深度学习角度 | 图像识别将何去何从?
整理 | 专知
本文主要介绍了一些经典的用于图像识别的深度学习模型,包括AlexNet、VGGNet、GoogLeNet、ResNet、DenseNet的网络结构及创新之处,并展示了其在ImageNet的图像分类效果。这些经典的模型其实在很多博文中早已被介绍过,作者的创新之处在于透过这些经典的模型,讨论未来图像识别的新方向,并提出图像识别无监督学习的趋势,并引出生成对抗网络,以及讨论了加速网络训练的新挑战。文章梳理了用于图像识别的深度学习方法的脉络,并对将来的挑战和方法做了分析,非常值得一读!专知内容组编辑整理。
在过去的几年中,深度学习绝对主导了计算机视觉,在许多任务和相关竞赛中取得了最好效果。 这些计算机视觉竞赛中最受欢迎、最知名的竞赛是ImageNet。ImageNet竞赛任务是:让研究人员创建一个模型,对给定的图像进行分类。
过去的几年里,深度学习技术极大推进了这场比赛,甚至超越了人类的表现。
今天我们要回顾一下这方面的进展,从而了解深度学习是如何推动其发展的,了解我们可以从中学到什么,以及我们走到哪一步。
▌ImageNet的挑战
那么ImageNet挑战有什么难的呢? 让我们先看看数据。ImageNet分类任务的数据是从Flickr和其他搜索引擎收集的,由人类手动标记,总共有1000个类别,每个图像属于其中一个。
数据集的分布如下表所示。

ImageNet Dataset
到2012年,ImageNet拥有近130万个训练图像。 这样一个大规模的图像分类任务的主要挑战是图像的多样性。在这里我们可以看一下这个例子。
看看下面的图片。 在左侧,我们看到来自另一个图像分类challange的一些示例图像:PASCAL。在PASCAL挑战中,只有大约20,000个训练图像和20个对象类别。 这个挑战的类别:如“鸟”,“狗”和“猫”,如下所示。说到ImageNet的挑战,这是一个全新的比赛。 ImageNet并没有一个叫做“狗”的普通类,它包含了各种各样的狗。 事实上,ImageNet并没有PASCAL的“狗”类别,而是有120种不同品种的狗类(更加细粒度:如哈士奇、德国牧羊犬、秋田犬等,而不是统一的“狗”类)!因此,我们用于此任务的任何模型/算法都必须能够处理这些非常“细粒度”和“特定”的类,即使它们看起来非常相似并且很难区分。
更技术性地讲,我们希望最大化类间差异性。这意味着我们需要两个图像,每个图像包含一种不同类型的鸟类,因此即使它们都是鸟类,但在我们的数据集中,它们都属于不同的类别。

Inter-class Variability(类间差异性)
这是ImageNet的另一个具有挑战性的特性:同一个类的对象可以看起来很不一样。 让我们看看下面的图片。左边的两个都来自“orange”类,右边的两个都来自“pool table”类。 然而,每一对图像看起来都不一样!对于人类,我们可以看到其中一个桔子被切开,另一个桔子没被切开。 我们也可以看到一张桌子的图片放大了,另一张没有放大。这就是所谓的类内差异性。 我们希望尽量减少这种变化,因为我们希望在我们的深度学习模型中,同一类的两幅图像看起来是相似的。

Intra-class Variability(类内差异性)
有了这些图像分类的挑战,让我们来回顾一下深度学习是如何在这个任务上取得重大进展的。
▌深度学习在图像分类方面的快速发展
自2012年以来,几乎每年都在为图像分类任务开发深度学习模式方面取得重大突破。由于数据规模庞大且具有挑战性,ImageNet挑战一直是衡量进展的主要标杆。在这里,我们要看看深度学习这个任务的进展,以及一些主要网络结构。
开始的一切:AlexNet
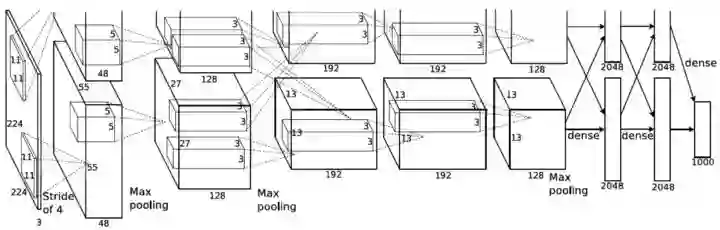
早在2012年,多伦多大学就在NIPS上发表一篇论文,效果则是令人震惊的。该论文是“ImageNet Classification with Deep Convolutional Neural Networks”。
(地址:
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf )
在ImageNet挑战中错误率降低了近50%,它成为“现有领域中最有潜力的论文之一”,这在当时是前所未有的进展。
本文提出使用深度卷积神经网络(CNN)进行图像分类任务。与今天使用的相比,这是相对简单的。这篇论文的主要贡献是:
第一个成功使用深度卷及网络进行大规模图像分类。这是因为ImageNet提供了大量标记数据,以及在两个GPU上使用并行计算来训练模型。
他们使用ReLU作为非线性激活函数,发现它们相对于tanh函数表现更好,训练时间更短。ReLU非线性激活函数现在几乎成为深度网络的默认激活函数。
他们使用数据增强技术,包括图像翻转,水平反射(horizontal reflections)和均值减法(mean subtraction)。 这些技术如今被广泛用于许多计算机视觉任务。
他们使用dropout层来解决训练数据过拟合的问题。
他们提出的连续卷积和pooling层的方式,最后是全连接层,仍然是当今许多最先进网络的基础。
基本上,AlexNet提供的设置和baseline都称为计算机视觉领域CNN的默认技术!
更深:VGGNet
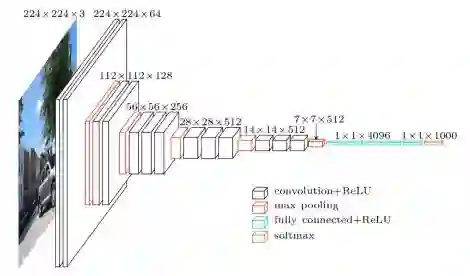
VGGNet的论文“Very Deep Convolutional Neural Networks for Large-Scale Image Recognition”于2014年出版,进一步使用更多卷积和ReLU加深卷积网络。他们的主要想法是,你并不需要任何花哨的技巧来提高高精度。只要有很多小的3x3卷积和非线性激活函数的更深层的网络就可以做到这一点! VGGNets的主要贡献是:
只使用3x3大小的过滤器,而不是AlextNet中使用的11x11。他们表明,两个连续的3×3卷积与单个5×5卷积具有等价的接受场或“视场”(即它所看到的像素);相似地,三个连续的3×3卷积相当于一个7×7卷积。这样做的好处是可以模拟更大的过滤器,同时保持较小过滤器尺寸的好处。较小的过滤器的第一个好处是减少了参数的数量。其次是能够在每个卷积之间使用ReLU函数,将更多的非线性引入到网络中,使决策函数更具有判别力。
随着每层输入volumes(input volumes)的空间尺寸减小(作为pooling层的结果),volumes的深度增加。这背后的想法是,随着空间信息的减少(从max pooling下采样),它应该被编码为更多的可区分特征,以用于更准确的分类。因此,特征图的数量随着深度增加而增加,以便能够捕获这些用于分类的特征。
它引入了一种新的数据增强方式: scale jittering。
使用Caffe工具箱构建模型。 此时,深度学习库越来越受欢迎。
VGGNet:https://arxiv.org/pdf/1409.1556.pdf
更深:GoogLeNet和Inception模块
GoogLeNet架构是第一个真正解决计算资源问题以及“Going Deeper with Convolutions”论文中的多尺度处理。随着我们的分类网络越来越深,我们必须得使用大量的内存。另外,过去已经提出了不同的计算滤波器尺寸:从1x1到11x11; 你怎么决定该用哪一个?inception模块和GoogLeNet解决了所有这些问题,具体贡献如下:
GoogLeNet:
https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf
通过在每个3x3和5x5之前使用1x1卷积,初始模块减少了通过每层的特征映射的数量,从而减少了计算量和内存消耗!
初始模块具有全部并行的1x1,3x3和5x5卷积。这背后的想法是通过训练让网络决定什么信息将被学习和使用。它还允许进行多尺度处理:模型可以通过较小的卷积和较大卷积的高抽象特征来恢复局部特征。
GoogLeNet是第一个提出CNN层并不总是必须按顺序排列。本文的作者表示,您还可以增加网络宽度而不仅仅是深度以获得更好的性能。
跳过一条捷径:ResNet
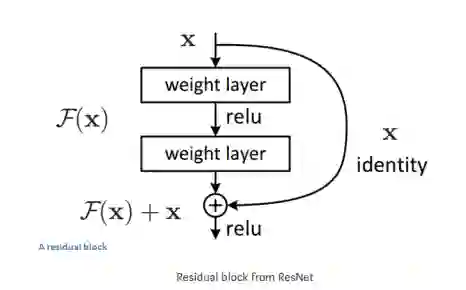
自2015年在“图像识别的深度残差学习”一文中发布以来,ResNet已经在很多计算机视觉任务中提高了准确性。ResNet架构是ImageNet上第一个超过人类级别的性能测试的模型,而他们在residual learning方面的主要贡献在今天许多最先进的网络中经常被默认使用:
ResNet:https://arxiv.org/pdf/1512.03385.pdf
文章揭露了:将层进行简单的堆叠,从而使网络非常深并不总是有帮助,也可能取得相反的结果。
为了解决上述问题,他们引入了结合skip-connections的残差学习(residual learning)。这个想法是,通过添加skip连接作为快捷方式,每一层层可以直接访问前一层的函数,允许特征信息更容易地在网络上进行传播。 它也有助于训练,因为梯度能更高效地反向传播。
第一个“超深”网络,通常使用超过100-200层。
▌把shortcuts做到极致:DenseNet

“Densely Connected Convolutional Networks”文章中引入DenseNets,Shortcut被发挥到了极致。DenseNets扩展了Shortcut的想法,但比ResNet具有更密集的连接:
DenseNet:https://arxiv.org/pdf/1608.06993.pdf
DenseNets中每层以前馈的方式连接到其他层。 这允许每一层使用所有前面的层的所有特征图作为输入,并且它自己的特征图被用作所有后续层的输入。
这里通过串联而不是在ResNets中使用的附加来完成的,这样原始特征直接能流过每一层。
效果比ResNets更好。 DenseNets帮助缓解梯度消失问题,加强特征传播,促进特征重用,大幅减少参数数量。
这些是在过去几年中图像分类领域的主要网络架构。 目前已经取得了很大的进展,这个新技术可以解决许多现实世界的问题,这是令人兴奋的。 现在只剩下一个问题了..
▌我们该何去何从
图像分类的深度学习研究一直蓬勃发展! 我们已经采取了更多的步骤来改进这项任务的方法,其表现甚至超越了人类的表现。 深度神经网络现在被广泛用于许多企业的图像分类,甚至是许多新的启动技术的基础。
所有这些进展非常令人鼓舞的,但我们必须始终努力改进。 深度学习模型在图像分类中仍然存在很多挑战。 如果我们想要向前发展,必须重视这些挑战。 在这里,我将回顾一些我认为重要的研究人员正在积极尝试解决的问题:
从有监督到无监督学习
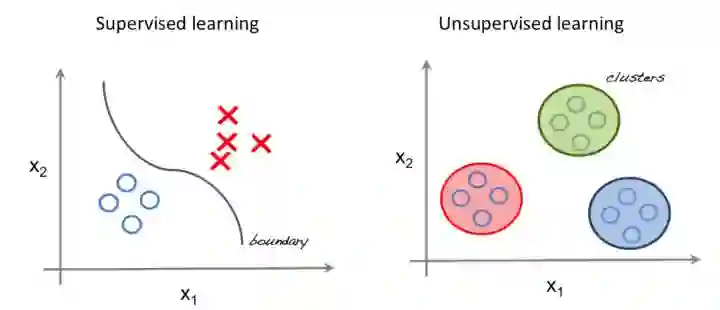
示例图:有监督学习和无监督学习
目前,大多数用于计算机视觉任务深度学习方法都是有监督学习。 这意味着我们需要大量标记的训练数据。 这些数据既繁琐又昂贵。想一想:ImageNet的挑战有130万个训练样例,有1000个不同的类别! 一个人需要获取所有的数据,浏览每张图片,然后贴上标签; 这可是一个体力活。
大多数情况下,当一个企业想为自己的特定应用程序应用图像分类网络时,他们必须使用迁移学习来微调预先训练好的ImageNet网络。为了做到这一点,他们仍然需要收集大量自己的数据并打标签; 这是很乏味和昂贵的工作。
研究人员正在努力解决这个问题。 并取得了一系列进展,如快速有效的迁移学习,半监督学习和一次性学习等方法,越来越多的工作正在进行。我们可能不会直接跳到无监督学习,但是这些方法的研究是朝着正确的方向迈出的重要一步。
Defending against our adversaries(防御对抗样本)

使用生成对抗网络(GANs)的日益流行已经揭示了图像分类的新挑战:对抗图像(Adversarial Images)。 对抗图像是一个简单的图像,其类别对人类看起来是很容易区分的,但在深度网络中导致很大的失败。 看看上面的图片。 虽然只有轻微的扭曲(看起来),但是深度网络却把图像从熊猫分类到长臂猿!
对我们人类来说,类别很明显,形象仍然是一只熊猫,但由于某种原因,它会导致深层网络的任务失败。 这在现实世界的应用中可能是非常危险的:如果你的自动驾驶汽车不能识别行人,而是将其运行过来呢? 部分问题可能源于我们对深度网络内部没有充分理解。无论如何,研究人员正在积极研究这个具有挑战性的问题。
加速处理过程
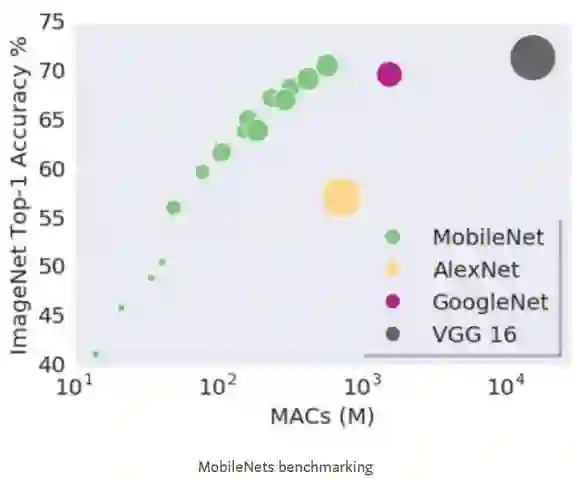
深度学习的进步很多是基于硬件进步,特别是GPU的改进所推动的。 GPU允许并行高速计算。深度学习需要大量的矩阵运算; GPU擅长执行这些操作。 这进步太棒了,但并不是任何地方都有GPU!
许多最先进的网络,包括上面已经讨论过的网络,只能在高端GPU上才能勉强运行。移动设备是一个巨大的市场,怎么服务于这个市场是很重要的。此外,随着网络越来越深,往往需要更多的内存,这使更多的设备无法训练网络!
这方面的研究最近实际上已经有了很大的提高。MobileNets是一种在移动设备上直接运行深层网络的结构。 他们使用不同的卷积风格来减少内存消耗和训练时间。
▌总结
我们看到了图像分类的难点,并回顾了在深度学习领域取得的惊人进展,我们也看到了当前的一些挑战,以及如何用新的科学的方法来应对这些挑战。
参考链接:
https://towardsdatascience.com/deep-learning-for-image-classification-why-its-challenging-where-we-ve-been-and-what-s-next-93b56948fcef

今日推荐
《Hadoop深度学习》
一本书读懂深度学习来龙去脉,概览Hadoop如何玩转深度学习
快速了解深度学习基本概念
深度学习模型在大数据上的表现
HDFS、Map-Reduce、YARN、Deeplearning4j如何实现深度学习模型
Hadoop如何实现分布式卷积神经网络和循环神经网络
受限玻尔兹曼机以及分布式深度信念网络及其实现示例
自动编码器
分布式环境中常见机器学习应用的设计