【初学者系列】目标检测算法YOLO原理解读
【导读】目标检测分两大门派:single-shot detectors以及two-stage detectors。前者注重检测的速度,后者注重检测的精度,当然后者所用的训练时间长。yolo属于前者,今天这篇文章带大家了解一下yolo的原理。
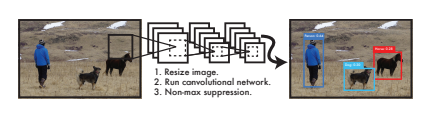
图一:yolo检测系统
原理解读
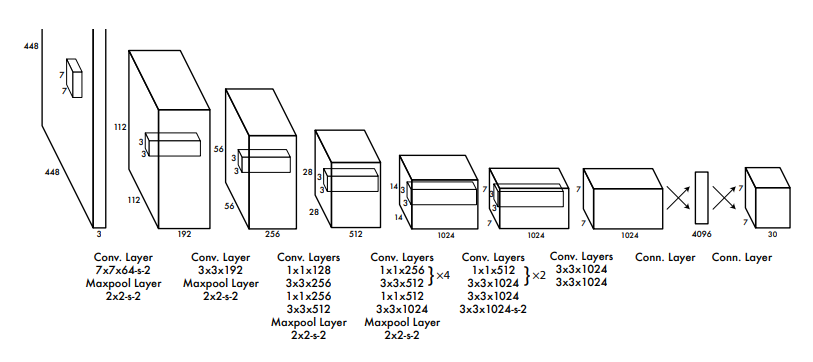
图二:yolo原理图
由图可以看出,yolo网络有24个卷积层和2个全连接层,其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
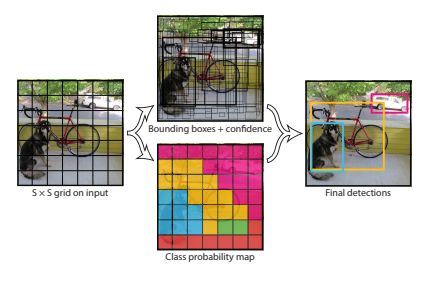
图三:网络模型
YOLO将物体检测作为回归问题求解,它将输入图像分成SxS个格子,每个格子输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。因此,YOLO网络最终的全连接层的输出维度是 S*S*(B*5 + C)
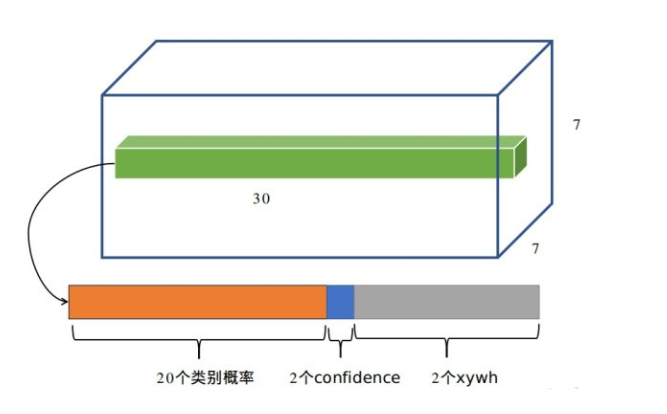
图四:yolo网络的输出的网格
其中,confidence表示:cell预测的bounding box包含一个物体的置信度有多高并且该bounding box预测准确度有多大,用公式表示为:
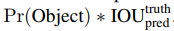
这里,我们再讨论一下yolo的损失函数。论文中损失函数定义为:

我在网上找了一些图片解释:


参考链接:
https://blog.csdn.net/gzs0927/article/details/78308786
并不是网络的所有输出都要计算loss,具体地说:
有物体中心落入的cell,需要计算分类损失,两个predictor都要计算置信度损失,预测的bounding box与groud truth IOU较大的那个predictor需要计算xywh损失。
最关键的部分,没有物体中心落入的cell,只需要计算置信度(confidence)损失。
原始论文地址:
https://arxiv.org/abs/1506.02640
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程


