我们提出了一个框架。尽管是一起训练,深度模型和姿势判断模型可以在测试结论过程中单独运行。给我们模型的训练样本包括由移动摄像机捕捉到的图片序列。
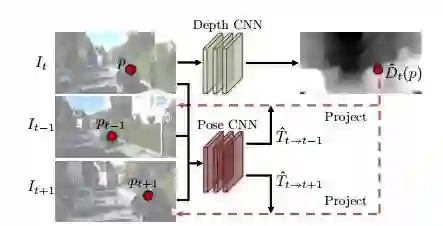
图2
图2,基于视图综合的监督途径的概述。深度网络只需将目标视图作为输入,然后在深度地图上输出相应的像素点Dˆ t (p)。姿势网络要提取目标视图(It )和目标附近的视图(e.g., It−1 and It+1 )作为输入,并且输出相关的摄像机姿势(Tˆt→t−1 , Tˆt→t+1 ).两种网络的输出使原始视图发生倒转。 重建目标视图,光度测定的重建损失用来训练卷积神经网络。通过利用视图合成作为监督,我们能够以一种无监督方式从视频中来训练剩余框架。
我们先假设我们感兴趣的是大多数不动的场景。跨越不同的框架,场景外观随着变化,最终由摄像机运动主宰场景变化。
对深度卷积神经网络和姿势预测的关键监督信号来自于异常视图合成:给一个视图场景的输入,从不同的摄像机姿势合成一个场景的新图像。我们可以合成一个目标视图,在新图像上给出像素深度,在视图附近附加上姿势和清晰度。正如我们下一步要展示的,这个合成过程伴随着卷积神经网络以一种完全可辨的方式运行。清晰度可以随着非刚性和其他非模型因素被控制。
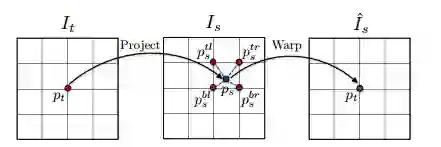
图3
图3,可辨的图形翘曲过程如图所示。对于目标视图的每一个点Pt,我们首先把它投射到基于预知深度和摄像机姿势的原始视图,然后利用双线性插值在目标位置Pt得出翘曲值。
实验结论
1)单视图深度判断
我们把连续的图片分为三部分画面,并把中间的画面作为目标视图,前后的画面作为原始视图。我们使用彩色相机一起捕捉这些图像,但是当形成训练序列时,要对他们单独处理。结果一共是44540张序列图片,我们使用其中的40109张来训练,4431张用来确认。单镜视频中用无监督学习方式来学习单视图深度判断,我们是第一个。这里我们提供和之前采用深度监督的学习方法以及最近采用标准立体图片来训练的方法对比。因为采用我们方法的深度预测由刻度因素来确定。

图4
图4提供了视觉对比的例子,我们的结果和基于大规模样本的监督学习之间的对比,其中可以看到的是通过无监督方式训练,我们得到的结果和监督学习得到的结果是相当的。其中在保存深度界限和弱结构上,比如树和街灯,表现的更好。
最后两排我们的模型表现出了典型的错误,在巨大的空旷场景和目标物离摄像机太近时,表现的很吃力。


图5
在图5,我们展示了通过我们最初的Cityscapes模型和最终模型的得到的样本预测。由于在这两个数据集中存在域名间隙,Cityscapes模型有时在还原汽车或灌木丛的完整形状有点困难,并且目标太远就会判断错误。
2)姿势判断
为了评估我们的姿势判断网络的表现,我们将我们的系统应用到官方KITTI测程法(包括11次驾驶序列通过IMU/GPS读取的真实测程值)使用00-08来训练,使用09-10序列来测试。在这次试验中,我们把输入到我们系统中图像固定为5部分。我们把自我运动判断和两种单镜ORB-SLAM(一个广为大家接受的SLAM系统)的变体相比较,1)ORB-SLAM(全)使用了驾驶序列的全部片段来还原里程。2)ORB-SLAM(短)只使用了5小段(和我们输入设置一样)。
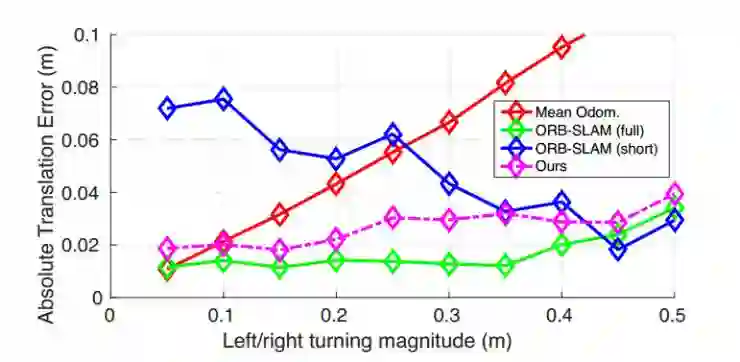
图6
图6 当侧旋角小的时候,我们的方法是明显优于ORB-SLAM(short)的,和ORB-SLAM(FULL)整个过程的效果是相当的。我们的方法和ORB-SLAM(short)大的表现差距说明我们的自我学习运动在单镜SLAM系统中的局部判断模块很用潜力被运用。
作者Tinghui Zhou也将实验代码在GitHub开源: https: //github.com/tinghuiz/SfMLearner
via berkeley,AI科技评论编译
报名 |【2017 AI 最佳雇主】榜单
在人工智能爆发初期的时代背景下,雷锋网联合旗下人工智能频道AI科技评论,携手 环球科学 和 BOSS 直聘,重磅推出【2017 AI 最佳雇主】榜单。
从“公司概况”、“创新能力”、“员工福利”三个维度切入,依据 20 多项评分标准,做到公平、公正、公开,全面评估和推动中国人工智能企业发展。
本次【2017 AI 最佳雇主】榜单活动主要经历三个重要时段:
2017.4.11-6.1 报名阶段
2017.6.1-7.1 评选阶段
2017.7.7 颁奖晚宴
最终榜单名单由雷锋网、AI科技评论、《环球科学》、BOSS 直聘以及 AI 学术大咖组成的评审团共同选出,并于7月份举行的 CCF-GAIR 2017大会期间公布。报名期间欢迎大家踊跃自荐或推荐心目中的最佳 AI 企业公司。
报名方式
如果您有意参加我们的评选活动,可以点击【阅读原文】,进入企业报名通道。提交相关审核材料之后,我们的工作人员会第一时间与您取得联系。
【2017 AI 最佳雇主】榜单与您一起,领跑人工智能时代。




