9大数据集、6大度量指标完胜对手,周志华等提出用深度森林处理多标签学习
选自arXiv
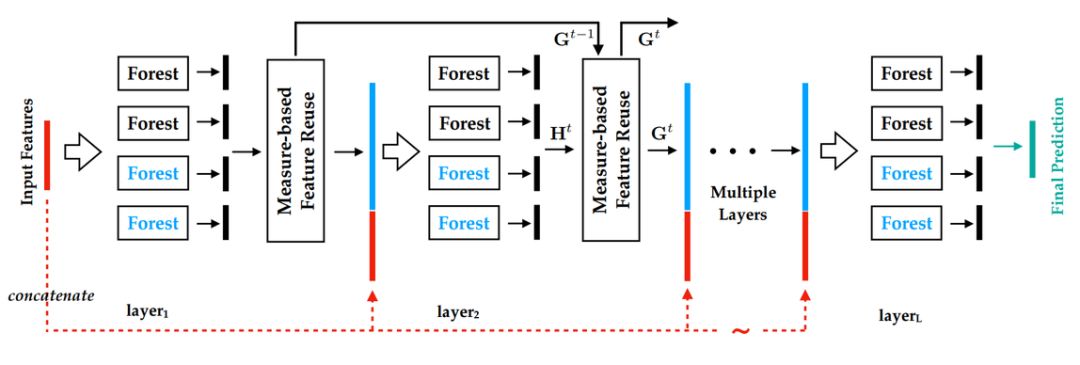
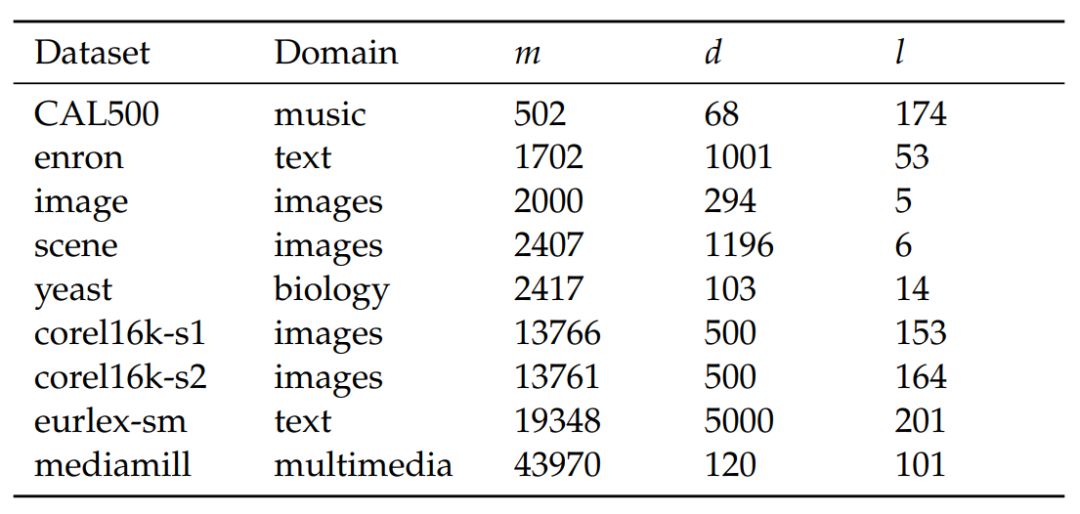
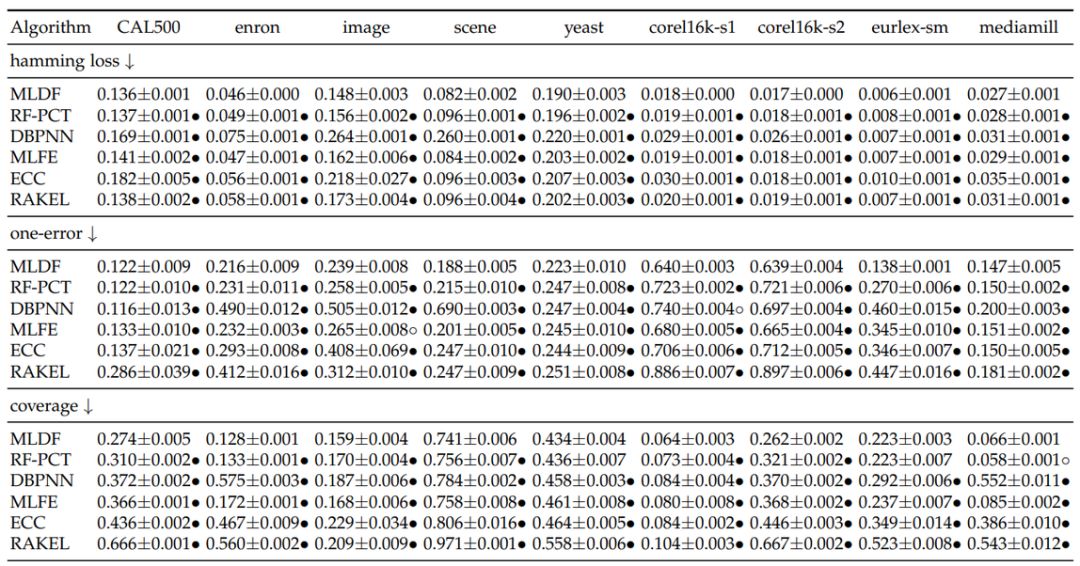
近日,南大周志华等人首次提出使用深度森林方法解决多标签学习任务。 该方法在 9 个基准数据集、6 个多标签度量指标上实现了最优性能。
首次提出将深度森林应用于多标签学习任务;
实验证明,MLDF 方法在 9 个基准数据集、6 个多标签度量指标上实现了最优性能。




点击阅读原文,立即访问。
登录查看更多
相关内容
专知会员服务
69+阅读 · 2020年6月19日
Arxiv
3+阅读 · 2020年4月13日
Arxiv
7+阅读 · 2018年11月15日
Arxiv
7+阅读 · 2018年4月17日



相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
相关资讯
相关论文
Arxiv
3+阅读 · 2020年4月13日
Arxiv
7+阅读 · 2018年11月15日
Arxiv
7+阅读 · 2018年4月17日