基于深度学习的电商交易欺诈检测系统

交易欺诈对电子商务带来了巨大的威胁,来自清华大学交叉信息研究院博士后、物理学博士王书浩近日在 AI 研习社的青年分享会上介绍了基于循环神经网络的交易欺诈检测系统——时间侦探(CLUE),他重点讲解了电商欺诈检测这一场景下的三个主要技术难点:非平衡样本学习、实时检测系统、增量模型更新。
▷ 观看完整回顾大概需要 44 分钟
以下为他的分享内容,AI研习社编辑整理如下:
很高兴在这里与大家分享我们跟京东金融合作的一篇论文,这篇论文已经被 ECML-PKDD2017 接收。我们的工作一句话就可以概括,即通过深度学习的方法来进行电商欺诈的检测。我想讲的更多的是从工业落地的角度,去建立一套完整的系统来解决问题。
研究背景
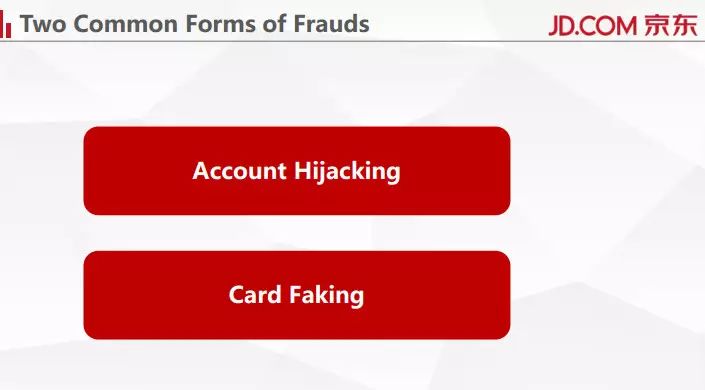
首先介绍一下背景。在电商网站里面,我们经常会遇到两种欺诈。
第一种欺诈是指用户的账户被窃取了,窃取者可能还会得到用户的支付密码,之后他很有可能登录这个用户的账户进行一些欺诈活动,比如说会购买一些商品进行变现,间接的把用户账户里的余额取走。
第二种是现在黑市上可以买到一些假的卡片,比如说假的信用卡,如果这个人能够注册一个新的账户,然后把卡绑定到他的账户名下,他就可以使用这个卡来买商品,然后把商品进行变现。
这两种欺诈有一个共同点,即欺诈用户都会进行商品的购买和变现。这些欺诈用户的行为是不是有一些共同的特点,是否可以通过一种手段去观察整个浏览路径?我们通过交易之前发生的一系列的动作,可以判断出这个用户到底是正常用户还是被怀疑为欺诈的用户。
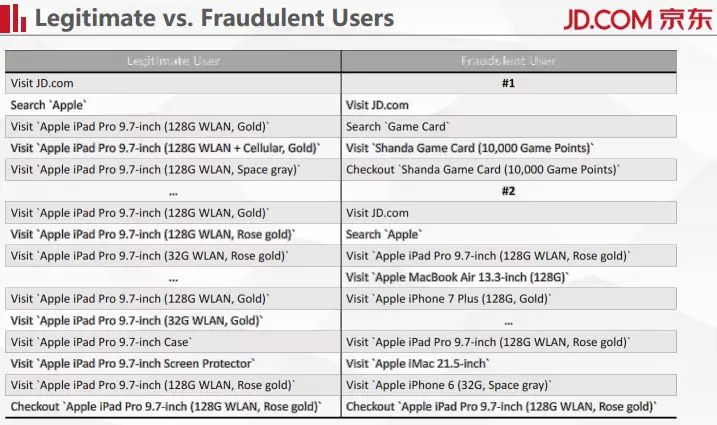
上面这个表左边展示的是正常用户的浏览路径,可以看到这个用户最后买了一个 128G 的 wifi 版玫瑰金 iPad Pro,整个浏览路径非常有规律。对于欺诈用户而言,看右边这两个用户,从统计上来说有两个比较鲜明的特点。
第一个是用户非常简单粗暴,购买的都是一些虚拟物品,因为虚拟物品可以随时变现。
第二个是用户的浏览行为没有逻辑性,他首先访问京东,然后搜索苹果,浏览了一堆苹果的商品,但可以看到浏览的这些商品没有太大的关联性,我们系统中会记录这是一次欺诈行为。
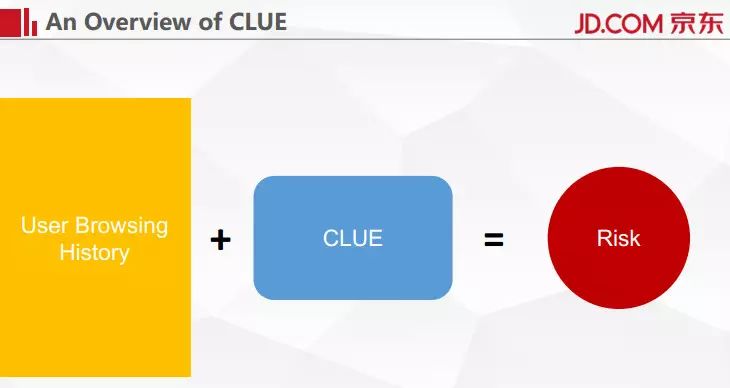
整个系统的中文名叫做时间侦探,时间是指观察用户在整个浏览序列里面的时序数据,然后用深入学习的办法来对它进行建模。我们所能拿到的数据就是京东上产生的用户的浏览历史,再加上我们的系统去观察,之后系统会给出对整个浏览行为的风险判定,我们得到的其实是风险评分。处于用户隐私角度的考虑,我们的浏览历史里面没有关于这个用户 ID 的任何信息。
技术挑战
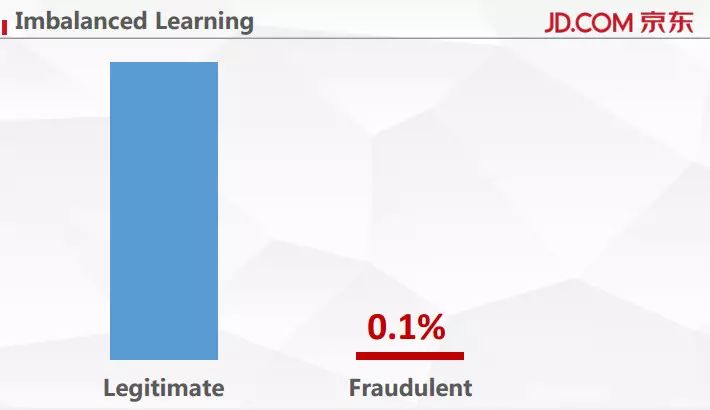
一个非常直接的挑战首先是我们拿到的样本是一个非常不平衡的样本,这就是所谓的非平衡样本的学习问题。从上面这幅图中可以明显看到欺诈用户和正常用户的占比大概是千分之一, 非常小。在研究过程里面,我们固定了千分之一的欺诈占比,又称异常占比。异常占比小的问题会对系统的学习造成很大的干扰。

第二个非常严峻的问题就是访问量太大了。京东现在有超过 2.2 亿的活跃用户,单就 PC 端来说,每天 session 的数目大概都是在千万的量级,真正发生交易的 session 数目大概也有百万量级。这个系统其实只看发生交易的 session,一天大概要处理掉百万的访问,这对系统压力是非常大的。
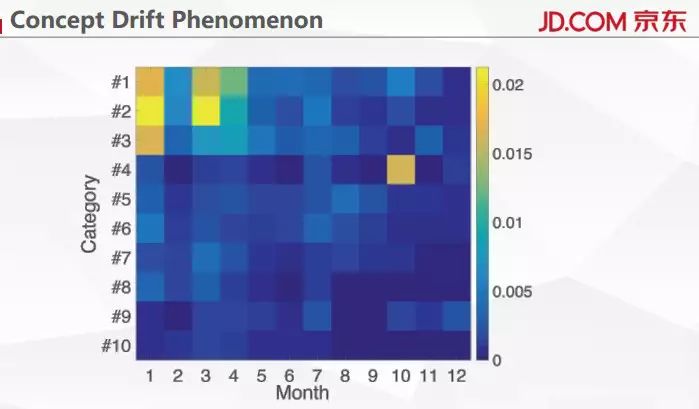
在欺诈领域还有一个非常有意思的现象。欺诈其实是人产生的,既然有人在,整个欺诈行为就会随时间发生变化。上面这幅图里展示的就是欺诈用户喜欢购买的商品。比如在 1 月份可以看到欺诈用户特别喜欢 2 号商品,但随着时间发展,到 10 月份时,这些用户对 2 号商品就没那么感兴趣了。我们的系统需要去适应用户行为的改变,我们需要周期性的对模型进行不断的更新。
建模方法
接下来讲对这个问题的建模方法。我们文章里面只是做了一个欺诈检测,但出现的建模方法同样可以用在商品推荐或是商品建模等其他领域,包括用户画像。
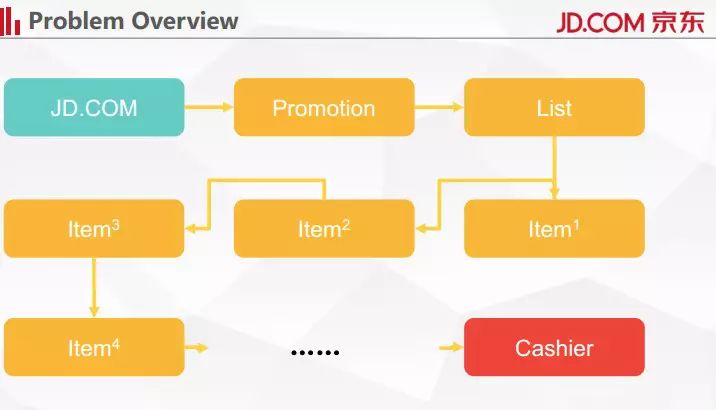
细化我们面临的问题。上图展示的是用户在京东的整个浏览行为序列,首先访问主页,他可能会看一些促销页,然后可能会看一些列表页,然后浏览各种商品,最后进行结算。可以注意到在整个 URL 里面,商品列表页和商品的详情页是最难编码的。

我们的服务器在用户每次点击的时候都会记录下这些信息,比如用户 IP,访问了哪个 URL,包括用户浏览器、操作系统的信息。对这些信息进行编码之后就可以让机器去学习。
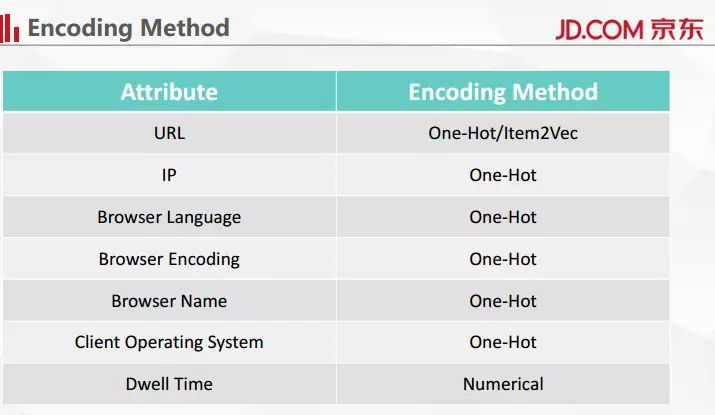
怎么进行编码?其实模型输入的并不是原始信息,在实际操作过程中需要用一些方法来把这些信息变成机器能够认识的信息。我们采用的方法比较简单。可以先忽略 URL,进行 One-Hot 编码。One-Hot 编码指的是在一个向量里面只有一位是 1,其他的位都是 0。
在用户浏览行为里有一个非常重要的信息叫停留时间,停留时间比较难获取,我们采用了统计上比较符合常理的做法——把下一个页面点击的时间和上一个页面点击的时间减一下,然后认为是用户在这个页面上整体停留时间。
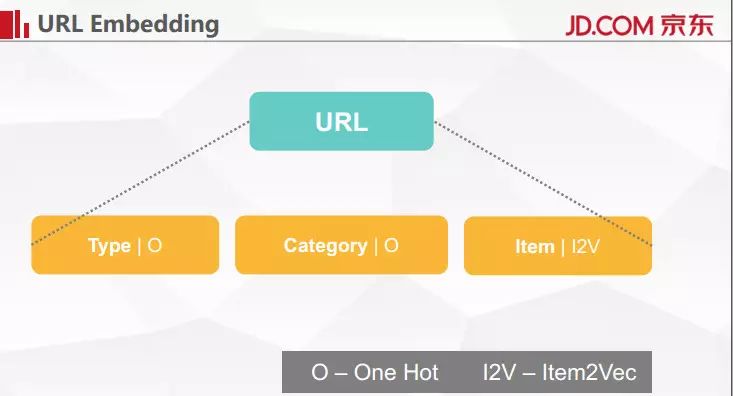
对 URL 的编码我写了两种编码方式,在 URL 里面很多页面都可以归为 Category 或 Item 这两个门类。商品的列表页和详情页实在太庞大了,如果用 one-hot 编码将是一个非常大的数目。
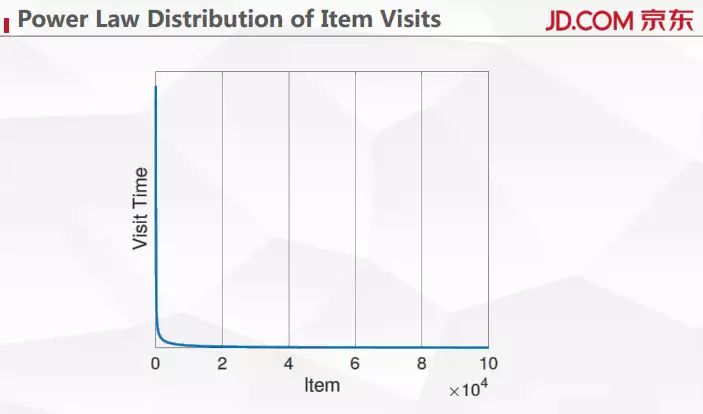
京东上商品的浏览特别符合非常陡峭的幂律分布,我们可以对采集到 session 里面的大部分浏览行为进行 item 编码,如果浏览的商品没出现在编码过的 item 里面,我们就单独进行编码。
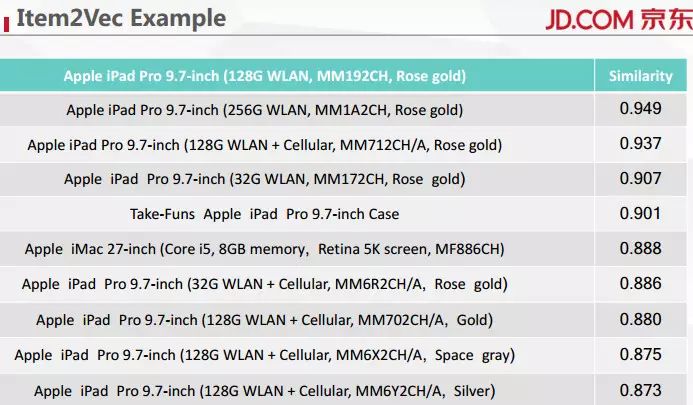
我们编码采用的方式是 Item2Vec,这种方法的思路和 Word2Vec 一样,Word2Vec 相当于把出现在相同语境下的词之间的距离进行最小化。Item2Vec 是先给这个商品赋一个随机向量,然后根据商品在不同语义中出现的情况,对我们赋的向量进行优化。我们在研究中采用了一个 25 位的向量,能覆盖大概 90% 我们所研究的商品。上表展示的就是 Item2Vec 的一个结果。
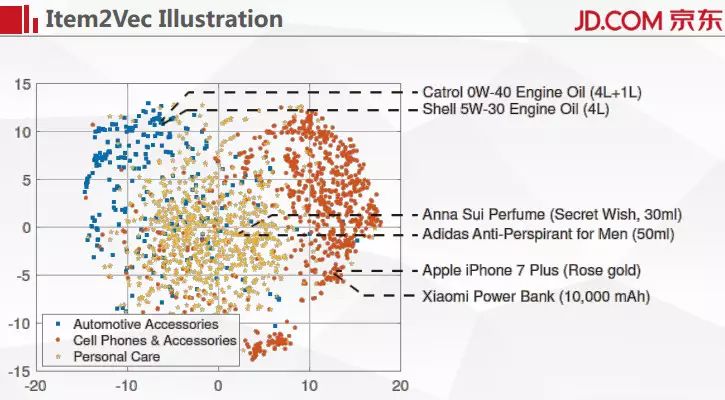
我们来看一个更为广泛的例子,随机在三个品类里面找出若干个商品,然后进行 Item2Vec 编码再进行降维。我们采用了汽车用品、手机和附件、个人护理这三个类别。可以看到这三种类型的商品在这个二维的空间里面比较明显的被分割到三个不同的区域,这说明 Item2Vec 的有效性还是很强的。我们做的 Item2Vec 编码参考的完全是用户的浏览行为,没有跟商品的标题做语意上的匹配。
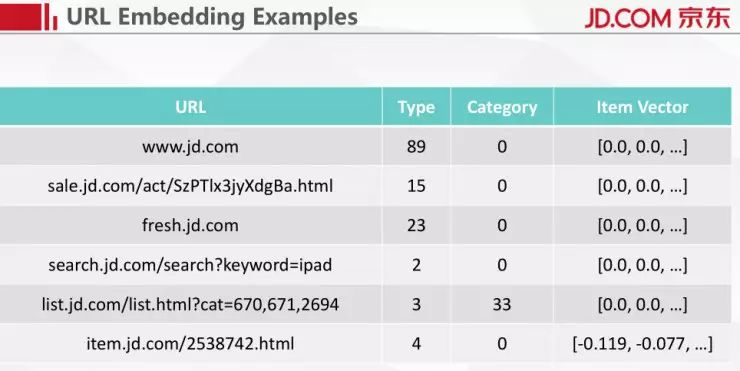
我们可以把 URL 的编码划分成三部分,第一部分是 URL 的类型,第二部分是 category,第三部分是 item Vector。我们把所有用户的点击行为做完了编码之后,每一次点击都可以得到一个编码后的向量,用户的整个浏览行为就可以看成一个向量的组合,最后我们再从数据表里面去找这个 session 是正常的还是被举报过的。
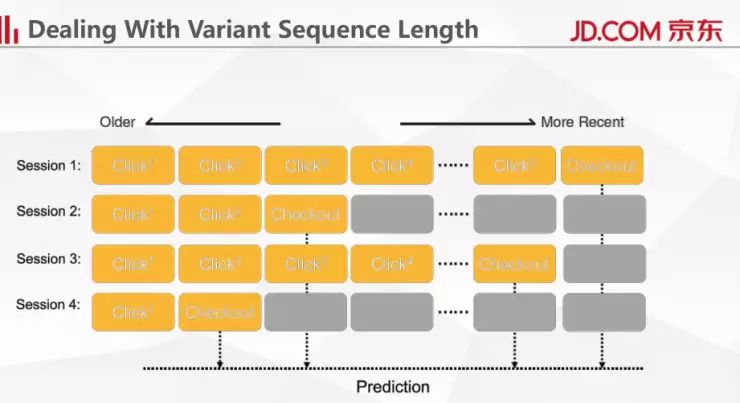
还有一个问题需要解决。在训练神经网络的时候,每一个 session 的长度都可能是不固定的,可能第一个 session 的点击数是六个,第二个 session 的点击数只有三个,那么怎么来处理这种不相等的问题?首先我们确定一个最大点击数目,在文章中我们设置这个数目为 50,也就是说从 checkout 的页面往前数 50 个点击,进行一个截取之后,然后把长度没有达到 50 的后面全都补 0。在取最后结果的时候,一定要在 checkout 位置去取,如果在最后一个位置取的话,会出现错误。
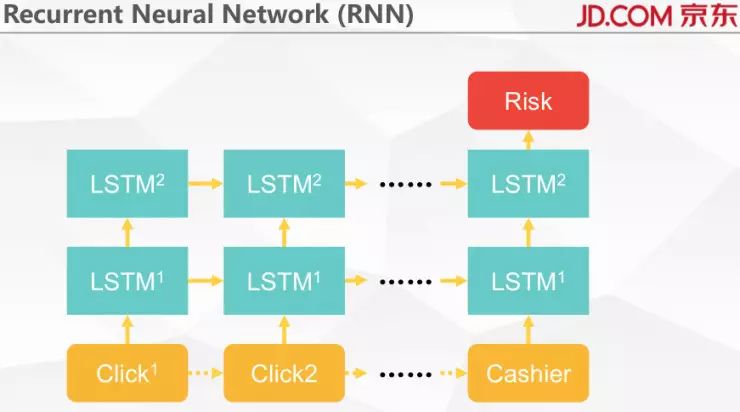
最后把这些送到 RNN 里面学习。我们在研究里面采用的框架是 TensorFlow,所用到的东西都是 TensorFlow 定义好的。我们采用的是如上图 LSTM 的结构,可以采用多层的 LSTM 结构。
如何解决技术难题
接下来讲一下怎么去解决刚才说的那些技术难题。
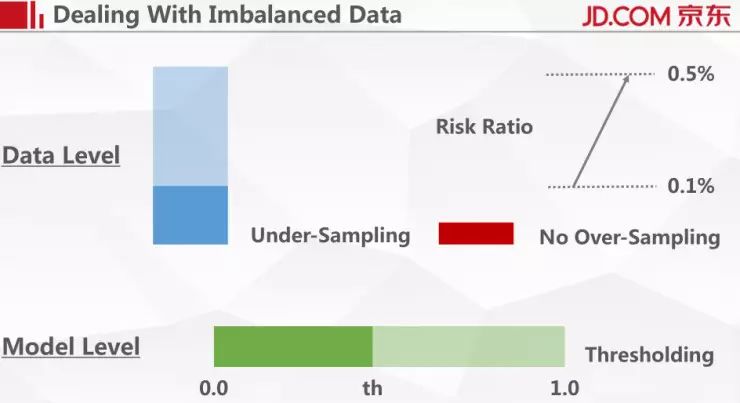
第一是解决非平衡样本问题。在这个工作里面采用两个比较简单的方法,第一个方法是从数据的层面,我们直接把正常用户的数目随机减去 4/5。对于欺诈用户,我们没有做任何操作。在训练数据里原来的占比是 1‰,经过采样之后把数目调整到 5‰。在验证集和测试集上还是保持原来 1‰的占比。
在模型层面,我们采用 Thresholding 法,它的思路非常简单。我们的模型是一个二分类问题,要么欺诈,要么正常,模型输出的是一个连续变量,如果更偏重于 1,我们认为它是欺诈用户的可能性更大。
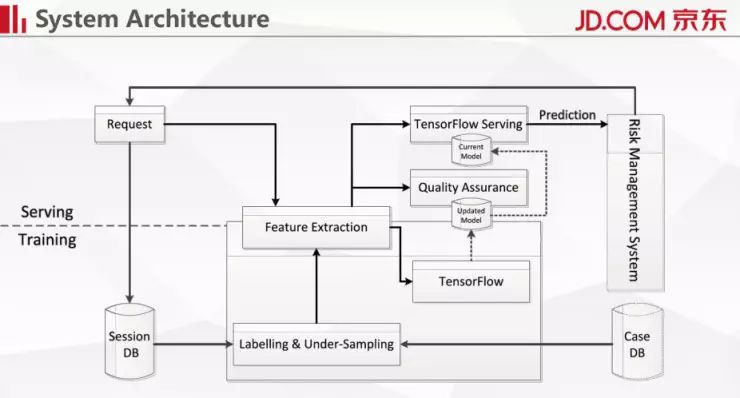
第二个问题就是如何解决庞大的访问量,我们整个系统的架构如上图所示。架构分成两部分,下面是训练,上面是进行预测,训练采用的是 Tensorflow,预测用了 Tensorflow Serving 的开源模块。下面是模型进行滚动更新的部分,更新后的模型会送到上面,然后会有 QA 模块进行决定是否切换掉现有的模型。

我们有两种模型更新的办法——全量数据更新和增量数据更新。全量数据的好处在于每次模型优化能够达到一个比较好的结果,增量数据的好处是不需要把历史数据全都拿过来。从时间上来看,增量更新会比较节省时间和计算资源,我们在这个研究里面采用的是增量更新的办法。
研究成果展示
最后给大家展示一下我们研究的一些结果。

对于非平衡样本问题,用 PR 曲线能有效的看出模型性能。图中是初期的一个结果,现在的准确率比图中高很多。采用 4-64 的性能最好。
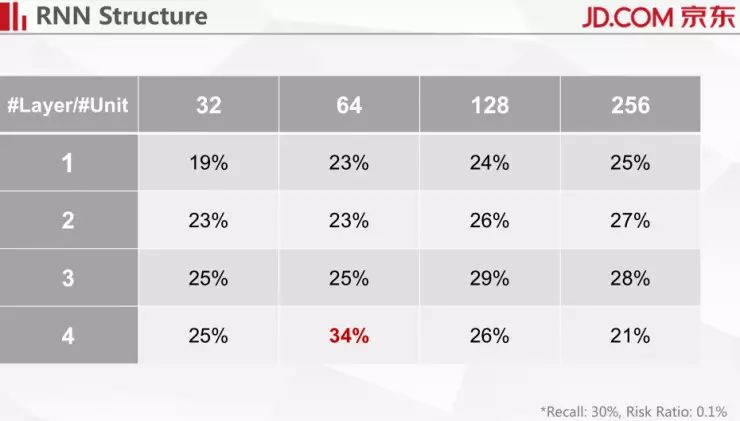
我们还有一个更详细的表,固定 recall 是 30%,异常占比为 1‰。可以看到随着层数的增加,性能还是有一些增加的,但是随着 unit 数目的增加,在有些地方可能就会产生一些过拟合。
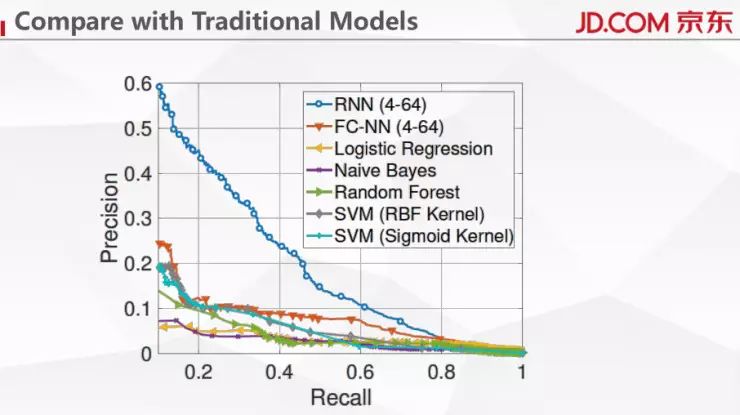
如上图,通过跟传统的一些方法的对比也展示了 RNN 的优越性。
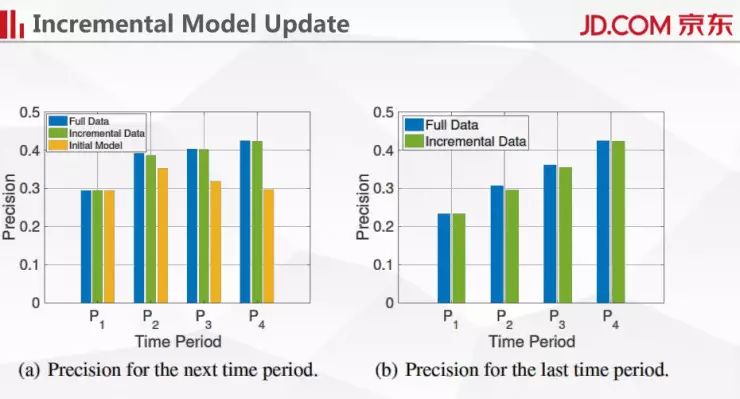
我们也做了一些实验来对比增量模型更新与全量模型更新。我们把数据分成若干时间段,然后用下一个时间段来测试当前时间段模型的性能,橙色线是初始的模型,我们只用第一个时间段的数据训练好模型,后面不进行优化,可以看到橙色线跟另外两条线的差距越来越大,也即随着用户行为的变化,第一个时间段训练的模型越来越不能在实际中使用了。
结果展示

最后展示的是我们做的比较有意思的一个结果。这幅图里用户的行为可以比较明显的区分出来。例如右上角,这部分样本表示在 session 里面没有发现用户在浏览商品,而直接进行了付款,这是为什么?因为我们并没有把用户从第一个商品浏览到最后全部采集下来。后续我们把用户的浏览行为拼接起来,找到之前的 session,这样的话性能会更好。


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
浅析 Geoffrey Hinton 最近提出的 Capsule 计划
▼▼▼



