神经语言生成的非似然训练
文中提到文章论文均可通过搜索引擎搜索获得。

在自然语言生成领域,和很多其他领域一样,主模型结构只是一小部分,还会有其特有的重要技术,比如说音乐生成领域,很多看点都在后处理,并不是一个 RNN 直接训练生成就行,而语言生成领域,其中最重要的技术就是怎么改进训练目标,或者生成方法,来获得更好的生成结果。
现在主流的语言生成模型训练时,一般都用 Teacher Forcing,也就是训练时每一步喂进去的都是正确的(golden)词。关于 Teacher Forcing,更多可参考这篇 What is Teacher Forcing for Recurrent Neural Networks?
而生成时,我们用自回归的(Auto Regressive)方式来进行,也就是每一步喂进去的都是上一步的预测结果(第一步可以用一个特殊符比如<S>起步)。这就造成了训练与生成时的一个落差,导致了生成时出现的各种问题。至于为什么不用自回归方式来训练,主要因为用它训练会有更多缺点,比如,收敛慢,模型不稳定等等。
于是主流模型生成中有一个很致命的点,就是 Holtzman 等人在 The Curious Case of Neural Text Degeneration 提出的退化 (degenerate)问题。其实简单点说就是生成的重复问题,相信做过文本生成模型的童靴都了解,用 Greedy Search 或 Beam Search 有时模型说着说着就开始 “我知道。我知道。我知道...“ 这样不断重复起来。
详细不提,看论文,总之在上面这篇论文中,作者们发现,只要是现有这种训练与生成方式,就难以避免重复的问题出现,因为它是自我强化的(Self-Reinforcing),而在 Transformer 的生成模型中重复问题表现尤为明显。
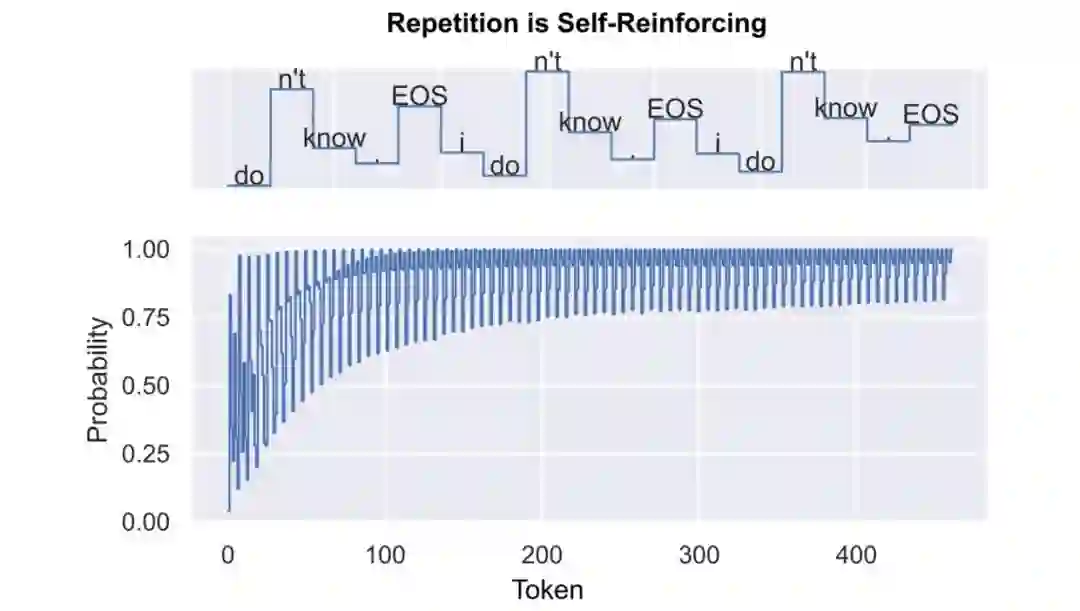
对于上面这个重复问题,Holtzman 他们提出了 Nucleus (Top-p) Sampling 从生成时的角度来解决,这个方法现在也被广泛用于 GPT-2 的生成中了。
而对于相同的问题,这篇论文 NEURAL TEXT DEGENERATION WITH UNLIKELIHOOD TRAINING 则从训练时的角度提出了方法来进行解决,该方法也就是标题中的非似然训练(Unlikelihood Training)。相信学习过机器学习的同学可能会觉得些疑惑了,一般不都是最大似然(Likelihood)吗,怎么还来了个 Unlikelihood。
其实它最主要 idea 就是通过在训练中强制让重复 unlikely,从而避免了之后生成时的重复问题了,可谓直截了当。
文中主要通过对两点进行非似然训练改进来避免重复,分别从 token(字词)级别和序列级别入手。
非似然训练方法
非似然损失(Unlikelihood Loss)
首先需要先说说什么是 unlikelihood loss,文中是这样定义:
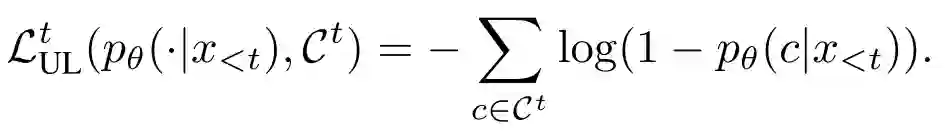
式中 可以看作不想预测名单(论文中叫 negative candidate tokens)吧。
对于这个的理解可以先给大家看看 cross-entropy 损失的二分类形式:
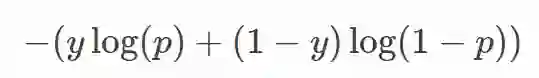
后半部分是不是和 unlikelihood loss 很眼熟,而前半部分,其实就可以当作是所谓的 likelihood loss 了,可以通过反传播让模型学习预测更接近目标 y。
同样,如果要理解 unlikelihood loss 作用,就是让模型学习预测远离 中的 token,在 的情况下。
字词级别非似然训练
思想很直接,就是将当前词之前(不包括当前词)的词全放入 中,然后将这些词的非似然损失加入损失函数,同时加入 来控制非似然损失的比例:
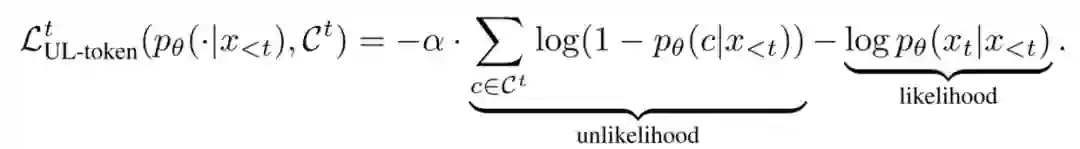
通过这样就可以达成两个效果:
让不正确的词重复变得更少;
让频繁出现的词变得更少。
这里论文还对该损失函数进行了梯度分析,非常精彩,鉴于篇幅可以阅读原文附录。
序列级别非似然训练
损失函数更简单,直接就是非似然损失
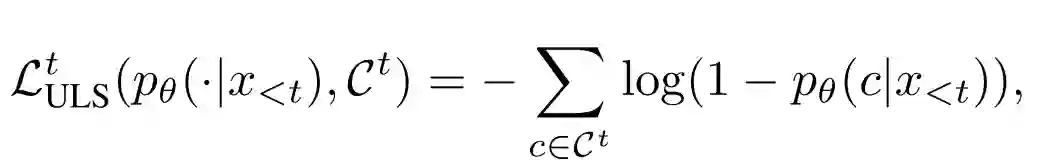
关键之处在于 的选定,主要是把 n-gram 中的词放入 从而避免了 n-gram 序列的重复:
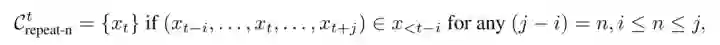
这里还需要指出一点,序列级别训练主要是用于精调,而不与字词级别训练一起,所以是先字词级别训练,然后再用序列级别训练精调。
实验结果
实验用的是 Transformer 模型,Wikitext-103 数据,然后训练语言模型,包括上面提到的非似然训练,最后进行句子补全来看测试效果。
首先在解决重复问题上面,可以说效果非常棒,无论是从词级别,还是短语级别,还是结构级别。
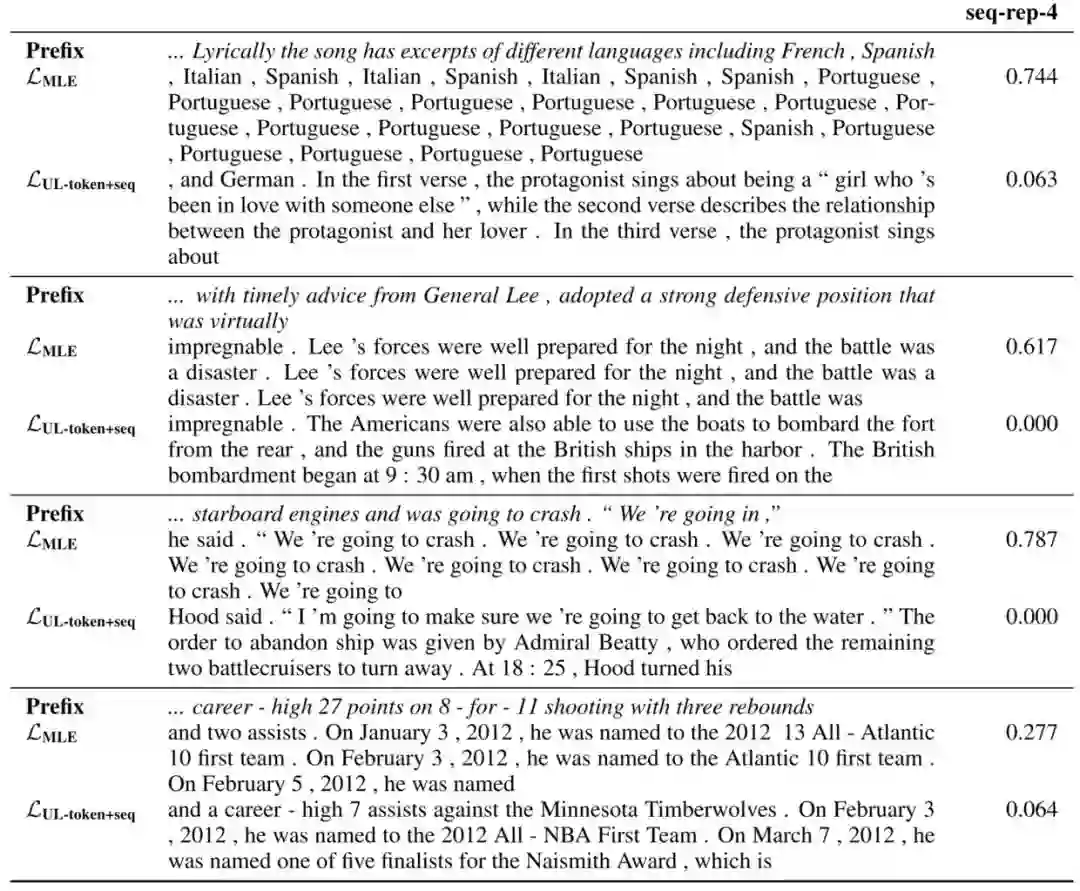
上面是直接用 Greedy Search 来进行的补全,MLE (Maximum Likelihood Estimation)是一般训练模型,UL-token+seq 就是先 token 级别的非似然训练,然后再序列级别精调的模型。最后一列是个 4-gram 重复的计算指标,可以看到非似然训练后的模型远远低于 MLE 的。
之后在困惑度(ppl)以及预测准确度(acc)的角度也进行了模型比较,发现新方法在这两个层面的表现也很不错。

其中 UL-token 为直接 token 级别非似然训练的模型,而 UL-seq 是在 MLE 上序列级别精调后的模型。
之后作者们还找来了人来对模型的生成结果进行了评论,发现也是都觉得新方法生成的更好,尤其是在序列级别的非似然训练加入后,可能这也说明了人类对于语言更注重序列层次吧。
趣闻
关于该论文有几个有趣的点可以提一下,首先是标题,最近看的几篇 facebook 论文已经脱离了我之前说的朴实无法风,开始走非主流搞怪风了。比如这篇:

删除符都加进来了,直接在标题里面就表示了该论文对消除 Degeneration (退化)问题的决心。
同时第一页注脚的位置,默默地写着:
平等贡献:作者序由抛硬币决定的。
本文转载自公众号:安迪的写作间,作者:Andy
推荐阅读
AI界最危险武器 GPT-2 使用指南:从Finetune到部署
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
Transformer (变形金刚,大雾) 三部曲:RNN 的继承者
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




