计算所网络数据实验室共获3篇SIGIR论文
中科院计算所网络数据科学与技术重点实验室在ACM SIGIR2018上共收获了3篇论文(其中两篇长文一篇短文)。ACMSIGIR是国际计算机学会举办的最重要学术会议。本届会议共收到稿件共736篇(其中长文投稿409篇),长文录用仅有86篇(录取率为21%),竞争非常激烈。计算所网络数据实验室此次录用的三篇工作分别为:
· “Modeling Diverse Relevance Patternsin Information Retrieval ”(作者:范意兴,郭嘉丰,兰艳艳,徐君,翟成祥,程学旗)
· “From Greedy Selection to ExploratoryDecision-Making: Diverse Ranking with Policy-Value Networks”(作者:冯悦、徐君、兰艳艳、郭嘉丰、曾玮、程学旗)
· “Variance Reduction of Policy GradientBandit Problem via Antithetic Variates”(作者:于思皓、徐君、兰艳艳、郭嘉丰、程学旗)
三篇论文的内容简要介绍如下:
1、 Modeling Diverse Relevance Patternsin Information Retrieval
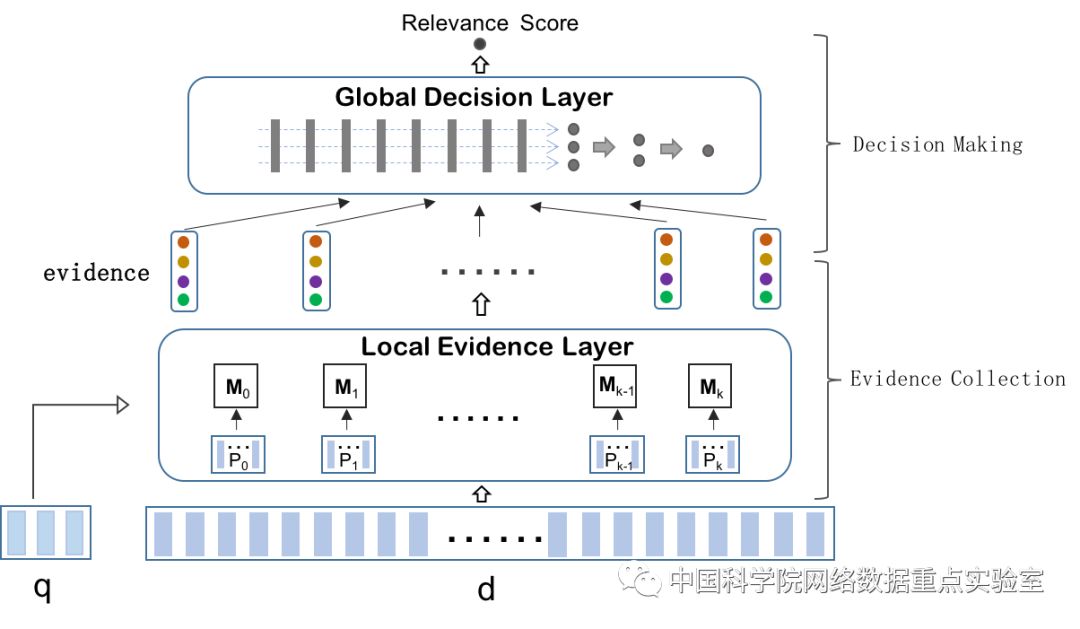
相关性排序作为信息检索中的核心任务之一,已经得到研究人员深入而又广泛的研究。然而在信息检索中的文档定义极其自由,它可以是一篇描述实体的维基百科页面,一段阐述观点的评论,甚至是一条发布状态的微博。无论文档的结构为何,只要文档中包含的信息能满足当前用户的信息需求,它就是一个相关的文档。这种宽泛的定义使得不同文档的相关模式差异显著。在本文中,提出了一个层次化的神经匹配模型,其中包含了局部信息匹配层以及全局的决策层。通过将局部的匹配信号组织成不同粒度的证据并让其相互竞争,以数据驱动的方式来选择当前文档最适合的相关模式进行的最终的文档相关性的判定。
2、From Greedy Selection to Exploratory Decision-Making:Diverse Ranking with Policy-Value Networks
多样性排序是信息检索中的重要任务之一,它的目标是通过查询项对大量文档进行排序,从而获取更多子话题的文档信息。现有的多样性排序方法主要包括启发式规则,显示子话题建模,隐式子话题建模等。这些方法采用的都是贪心选择策略,在每一步的文档选择过程中,会直接选取单步收益最大的文档进行排序。然而贪心选择策略很大程度上会导致局部最优问题。为了缓解贪心选择所造成的问题,我们提出了基于policy-value网络的探索式文档选择决策模型,模型结构如图一所示,通过Policy-value网络的指导完成MCTS,来探索后续位置的文档,从而缓解在文档多样性排序中,贪心选择造成的局部最优解问题。
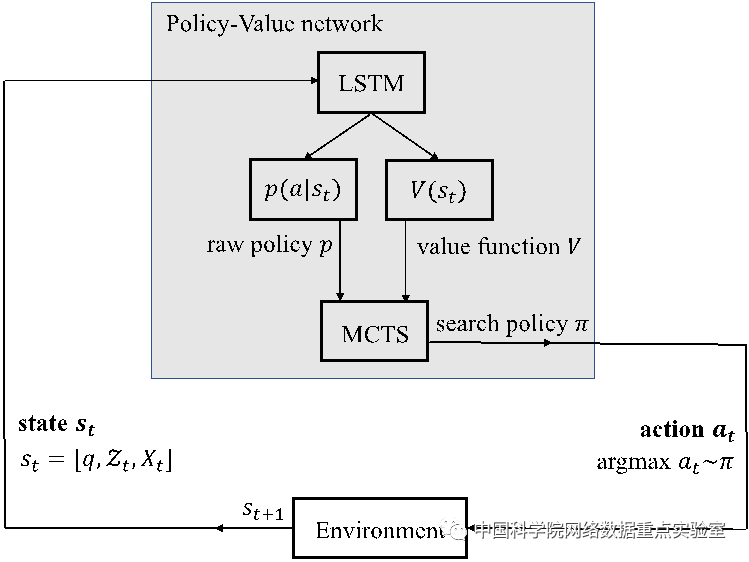
图二基于policy-value网络的探索式文档选择决策模型架构图
3、Variance Reduction of Policy Gradient Bandit Problem viaAntithetic Variates
策略梯度法作为强化学习中的一种重要方法,近几年在信息检索中扮演着越来越重要的角色。策略梯度法使用参数来建模每个动作的偏好从而得到整个任务的策略,再根据最终的收益来计算参数的梯度进行迭代更新。由于收益服从未知分布,策略梯度法使用蒙特卡罗方法来对参数梯度进行估计。虽然这样得到的梯度是无偏的,但往往伴随着较大的方差,严重影响了算法的效率和模型的效果,而本工作在强化学习的多臂机模型场景下,基于对偶变量法提出了一种新的降低梯度方差的方法“Antithetic Arm Bandit”(AAB)。AAB将梯度的估计转化为一个单调函数积分的估计从而引入对偶变量缩减方差。可以证明,ABB方法同样是无偏估计,且在相同采样次数下方差相较于原始的蒙特卡罗方法得到了较大的缩减。这篇工作为一些使用了策略梯度需要进行梯度方差缩减的工作与应用起到了一定的参考作用。
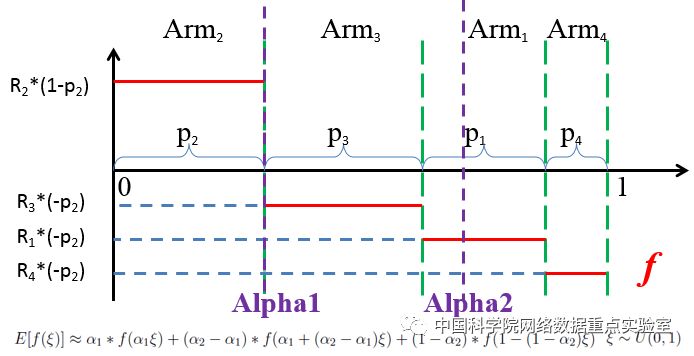
图三:AAB计算的梯度估计





