AI+安防前沿算法解读:在无监督数据的情况下,生成自然人体图像

编者按:本文作者 Liqian Ma,他为雷锋网AI 科技评论频道撰写了他作为第一作者被 CVPR 2018 录用的 Spotlight 论文解读稿件。
下面要介绍的论文发表于 CVPR 2018,题为「Disentangled Person Image Generation」。
我们的目标是在无监督数据的情况下生成自然人体图像。为此,我们提出了一种基于自监督的解耦表达人体前景、背景、姿态特征的生成式模型。其中,重建过程是基于对人体图像的三个弱相关成分, 即前景人体(foreground),背景(background)和人体姿态点(pose)的分解,压缩和解码重建原图像提取对应的三类特征。之后分别以这三类特征作为目标,训练对抗性生成网络实现从高斯噪声生成新的对应特征,同时利用前一步训练得到的图像解码器对新特征解码得到新的人体图像。该模型可以用于多种应用:人体图片修改与采样,样本插值,行人重识别,姿态指导的人体图像生成。
一、为什么要做解耦表达的人体生成模型?有什么优点?
在之前的图像转换工作中(图 1),CVPR17 的 pix2pix [1] 通过使用带监督信息的训练数据来学习一个可以进行外观转换的 image-to-image 模型。之后,ICCV17 的 cycleGAN [2] 提出使用 cycle-consistency 的约束使得无监督学习 image-to-image 模型成为可能。以上两个主流的模型主要针对图像的外观信息进行迁移,而没有进行结构信息的迁移。我们 NIPS17 的工作 PG2 [3] 则可以通过将人体姿态关节点和图像一起作为网络输入,然后利用有监督学习对人体图像进行结构信息的迁移。为了同时进行外观和结构信息的迁移,我们将人体图片分解为前景、背景、姿态三个弱相关因素,从而可以单独控制各个因素。此外,我们还提出一种「高斯噪声-> 特征 ->图像」的映射方式,使得模型可以分别从高斯空间采样得到对应的前景、背景、姿态。该论文采用自监督的方式来训练模型,因此不需要带监督信息的训练数据。总结来讲,模型有如下优点:
1)单独控制前景、背景、姿态;
2)可以从高斯空间采样;
3)不需要带监督信息的训练数据。
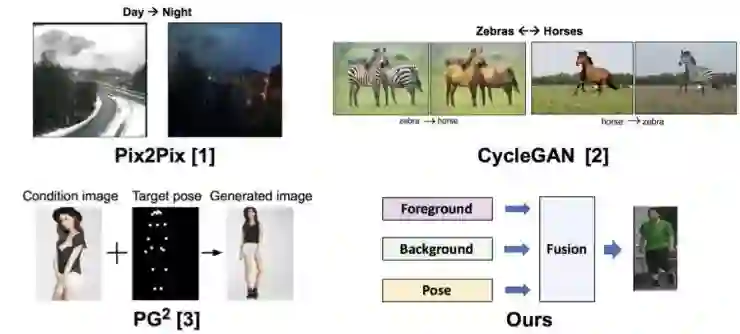
图 1. 图像转换相关工作对比。
二、如何解耦表达人体前景、背景、姿态特征?如何采样新的人体图像?
该论文提出了一种分阶段学习方法。在第一阶段,通过包含编码器、解码器的重构网络来学习三种弱相关人体图像特征,即前景、背景和姿态。在第二阶段,则将之前训练好的编码器、解码器固定,通过对抗式学习来分别训练三个映射函数,来将高斯空间分别映射到三个特征空间。在测试阶段采样时,我们可以先通过第二阶段学习到的映射函数来将高斯噪声映射到特征空间,然后利用第一阶段学习到的解码器将特征解码成图像。相比于直接将高斯空间映射到图像空间,这种两阶段映射降低了映射难度:相比于图像空间,特征空间的分布更加接近于图像数据,因此可以更容易通过对抗学习得到映射函数。此外,第二阶段的映射函数可以在第一阶段训练完成后进行,并不需要对第一阶段的特征空间加任何假设,因此可以应用于任何高斯空间到图像特征空间的映射。
我们已经验证:当使用类似 VAE[4] 和 AAE[5] 的方式直接在第一阶段的 bottleneck 层(即特征空间)加约束,会导致训练不稳定或者学到的特征空间存在模型坍塌的问题。因此,我们提出将第一阶段特征空间的高斯约束转换成学习一个从高斯噪声到特征空间的映射函数。
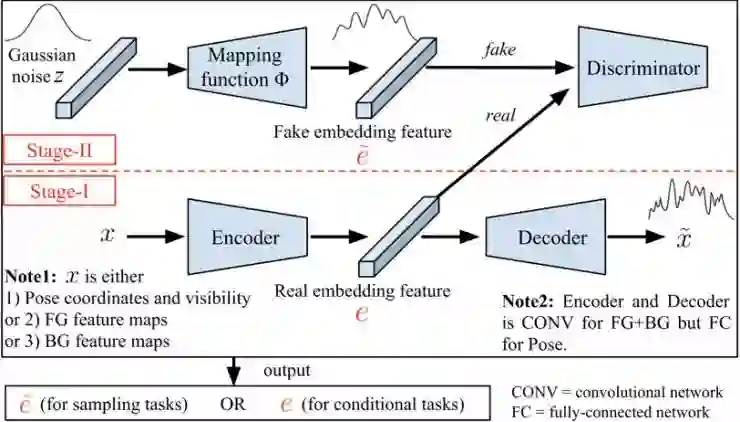
图 2. 整体框图,包含阶段一和阶段二。
阶段一是一个重构网络的结构,包含编码器和解码器两部分。
1)在编码器部分,我们将图像分为前景,背景,姿态三种因素,并用三个分支网络进行分别编码。这一过程由自动检测得到的人体姿态关节点来引导:通过对人体姿态关节点进行连接及一些图像形态学操作(如腐蚀和膨胀)来得到一个粗糙的 mask(红色虚线框),来显式地分割前景与背景信息。需要注意的是我们在 feature map 层而不是 image 层进行前景、背景分割,主要因为我们的 mask 并不精确,直接在 image 层分割累计的误差会影响生成效果。而在 feature map 层分割,则可以通过重建网络的引导使得输出 feature map 的卷积层自行学习纠正这些误差,改善生成效果。进一步,在前景分支上,我们利用人体 7 个 Body ROI [6] 来进行局部编码后再将 7 个部分的特征向量合并成一个。此过程中的 7 个局部编码器之间共享权重。
2)在解码器部分,我们将前景特征和背景特征进行拼接并在空间域上平铺成和图像分辨率一致的外观特征立方体,最后将外观特征立方体与人体姿态关节点拼接再输入具有 U-net 结构的解码器(蓝色虚线框)。这种外观和结构信息的融合方式可以帮助解码器学习如何根据人体关节点信息引导来选择「填充」合理的外观信息 [3]。
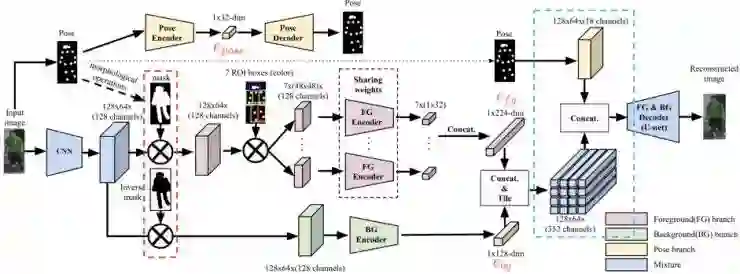
图 3. 阶段一详细结构。
三、解耦表达的人体生成模型可以应用在哪些任务?
1)人体图片修改与采样
如图 4 所示,该模型在 128x64 分辨率的行人重识别数据库 Market-1501 和 256x256 分辨率的时尚数据库 DeepFashion 上进行了测试。我们可以看到在 Market-1501 上,该模型可以通过固定两个因素(如,背景和姿态)对应的高斯噪声输入来单独修改剩余的一种(如,前景),或者同时采样三种因素的噪声生成三种因素截然不同的图像。在 DeepFashion 上,该模型则可用于从高斯空间采样出新的衣服样式(前景)。

图 4. 人体图片修改与采样结果。
2)样本插值
如图 5 所示,我们可以使用简单的梯度下降方法找到真实图片 x1,x2 在高斯空间中对应的编码,然后进行线性插值,并将插值得到的编码解码成图像。我们可以看到,插值得到的中间结果可以在一定程度上反应两帧之间的变化。




图 5. 人体图片样本插值(x1 和 x2 是真实图片)
3)行人重识别
如图 6 所示,为了验证我们的生成数据对行人重识别的帮助,我们在 Market-1501 数据库上通过固定前景,采样背景和姿态,来得到一个人工生成的 ID(前景)对应的不同图片。我们构建了一个包含 500 个 ID,每个 ID 有 24 张图片的 Virtual Market 数据库。使用该虚拟数据库来训练行人重识别的模型,之后在实际测试数据上我们的虚拟数据库训练的模型可以达到 state-of-the-art 的非监督 re-id 模型的识别率(见表 1 第四排第五排),甚至超过有些在标记数据库上进行预训练的模型(见表 1 第一排第二排)。

图 6. 生成的 Virtual Market 数据库。每一列对应一个 ID 的一对不同图片。

表 1. 行人重识别结果对比。Rank-1 和 mAP 都是越高越好。
4)姿态指导的人体图像生成
如图 7 所示,我们的模型同样可以根据输入的目标姿态来改变输入人体图片的姿态。相比于使用带监督信息数据进行学习的 PG2 [3] 模型,我们提出的自监督学习模型同样达到可媲美的效果,而我们的优势在于我们的模型不需要任何带监督信息的训练数据。从表 2 的量化结果来看,PG2 因为采用 U-net 结构,编码器和解码器之间有 skip-connection,可以更好地保留原图像的细节,生成的图像和真值图片的相似度(SSIM score)更高。而我们提出的模型用编码器将图像空间映射到特征空间,并没有使用 skip-connection 将原图的细节传给解码器,故出现了一些外观不一致的细节,但生成的图像更加逼真,有更高的 inception score。因此,如果要用我们的模型来做「姿态指导的人体图像生成」,还需要使用类似 skip-connection 的方式来将原图的细节更好地传达给生成结果。
如图 8 所示,给定目标姿态的序列,我们也可以将一幅图像转换成一个视频序列(未使用时域信息)。这里我们展示的是交叉姿态驱动的结果,即使用 B 的姿态序列来驱动 A 的外观,反之亦然。

图 7. 姿态指导的人体图像生成可视化结果对比。

表 2. 姿态指导的人体图像生成量化结果对比。(Mask-)SSIM 和 IS 都是越高越好。
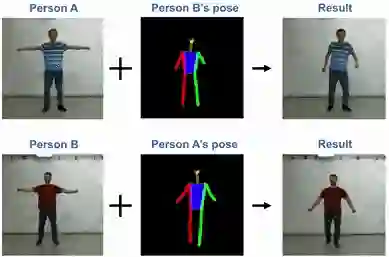
图 8. 基于骨架驱动的人体视频生成。
另外,在我们的最新工作「Exemplar Guided Unsupervised Image-to-Image Translation」中,我们提出了针对两个内容相关 domain 图像的基于样例的无监督转换方法,可以根据样例来将原始图像转换到目标 domain 的特定风格,并同时保持图像语义结构的一致性(天还是天,路还是路),实现了多对多的映射。欢迎大家围观 https://arxiv.org/abs/1805.11145
参考文献:
[1] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In CVPR, 2017.
[2] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV, 2017.
[3] L. Ma, J. Xu, Q. Sun, B. Schiele, T. Tuytelaars, and L. Van Gool. Pose guided person image generation. In NIPS, 2017.
[4] D. P. Kingma and M. Welling. Auto-encoding variational bayes. In ICLR, 2014.
[5] A. Makhzani, J. Shlens, N. Jaitly, I. Goodfellow, and B. Frey. Adversarial autoencoders. In arXiv, 2015.
[6] H. Zhao, M. Tian, S. Sun, J. Shao, J. Yan, S. Yi, X. Wang, and X. Tang. Spindle net: Person re-identification with human body region guided feature decomposition and fusion. In CVPR, 2017.
[7] H. Fan, L. Zheng, and Y. Yang. Unsupervised person re-identification: Clustering and fine-tuning. In arXiv, 2017.
论文地址:https://homes.esat.kuleuven.be/~liqianma/pdf/CVPR18_Ma_Disentangled_Person_Image_Generation.pdf
项目地址:https://homes.esat.kuleuven.be/~liqianma/CVPR18_DPIG/
知乎:https://zhuanlan.zhihu.com/p/35626735

长按二维码,关注雷锋网旗下「AI掘金志」



