ACCV2020国际细粒度网络图像识别冠军方案解读、经验总结

极市导读
由极市平台作为官方指定赛事平台的ACCV2020国际细粒度网络图像识别大赛已顺利结束。本文是本次大赛的冠军团队对他们解决方案的解读,包含数据清洗、backbones、BBN、混合精度训练、Tricks、模型融合等经验。>>加入极市CV技术交流群,走在计算机视觉的最前沿

0. 团队介绍

团队来自NetEase Games AI Lab,成员分别为韦嘉,习思,徐文元,张伟东,排名不分先后。
 |
 |
|---|---|
| 韦嘉,NetEase Games AI Lab研究员 |
习思,NetEase Games AI Lab研究员 |
2. 数据集的挑战
1.1. 数据集概要
数据集是从网络上收集的图片数据,jpg格式。
训练数据集:5000类共557169张图片,含标注信息(内含标签噪声)。数据集中包含的类别包括动物和植物。
测试数据集:5000类共100000张图片,不含标注信息。
1.2. 数据噪声
-
脏数据
我们发现有很多脏样本是无法学习的,并且有些类别并不属于动植物。
-
二义性图片
我们注意到在同一张图片上有不同的标签,例如,这两张图片在标签不同的情况下是完全相同的图片。

-
长尾分布
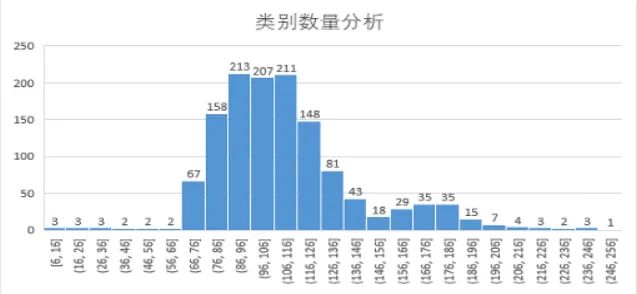
-
混乱类别
发现训练集中约5%的类别样本过于混乱,似乎是其他类别样本的混合

2. 解决方案
2.1 数据清洗
最先做的事情是清洗数据集。为了分析数据集,我们首先将训练数据集划分为训练集和验证集,使用训练集训练模型并统计验证集badcase分布,具体分布如下图。可以看出,在所有badcase中,噪声图片和错误标签占比最多分别是24%和13%。噪声至少占了badcase的37%左右,给训练增加了一定的难度,模型很大概率被不准确的标签误导,因此该比赛清洗数据能提升较大的精度。
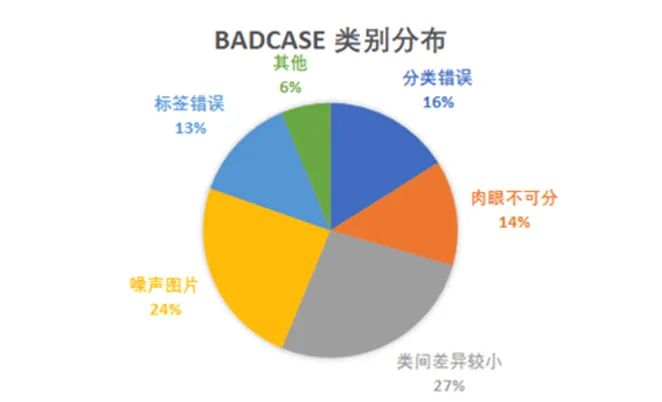
为了应对这种情况,我们针对噪声图片和标签错误尝试了不同方法来清洗数据集。
首先为了清洗部分明显的脏样本,使用模型聚类来聚类并删除共性大的脏样本,例如地图图片,文章图片,图表等。
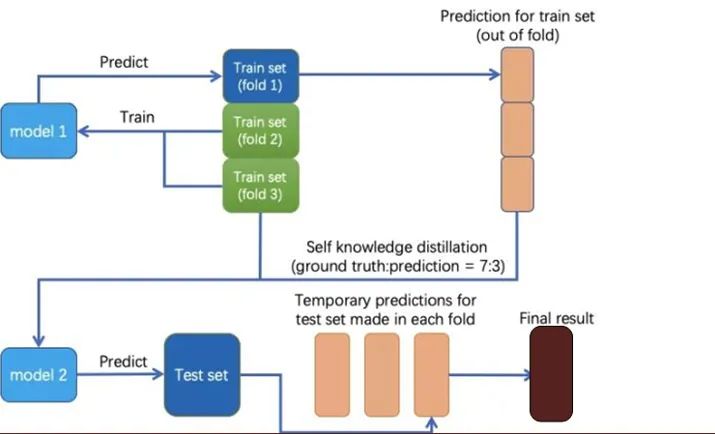
其次,我们使用自蒸馏的方法处理噪声数据。根据分析发现数据集中存在大量的错误标签和二义性样本,为了降低模型的训练难度,我们将所有训练集图片均分为五份,使用4份作为训练集并预测剩下数据,完成五折模型训练,之后预测的每一折验证集组成所有数据集的out-of-fold结果文件,之后将out-of-fold结果与数据集的ground truth label按一定比例混合,组成了新的训练集标签,换句话说,我们给每一个大概率是噪声样本的图片赋予了软化后的标签,从而降低了模型训练难度。
最后,我们再根据新的训练集标签,进一步清洗置信度过低的样本,与此同时,我们兼顾了类别平衡,降低少样本类别被误清除的概率,不至于部分类别图片过少,加剧长尾分布程度,增加模型训练难度。
我们也尝试了其他的去噪方式,比如AUM Ranking等,通过训练模型给每一个样本根据AUM指标进行排序。我们根据AUM删除了部分图片训练模型,从而导致精度明显下降。AUM Ranking还是存在一些坑,我们最后放弃了该方法。
2.2 backbones
Backbones对模型的表现至关重要。我们使用efficientnet, resnet-based的模型和bbn作为backbones。我们可以看到下图中这两种类别之间的唯一区别是头部纹理,带注意力机制的backbones能够聚焦于关键细节,带来更好的表现。

2.3 BBN
在数据分析中发现本次比赛中训练集是典型的长尾分布。长尾分布属于极端的类别不平衡现象,这一现象会削弱一般分类的模型的分类能力。通常来说为了解决这一问题会使用类别再平衡方法,如从数据层面进行再采样,或者从损失函数角度进行加权。
首先被尝试的是在数据层面进行样本强制重采样,在某些类别中少量的样本被不断重复,但并没有对训练起到太多积极作用。其次是使用focal loss和class balance loss这类加权损失函数,但模型精度仍有0.2%~0.3%的下降。
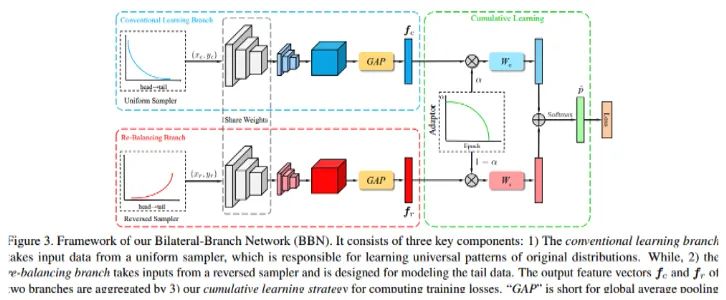
通过调研我们选择了BBN结构,我们最好的单个模型也是由BBN训练的。BBN 模型由两个分支构成,即常规学习分支(Conventional Learning Branch)和再平衡分支(Re-Balancing Branch)。总体而言,BBN 的每个分支各自执行其表征学习和分类器学习任务。顾名思义,常规学习分支为原始数据分布配备了典型的均匀采样器(Uniform Sampler),可用于为识别任务学习通用的表征;再平衡分支则耦合了一个逆向的采样器(Reversed Sampler),其目标是建模尾部数据。接着,再通过累积学习(Cumulative Learning)将这些双边分支的预测输出聚合起来。通过使用bbn训练resnet50,可以将Top 1准确性提高10%以上。此外我们还使用bbn训练了其他的backbones,如resenxt,se-resnext,efficientnet等。

2.5 混合精度训练
上一小节中提到BBN能够极大的提高模型精度,但事实上该模型的训练时间较长,gpu资源占用也比较多。以se-resnext50位主干的BBN在8张V100上不能以256的batchsize运行。而batchsize的大小又直接影响了训练效果与耗时。
为了解决这一问题我们使用了pytorch的拓展插件apex,它能够在只添加少量代码的情况下使用自动混合精度的技术来提高模型的资源占用和训练速度,提高生产力。在实际训练中我们使用的是O1模式,gpu资源占用能够减少一半以上。为我们训练高分辨率的深层模型提供了可能。
2.6 Bag-of-Tricks
在模型训练的过程中也使用了很多tricks,并配置了大量算力资源。对于少样本类别做了数据增广和重采样,并尝试使用focal loss但表现不佳。同时在预测过程中使用ten-crop、multiscale及flip等TTA策略,模型精度有一定提高。与此同时增强模型泛化能力的Mixup和labelsmoothing也能提高模型性能。
以bbn-resnet50为例,baseline准确度为55.7%。清理数据集后,精度可以提高2.6%,Mixup和label smoothing后,精度可以提高1.5%,使用三次KD后,精度可以提高1.1%。我们还使用许多其他技巧。这里不再赘述。
2.7 模型融合
在比赛中已经训练了超过40个模型,不同的backbones,不同的分辨率,不同的训练策略。
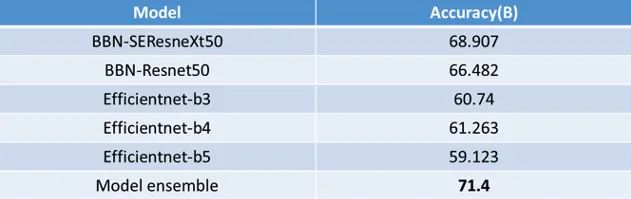
最终最好的单一模型准确性为68.9%。但是即使如此,融合三个精度较低(60%左右)但相关性低的模型(分辨率、loss、backbones等)仍改善性能。最后我们调整了模型权重,以增强更强大的模型,准确率可以提高0.2%左右。
表中列出了我们5个模型的所有结果。最终,我们在排行榜B中获得71.4%的准确度。
3 总结
3.1 我们做了什么
1) ACCV_WebFG5000数据集:5K类,具有大量噪声的550K训练图像;
2) 最终模型在B榜准确性为71.4%,在挑战赛中排名第一。
3.2 我们从竞赛中学到了什么
1) 适用于小型数据集的技巧可能不适用于大型数据集,需要不断快速试错。
2) 数据集中具有多种类型的噪声,在使用常规去噪方法的同时,创新性的引入了类别均衡的去噪方法,提升模型去噪能力。
3) 在模型融合过程中相关度低的模型往往能够取得更好的效果,高相关度模型融合可能会起到反向效果。
4)在计算资源有限的情况下,比起使用小模型,大模型的半精度训练不失为一个更好的选择。
3.3 我们没做什么
1)Backbone,在公开数据集上resnest精度高于resnext和efficientnet,但时间关系没有进行尝试。
2)Ensemble,在模型融合阶段目前采用的是voting,stacking等基于学习的方式由于步骤繁琐,没有进行尝试。
3)Unsupervised learning,使用moco或mocov2等无监督方法获得更为强大的特征提取能力。
报告下载
在 极市平台 公众号后台回复“ACCV”,即可下载冠军团队于ACCV2020 Workshop报告PPT。
参考文献
【1】 Zhou, Boyan, et al. "BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
【2】 Pleiss, Geoff, et al. "Identifying Mislabeled Data using the Area Under the Margin Ranking." arXiv preprint arXiv:2001.10528
【3】 He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
【4】 Lin, Tsung-Yi, et al. "Focal loss for dense object detection." Proceedings of the IEEE international conference on computer vision. 2017.
【5】 Tan, Mingxing, and Quoc V. Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." arXiv preprint arXiv:1905.11946 (2019).
【6】 He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
【7】 Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
【8】 Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
【9】 Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." arXiv preprint arXiv:1710.09412 (2017).
【10】 Yun, Sangdoo, et al. "Cutmix: Regularization strategy to train strong classifiers with localizable features." Proceedings of the IEEE International Conference on Computer Vision. 2019.
【11】 He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
【12】 Chen, Xinlei, et al. "Improved baselines with momentum contrastive learning." arXiv preprint arXiv:2003.04297 (2020).
推荐阅读







