关于全卷积神经网络的思考
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:mileistone(媒智科技算法工程师)
https://zhuanlan.zhihu.com/p/89954785
本文已由作者授权,未经允许,不得二次转载
最近一个月先后想明白了目标检测和图像分类、语意分割和图像分类之间的联系。
通过论文《Single-Stage Multi-Person Pose Machines》和《PolarMask: Single Shot Instance Segmentation with Polar Representation》,进一步找到了图像分类、语意分割、图像分类、多人姿态估计和实例分割之间的共同点。
即这些任务对应的模型大部分是全卷积神经网络,例如单阶段目标检测、语意分割等等,即使不是全卷积神经网络的图像分类模型,只要将最后一层fc换成1x1的conv,也就转换为了全卷积神经网络。
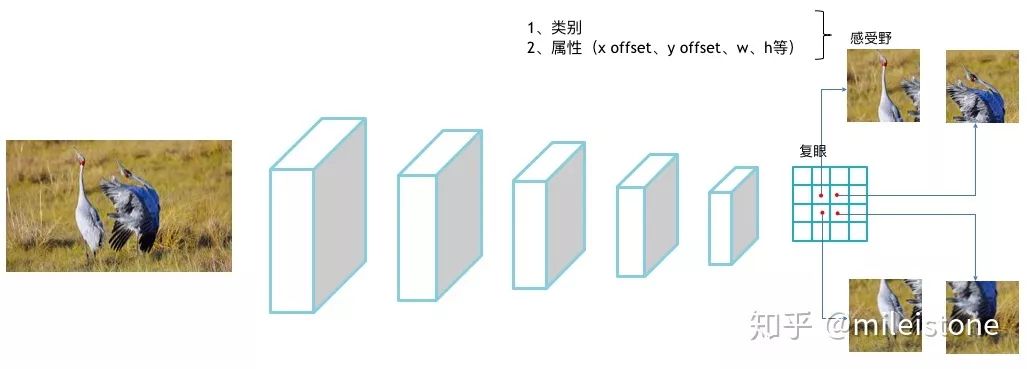
所有的任务都可以统一为一个全卷积神经网络,该全卷积神经网络输出的特征图如同昆虫的复眼,每个grid为一只眼睛,每只眼睛所看到的东西不一样,但是每只眼睛的视野范围相同(即,每只眼睛的感受野大小相同),每只眼睛单独工作,互不影响。具体可见图1,图像输入到全卷积网络中,输出的特征图大小为4*4,中间2*2个眼睛,每个眼睛看到的是图像不同的部位。

然后每只眼睛会判断:1、它看到了什么物体(类别);2、这个物体有什么特点(属性,可选项)。
以图像分类为例子,每只眼睛(因为使用了global average pooling,图像分类只有一只眼睛)会判断它看到了什么物体(类别)。
以语意分割为例子,每只眼睛会判断它看到了什么物体(类别)。
以目标检测为例子,每只眼睛会判断它看到了什么物体(类别),这个东西的x offset、y offset、w、h分别是多少(属性)。
以实例分割为例子,每个眼睛会判断它看到了什么物体,以该眼睛所在的地方为中心,该物体的36条极线分别有多长(属性)。
其他基于CNNs的计算机视觉任务可依次类推。
总结一句话就是:基于CNNs的任务的核心是全卷积神经网络,全卷积神经网络输出的特征图像昆虫的复眼,每个grid都是一只眼睛,每只眼睛的感受野相同,但是看到的内容不同,每只眼睛独立判断它看到了什么东西,这个东西有什么属性。
根据这一点,我们能更好的理解业界为了解决为了解决某种计算机视觉任务而设计的模型,当面对业界还没有研究过的计算机视觉任务时,我们也能自己设计出模型。
CVer 推荐阅读
YOLOv3最全复现代码合集(含PyTorch/TensorFlow和Keras等)
重磅!CVer-学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




