【泡泡一分钟】使用参考游戏机制推理细粒度属性词组(ICCV2017-42)
每天一分钟,带你读遍机器人顶级会议文章
标题:Reasoning about Fine-grained Attribute Phrases using Reference Games
作者:Jong-Chyi Su∗,ChenyunWu∗,Huaizu Jiang,Subhransu Maji
来源:ICCV 2017 ( IEEE International Conference on Computer Vision)
播音员:zzzzzq
编译:王健 周平(44)
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——使用参考游戏机制推理细粒度属性词组,该文章发表于iccv-2017。
本文提出了一个学习框架,用来描述属性短语实例之间的细粒度视觉差异。属性短语以组合的方式来捕获目标不同的方面(例如,“飞机上的螺旋桨”或飞机机翼附近的门)。一个类别内的实例可以用一组短语来描述,而且它们共同跨越这个类别的语义属性空间。通过让注者去描述类别内成对实例之间的些许视觉差异,作者收集这些(产生的)短语并制作大型的数据集。然后,依据说者和听者之间的参考游戏机制(参考游戏:就是听者根据说者说的作为参考来实施某种任务),作者试着将这些短语描述和映射到图像上(使它们互相关联)。 说者的目标是描述图像属性并且使听众在一对实例中正确识别该属性。以成对方式收集的数据提高了说者描述的能力,以及听众解释视觉描述的能力。此外,由于属性短语的组成性,训练的听者可以解释训练期间图像检索时没见过的描述,并且说者可以针对之前没见过的类别之间的差异生成基于属性的解释。本文还得出,将图像嵌入从听者派生的属性短语的语义空间中,其结果与FGVC飞机数据集上基于现有属性的表示方法相比,精度提高了20%。
本文效果图如下:

图1. 左图:本文数据集中的每个注释都由五对属性短语组成。右图:展现了说者和听者之间的参考游戏机制,说者描述一对图像中一个的属性,而听者的目标是从这对图像中选择正确的那个。
文中提出方法的实验结果显示:
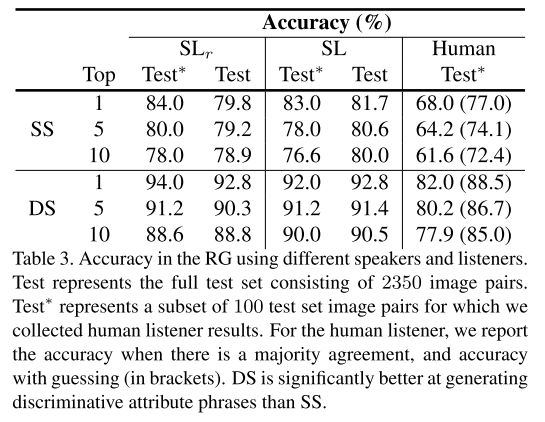
表3. 在参考游戏机制下,测量使用不同的说者和听者识别的准确性。 测试集是由2350个图像对组成的完整测试集。 Test*表示100个测试集图像对的子集,这些图像对是作者收集的人类听众结果,。 对于人类听众,我们报告了在有多数协议时的准确性,以及猜测的准确性(括号内)。表中显示DS比SS更能产生有区别的属性短语。

Abstract
We present a framework for learning to describe fine-grained visual differences between instances using attribute phrases.Attribute phrases capture distinguishing aspects of an object (e.g.,“propeller on the nose”or“door near the wing”for airplanes) in a compositional manner.Instances within a category can be described by a set of these phrases and collectively they span the space of semantic attributes for a category.We then learn to describe and ground these phrases to images in the context of a reference game between a speaker and a listener. The goal of a speaker is to describe attributes of an image that allows the listener to correctly identify it within a pair.Data collected in a pairwise manner improves the ability of the speaker to enerate, and the ability of the listener to interpret visual descriptions.Moreover, due to the compositionality of attribute phrases, the trained listeners can interpret descriptions not seen during training for image retrieval, and the speakers can generate attribute-based explanations for differences between previously unseen categories.We also show that embedding an image into the semantic space of attribute phrases derived from listeners offers 20% improvement in accuracy over existing attribute-based representations on the FGVC-aircraft dataset.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



