全面综述:图像特征提取与匹配技术
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
来源:自动驾驶全栈工程师知乎专栏
https://www.zhihu.com/people/william.hyin/columns
特征提取和匹配是许多计算机视觉应用中的一个重要任务,广泛运用在运动结构、图像检索、目标检测等领域。每个计算机视觉初学者最先了解的特征检测器几乎都是1988年发布的HARRIS。在之后的几十年时间内各种各样的特征检测器/描述符如雨后春笋般出现,特征检测的精度与速度都得到了提高。
特征提取和匹配由关键点检测,关键点特征描述和关键点匹配三个步骤组成。不同的检测器,描述符以及匹配器之间的组合往往是初学者疑惑的内容。本文将主要介绍关键点检测、描述以及匹配的背后原理,不同的组合方式之间的优劣,并提出几组根据实践结果得出的最佳组合。

Background Knowledge
特征(Feature)
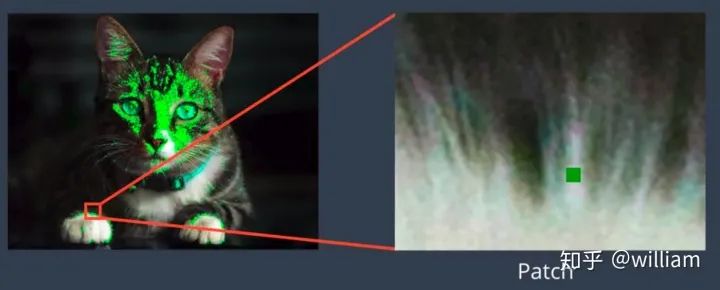

特征提取和匹配的主要组成部分
Detector
关键点/兴趣点(Key point/ Interest point)
关键点检测器光度和几何变化的不变性
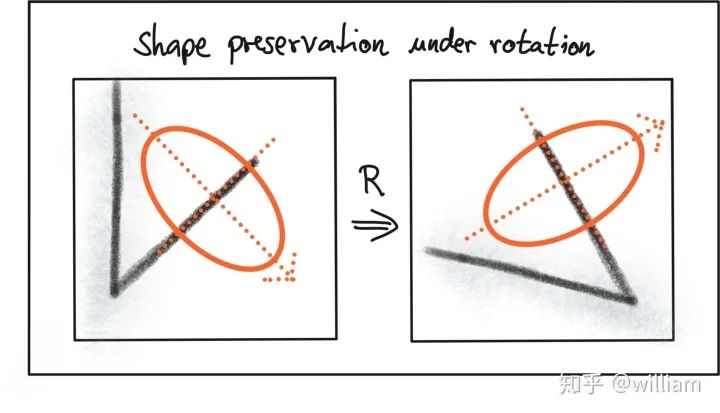
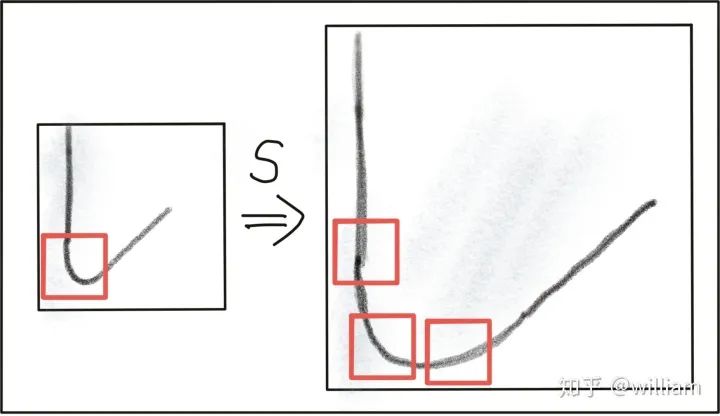
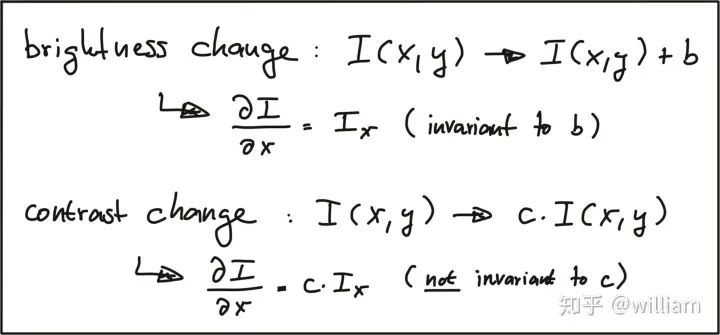
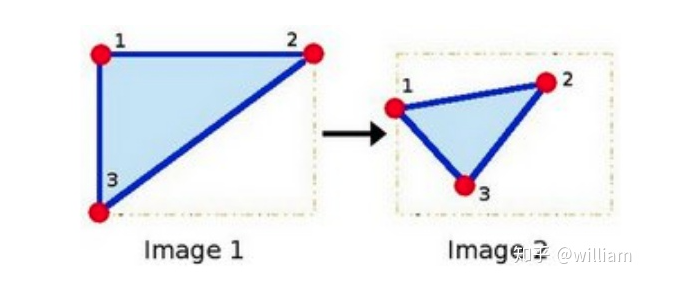

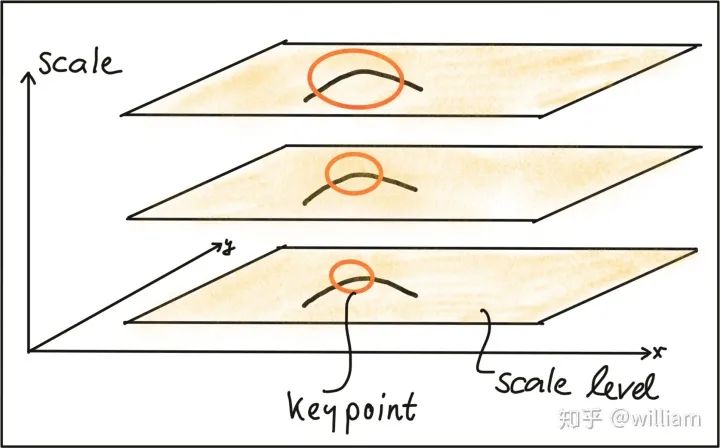
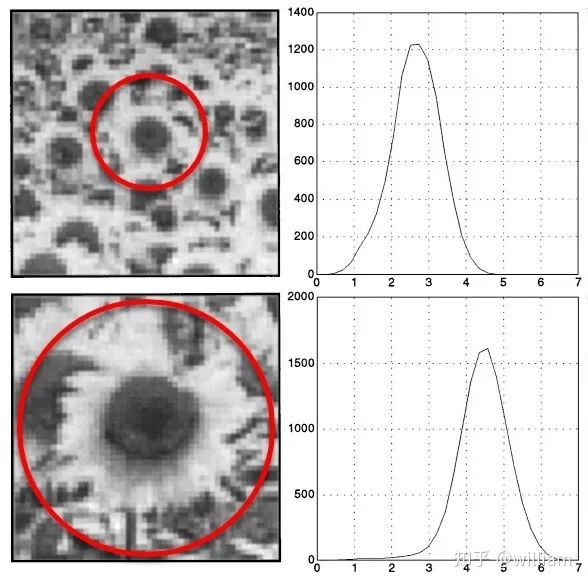
常见关键点检测器
经典关键点检测器
HARRIS- 1988 Harris Corner Detector (Harris, Stephens)
Shi, Tomasi- 1996 Good Features to Track (Shi, Tomasi)
SIFT- 1999 Scale Invariant Feature Transform (Lowe) -None free
SURT- 2006 Speeded Up Robust Features (Bay, Tuytelaars, Van Gool) -None free
现代关键点检测器
FAST- 2006 Features from Accelerated Segment Test (FAST) (Rosten, Drummond)
BRIEF- 2010 Binary Robust Independent Elementary Features (BRIEF) (Calonder, et al.)
ORB- 2011 Oriented FAST and Rotated BRIEF (ORB) (Rublee et al.)
BRISK- 2011 Binary Robust Invariant Scalable Keypoints (BRISK) (Leutenegger, Chli, Siegwart)
FREAK- 2012 Fast Retina Keypoint (FREAK) (Alahi, Ortiz, Vandergheynst)
KAZE- 2012 KAZE (Alcantarilla, Bartoli, Davidson)
Feature Descriptor
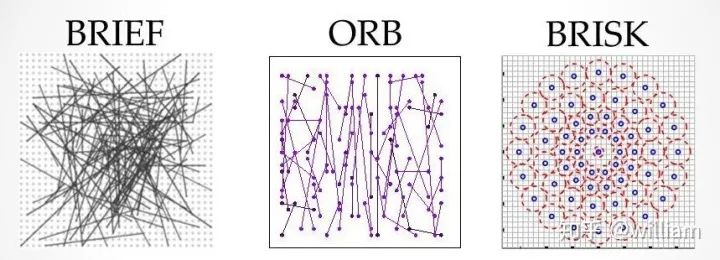
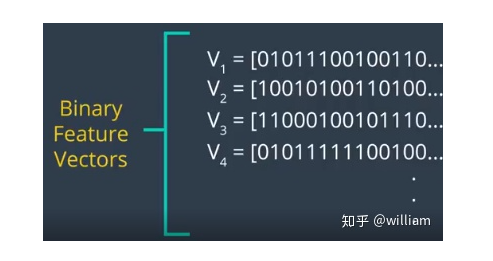
基于梯度与二进制的描述符
基于梯度HOG描述符

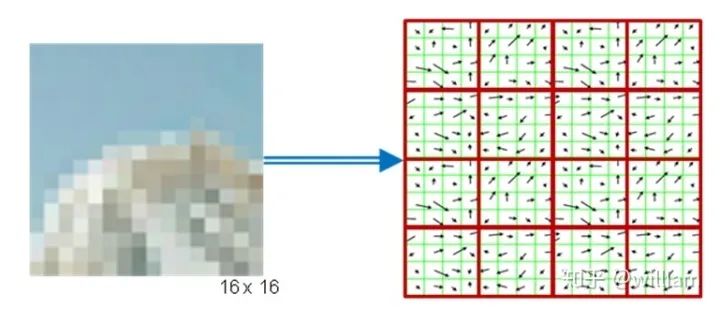
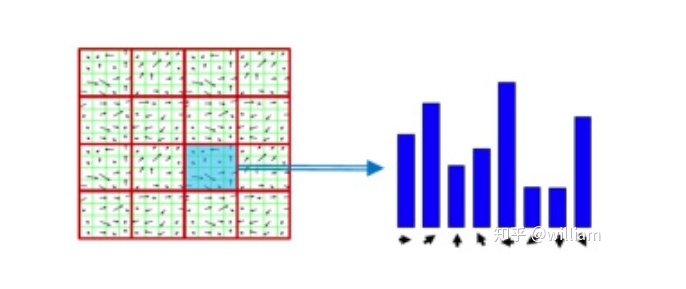
#include <opencv2/xfeatures2d/nonfree.hpp>,并且需要安装OPENCV_contribute包,注意一定要在Cmake选项中开启
OPENCV_ENABLE_NONFREE。



OPENCV Detector/Descriptor implementation
int nfeatures = 0;// The number of best features to retain.
int nOctaveLayers = 3;
// The number of layers in each octave. 3 is the value used in D. Lowe paper.
double contrastThreshold = 0.04;
// The contrast threshold used to filter out weak features in semi-uniform (low-contrast) regions.
double edgeThreshold = 10;// The threshold used to filter out edge-like features.
double sigma = 1.6;
// The sigma of the Gaussian applied to the input image at the octave \#0.
xxx=cv::xfeatures2d::SIFT::create(nfeatures, nOctaveLayers, contrastThreshold, edgeThreshold, sigma);
// Detector parameters
int blockSize = 2; // for every pixel, a blockSize × blockSize neighborhood is considered
int apertureSize = 3; // aperture parameter for Sobel operator (must be odd)
int minResponse = 100; // minimum value for a corner in the 8bit scaled response matrix
double k = 0.04; // Harris parameter (see equation for details)
// Detect Harris corners and normalize output
cv::Mat dst, dst_norm, dst_norm_scaled;
dst = cv::Mat::zeros(img.size(), CV_32FC1);
cv::cornerHarris(img, dst, blockSize, apertureSize, k, cv::BORDER_DEFAULT);
cv::normalize(dst, dst_norm, 0, 255, cv::NORM_MINMAX, CV_32FC1, cv::Mat());
cv::convertScaleAbs(dst_norm, dst_norm_scaled);
// Look for prominent corners and instantiate keypoints
double maxOverlap = 0.0; // max. permissible overlap between two features in %, used during non-maxima suppression
for (size_t j = 0; j < dst_norm.rows; j++) {
for (size_t i = 0; i < dst_norm.cols; i++) {
int response = (int) dst_norm.at<float>(j, i);
if (response > minResponse) { // only store points above a threshold
cv::KeyPoint newKeyPoint;
newKeyPoint.pt = cv::Point2f(i, j);
newKeyPoint.size = 2 * apertureSize;
newKeyPoint.response = response;
// perform non-maximum suppression (NMS) in local neighbourhood around new key point
bool bOverlap = false;
for (auto it = keypoints.begin(); it != keypoints.end(); ++it) {
double kptOverlap = cv::KeyPoint::overlap(newKeyPoint, *it);
if (kptOverlap > maxOverlap) {
bOverlap = true;
if (newKeyPoint.response >
(*it).response) {
// if overlap is >t AND response is higher for new kpt
*it = newKeyPoint; // replace old key point with new one
break; // quit loop over keypoints
}
}
}
if (!bOverlap) {
// only add new key point if no overlap has been found in previous NMS
keypoints.push_back(newKeyPoint); // store new keypoint in dynamic list
}
}
} // eof loop over cols
} // eof loop over rows
int blockSize = 6;
// size of an average block for computing a derivative covariation matrix over each pixel neighborhood
double maxOverlap = 0.0; // max. permissible overlap between two features in %
double minDistance = (1.0 - maxOverlap) * blockSize;
int maxCorners = img.rows * img.cols / max(1.0, minDistance); // max. num. of keypoints
double qualityLevel = 0.01; // minimal accepted quality of image corners
double k = 0.04;
bool useHarris = false;
// Apply corner detection
vector<cv::Point2f> corners;
cv::goodFeaturesToTrack(img, corners, maxCorners, qualityLevel, minDistance, cv::Mat(), blockSize, useHarris, k);
// add corners to result vector
for (auto it = corners.begin(); it != corners.end(); ++it) {
cv::KeyPoint newKeyPoint;
newKeyPoint.pt = cv::Point2f((*it).x, (*it).y);
newKeyPoint.size = blockSize;
keypoints.push_back(newKeyPoint);
}
int threshold = 30; // FAST/AGAST detection threshold score.
int octaves = 3; // detection octaves (use 0 to do single scale)
float patternScale = 1.0f; // apply this scale to the pattern used for sampling the neighbourhood of a keypoint.
xxx=cv::BRISK::create(threshold, octaves, patternScale);
bool orientationNormalized = true;// Enable orientation normalization.
bool scaleNormalized = true;// Enable scale normalization.
float patternScale = 22.0f;// Scaling of the description pattern.
int nOctaves = 4;// Number of octaves covered by the detected keypoints.
const std::vector<int> &selectedPairs = std::vector<int>();
// (Optional) user defined selected pairs indexes,
xxx=cv::xfeatures2d::FREAK::create(orientationNormalized, scaleNormalized, patternScale, nOctaves,selectedPairs);
int threshold = 30;// Difference between intensity of the central pixel and pixels of a circle around this pixel
bool nonmaxSuppression = true;// perform non-maxima suppression on keypoints
cv::FastFeatureDetector::DetectorType type = cv::FastFeatureDetector::TYPE_9_16;
// TYPE_9_16, TYPE_7_12, TYPE_5_8
xxx=cv::FastFeatureDetector::create(threshold, nonmaxSuppression, type);
int nfeatures = 500;// The maximum number of features to retain.
float scaleFactor = 1.2f;// Pyramid decimation ratio, greater than 1.
int nlevels = 8;// The number of pyramid levels.
int edgeThreshold = 31;// This is size of the border where the features are not detected.
int firstLevel = 0;// The level of pyramid to put source image to.
int WTA_K = 2;
// The number of points that produce each element of the oriented BRIEF descriptor.
auto scoreType = cv::ORB::HARRIS_SCORE;
// The default HARRIS_SCORE means that Harris algorithm is used to rank features.
int patchSize = 31;// Size of the patch used by the oriented BRIEF descriptor.
int fastThreshold = 20;// The fast threshold.
xxx=cv::ORB::create(nfeatures, scaleFactor, nlevels, edgeThreshold, firstLevel, WTA_K, scoreType,patchSize, fastThreshold);
auto descriptor_type = cv::AKAZE::DESCRIPTOR_MLDB;
// Type of the extracted descriptor: DESCRIPTOR_KAZE, DESCRIPTOR_KAZE_UPRIGHT, DESCRIPTOR_MLDB or DESCRIPTOR_MLDB_UPRIGHT.
int descriptor_size = 0;// Size of the descriptor in bits. 0 -> Full size
int descriptor_channels = 3;// Number of channels in the descriptor (1, 2, 3)
float threshold = 0.001f;// Detector response threshold to accept point
int nOctaves = 4;// Maximum octave evolution of the image
int nOctaveLayers = 4;// Default number of sublevels per scale level
auto diffusivity = cv::KAZE::DIFF_PM_G2;
// Diffusivity type. DIFF_PM_G1, DIFF_PM_G2, DIFF_WEICKERT or DIFF_CHARBONNIER
xxx=cv::AKAZE::create(descriptor_type, descriptor_size, descriptor_channels, threshold, nOctaves,nOctaveLayers, diffusivity);
int bytes = 32;
// Legth of the descriptor in bytes, valid values are: 16, 32 (default) or 64 .
bool use_orientation = false;
// Sample patterns using keypoints orientation, disabled by default.
xxx=cv::xfeatures2d::BriefDescriptorExtractor::create(bytes, use_orientation);
Descriptor Matching

描述符之间的距离
-
绝对差之和(SAD)- L1-norm -
平方差之和(SSD)- L2-norm -
汉明距离 (Hamming distance)

-
BINARY descriptors :BRISK, BRIEF, ORB, FREAK, and AKAZE- Hamming distance -
HOG descriptors : SIFT (and SURF and GLOH, all patented)- L2-norm
寻找匹配对
蛮力匹配(Brute Force Matching)
快速最近邻(FLANN)
选择匹配对
BFMatching- crossCheck
Nearest neighbor distance ratio (NN)/K-nearest-neighbor(KNN)
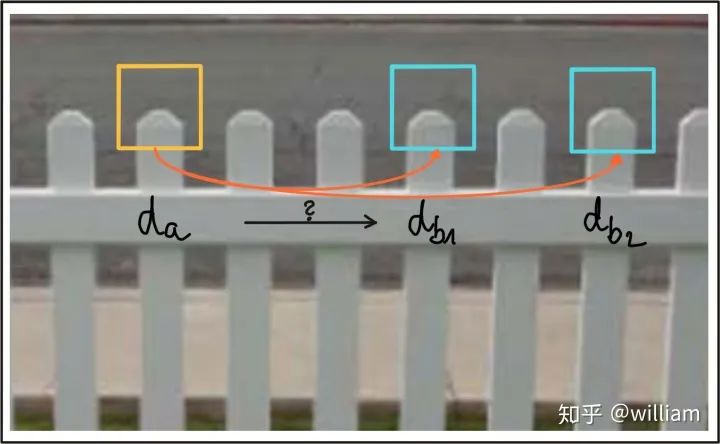
void matchDescriptors(std::vector<cv::KeyPoint> &kPtsSource, std::vector<cv::KeyPoint> &kPtsRef, cv::Mat &descSource,cv::Mat &descRef,std::vector<cv::DMatch> &matches, std::string descriptorclass, std::string matcherType,std::string selectorType) {
// configure matcher
bool crossCheck = false;
cv::Ptr<cv::DescriptorMatcher> matcher;
int normType;
if (matcherType.compare("MAT_BF") == 0) {
int normType = descriptorclass.compare("DES_BINARY") == 0 ? cv::NORM_HAMMING : cv::NORM_L2;
matcher = cv::BFMatcher::create(normType, crossCheck);
} else if (matcherType.compare("MAT_FLANN") == 0) {
// OpenCV bug workaround : convert binary descriptors to floating point due to a bug in current OpenCV implementation
if (descSource.type() !=CV_32F) {
descSource.convertTo(descSource, CV_32F);
// descRef.convertTo(descRef, CV_32F);
}
if (descRef.type() !=CV_32F) {
descRef.convertTo(descRef, CV_32F);
}
matcher = cv::DescriptorMatcher::create(cv::DescriptorMatcher::FLANNBASED);
}
// perform matching task
if (selectorType.compare("SEL_NN") == 0) { // nearest neighbor (best match)
matcher->match(descSource, descRef, matches);
// Finds the best match for each descriptor in desc1
} else if (selectorType.compare("SEL_KNN") == 0) { // k nearest neighbors (k=2)
vector<vector<cv::DMatch>> knn_matches;
matcher->knnMatch(descSource, descRef, knn_matches, 2);
//-- Filter matches using the Lowe's ratio test
double minDescDistRatio = 0.8;
for (auto it = knn_matches.begin(); it != knn_matches.end(); ++it) {
if ((*it)[0].distance < minDescDistRatio * (*it)[1].distance) {
matches.push_back((*it)[0]);
}
}
}
}
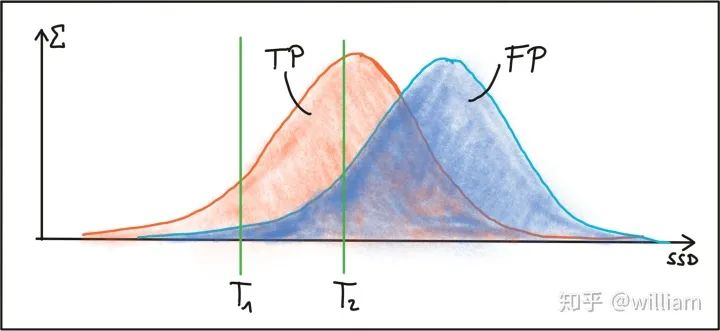
Evaluating Matching Performance
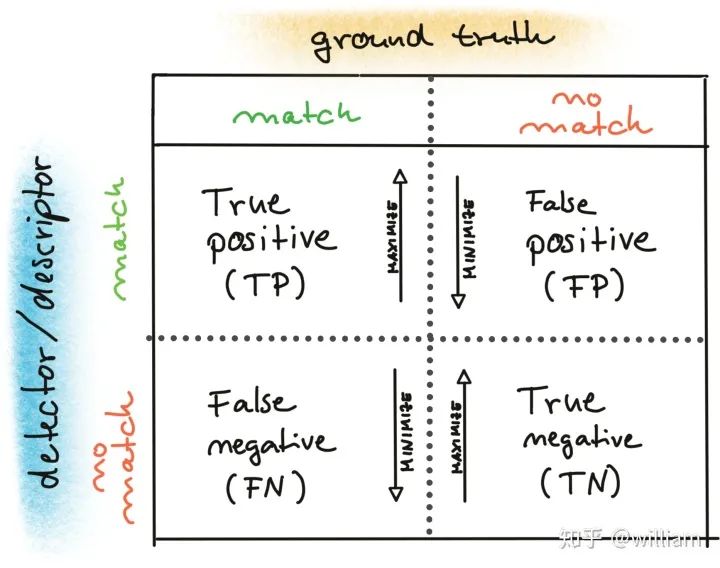
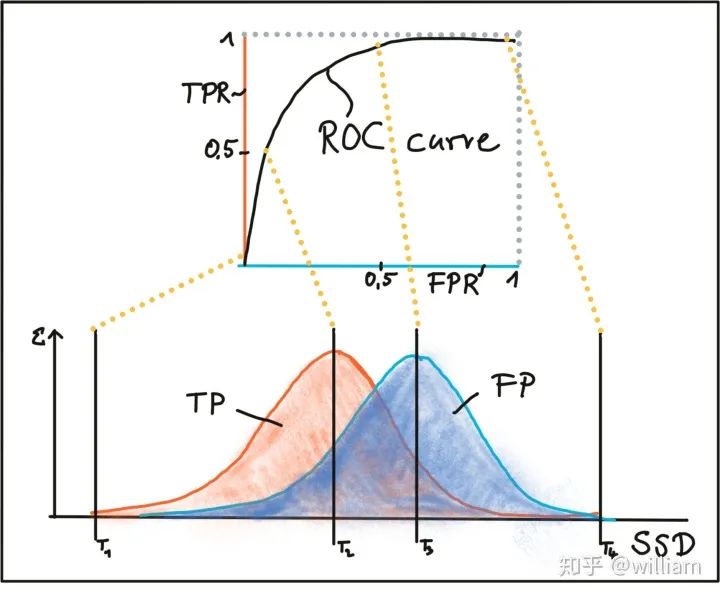
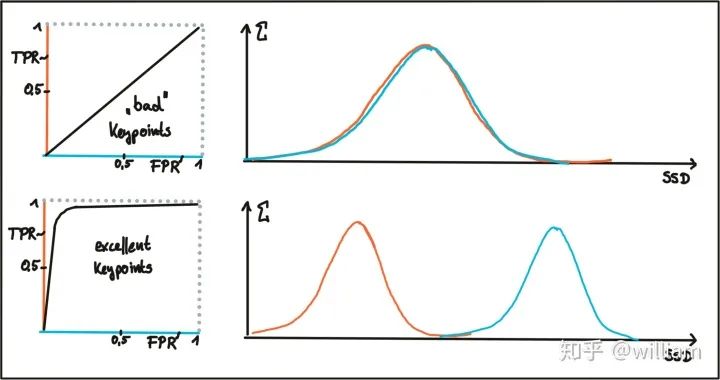
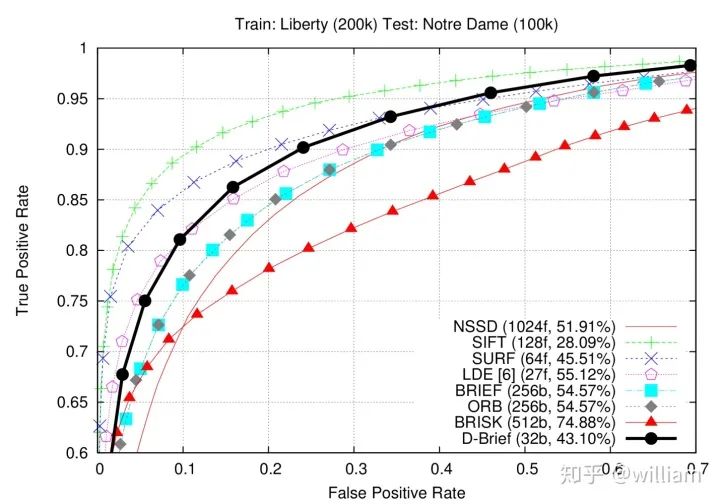
Conclusion
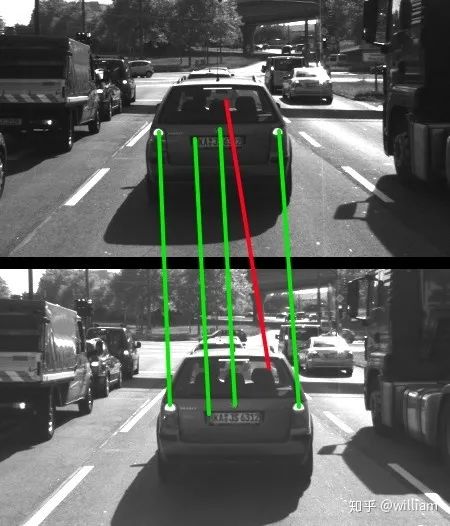
2D_Feature_Tracking项目的目的在于使用检测器和描述符的所有可能组合,为所有10张图像计算只在前方车辆范围内的关键点数量,检测时间,描述时间,匹配时间以及匹配的关键点数量。在匹配步骤中,使用BF方法及KNN选择器并将描述符距离比设置为0.8。
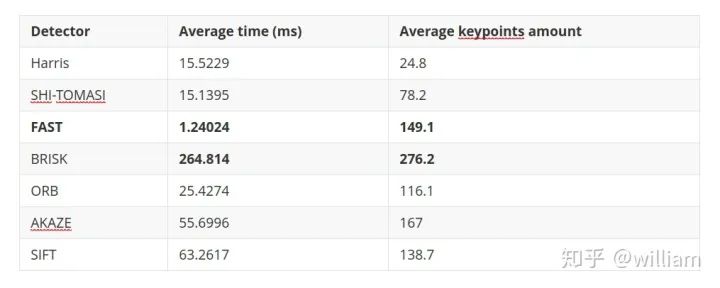
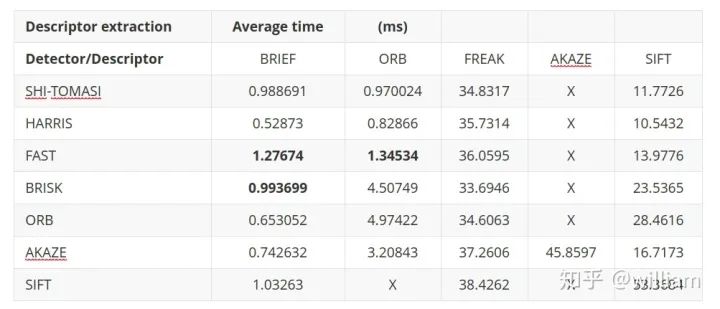
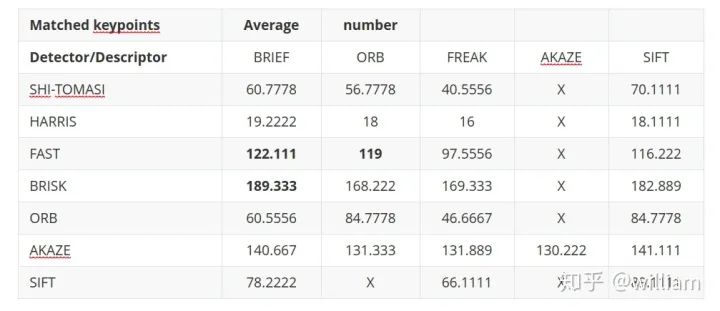
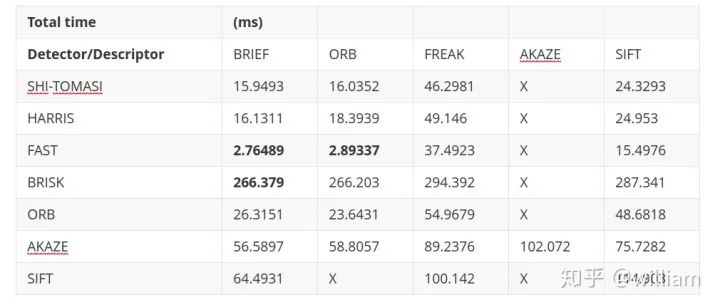
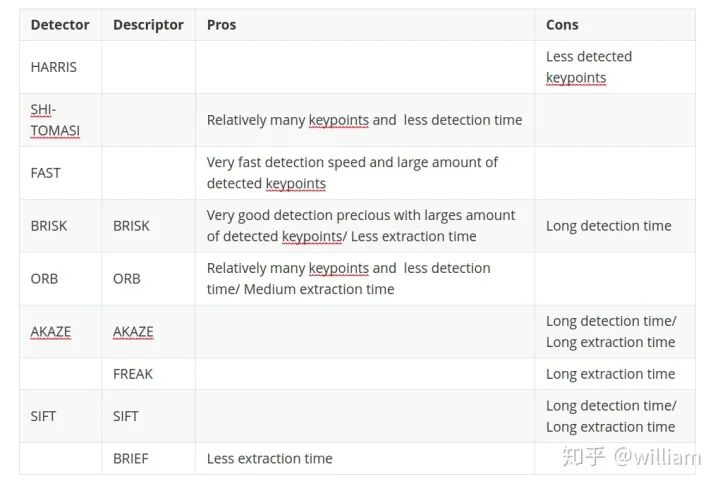
-
FAST + BRIEF (Higher speed and relative good accuracy) -
BRISK + BRIEF (Higher accuracy) -
FAST + ORB (relatively good speed and accuracy)






从0到1学习SLAM,戳↓

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life



