前Twitter资深工程师详解YOLO 2与YOLO 9000目标检测系统

AI研习社按:YOLO是Joseph Redmon和Ali Farhadi等人于2015年提出的第一个基于单个神经网络的目标检测系统。在今年CVPR上,Joseph Redmon和Ali Farhadi发表的YOLO 2进一步提高了检测的精度和速度。这次讲座的主讲人为王东,前硅谷资深工程师。
讲解顺序和论文结构类似,先讲YOLO 2的网络结构,重点分析如何产生目标边框和分类,以及相关的损失函数。训练YOLO 2的第一步是在ImageNet上预先学习darknet-19,在224x224图像上,它仅需5.58个G-ops。此外,YOLO 2在VOC2007,VOC2012和COCO检测数据集上有很好的表现。
在YOLO 2的基础上,论文中进一步提出了YOLO 9000,可以产生9418个类别的目标检测。首先是需要建立一个基于wordNet结构的wordTree。这个树包含imagenet上最流行的9000个分类,还有COCO的80个大类。YOLO 9000的最后一层采用层次分类的方法,来计算400多个条件概率,用它来产生目标的最终分类。

目标检测
首先是目标检测,目标检测和图像分类的不同是图像分类只需要识别出图中的物体,而目标检测需要在图片中精确找到物体所在位置,并标注出物体的类别。物体的位置一般用边框(bounding box)标记,一个图像中可能有好几个边框,目标检测需要给出边框里物体的类别和概率。
关于YOLO2

YOLO2结构
YOLO 2采用神经网络结构,有32层。结构比较常规,包含一些卷积和最大池化,其中有一些1*1卷积,采用GoogLeNet一些微观的结构。其中要留意的是,第25层和28层有一个route。例如第28层的route是27和24,即把27层和24层合并到一起输出到下一层,route层的作用是进行层的合并。30层输出的大小是13*13,是指把图片通过卷积或池化,最后缩小到一个13*13大小的格。每一个格的output数量是125(5*25),5是指对每一个13*13的小格配有5个边框,25则是指每一个边框输出了25个浮点数。25个是YOLO 2对VOC的结构。VOC一共有20个class,在25个数中,有20个是class的probability,剩下的5个中,有四个表示stx、sty、tw、th,这4个来识别边框的位置和大小,还有一个数是confidence,表示边框预测里有真正的对象的概率。所以一共是13*13*125个数。

YOLO2 Forward 计算边框
现在讲一下怎样把stx、sty、tw、th变成输出边框。如右图所示,里面的σ(tx)可以理解为stx,σ(ty)可以理解为sty。每一个输出的bbox是针对于一个特定的anchor,anchor其实是参考bbox的width及height。对于VOC来讲,产生了5个固定的参考。
如图,给出了stx、sty、tw、th之后,通过简单的公式,就可以计算出最后输出的边框的位置和大小。具体是否要输出当前的边框,它的概率,还有生成的物体的类别,这个取决于后面的probability和confidence。Confidence表示有没有物体,假设有物体之后,probability表示物体的概率。

通过将confidence和最大可能输出的类的probability相乘之后,要是得出的结果大于门限0.24,就会输出当前计算出的bbox的大小和位置,同时会输出是哪一个类,probability大小是多少。一共会生成13*13*5个bbox,然后根据probability,通过filter,产生出最后预测的物体和其边框。

YOLO2例子
举一个例子,就是最前面那个有狗,有轿车,有自行车的图像,比较图中最后的三行就可以看出来,里面有轿车,狗和自行车,也能看到probability和bbox分别是什么,它们分别表示概率、大小和位置。具体来讲,从第一行,可以看出轿车的class_id为6,通过row和col可以看出大概的位置,还给出了anchor_id。第二行可以看到轿车的confidence和stx。

YOLO2 损失函数
前面讲的是forward的过程,即给了一个图像和神经网络,怎么得到识别的物体概率和位置。那么具体的训练过程是如何的呢,怎么去进行训练?论文了中给了一个损失函数。要是给予一个合适的损失函数,给一定的数据去训练,那么神经网络就会得到好的表现。
进行训练的一共有四类loss,他们weight不同,分别是object、noobject、class、coord。总体loss是四个部分的平方和。具体的计算步骤以及如何选择过程如PPT所示。
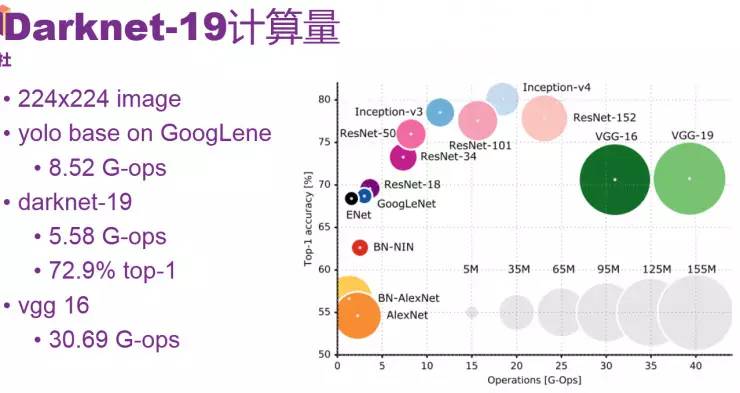
Darknet-19计算量
上面讲述了训练函数和训练对象,大家都需要先选择预训练函数。另外,对于YOLO 2来说,主要是想提高精度和速度,重点是base network要好。YOLO 2采用的是Darknet-19预训练模型。右图是在ImageNet上使用的一些模型,分别给出了他们的计算量和精度。在224x224的图片上,图中VGG16需要30.69个G-ops,基于GoogLeNet的YOLO需要8.52个 G-ops。而Darknet-19更小,G-opsS是5.58。
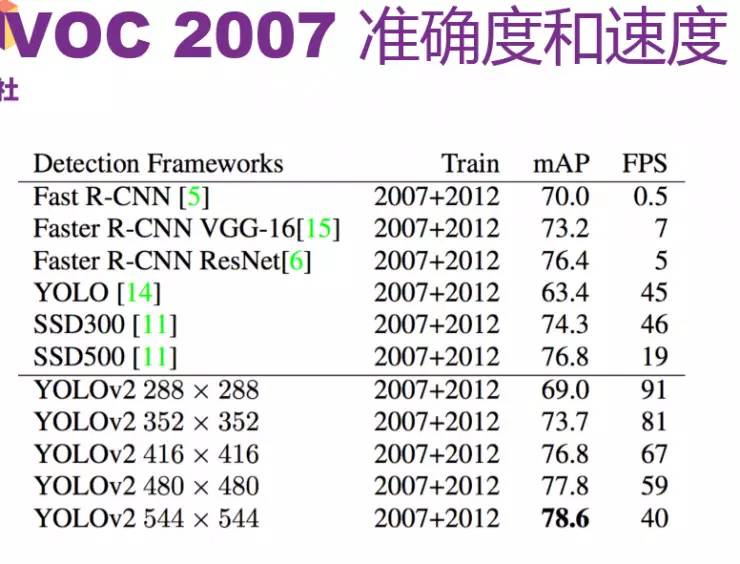
VOC 2007 准确度和速度
论文中列出了一些YOLO 2在标准目标检测集上的表现,由于YOLO 2网络只包含卷积层和池化层,因此可以接受任意尺寸的图像输入。从图中可以看到R-CNN和SSD的精度也是比较高的,但SSD是基于VCC-16来预训练,fps比较慢。YOLO 2的精度相对YOLO提高了很多,速度也有相应提升。对于YOLO 2,不同的图像大小也会产生不同的mAP。
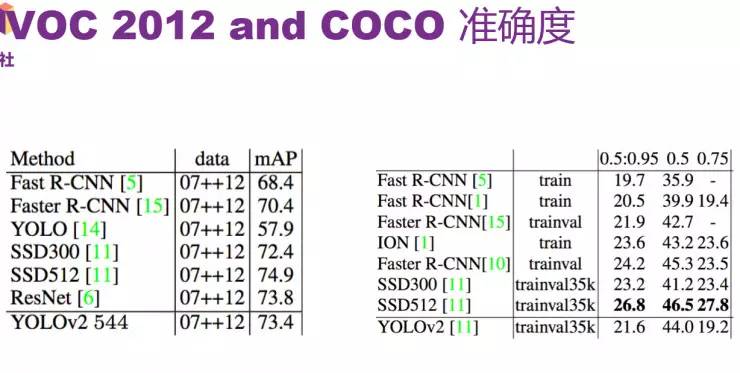
在VOC 2012和COCO上的准确度
接下俩是在VOC 2012和COCO上的准确度,COCO是比VOC难的用于目标检测的benchmark,COCO里有80个类, VOC里有20个。从图中可以看出SSD的精度比YOLO 2要高,可能的原因是COCO里有比较小的物体。从图中也可以看出YOLO 2的速度依然很快。

YOLO与YOLO2的比较
从图中可以看到采用不同的步骤之后,YOLO 2相较YOLO的提升。可以看到mAP明显提高。

与Faster-rcnn的比较
以前基于rcnn的过程不是一次计算出来的,首先要前向计算出proposal,然后再去go through下面的层,一个一个proposal去分类,所以基于rcnn的网络会比较慢。

SSD
SSD是当前最精确的一种目标检测算法,是基于单个神经网络。如图,前面几层是VGG网络,它主要是加入卷积特征层,得到不同尺度的特征层,从而实现多尺度目标检测。对于每个添加的特征层,使用一组卷积滤波器,可以得到一组固定数目的目标检测的预测 。
SSD 方法获取目标位置和类别的机理跟YOLO方法一样,都是使用回归,但是YOLO对小目标检测效果不好,而SSD则在不同的feature map上分割成grid然后去做回归,效果会好一点。
前面讲的就是YOLO2的部分,在一些小的物体的检测上不如ssd,但在精度、准确度上都和ssd很接近,最大的优点是非常快。
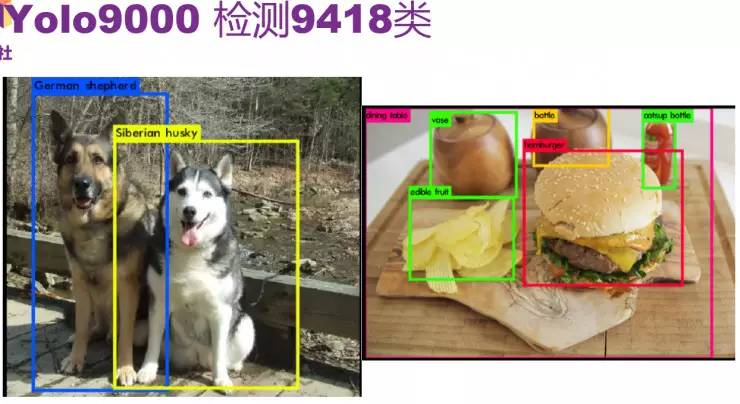
YOLO 9000
YOLO 9000是论文的第二部分,它的主要优点是可以检测9418个类。这个数目非常惊人,因为检测数据不容易得到,人工标记比较困难。
图中是论文里的几个检测的例子。
YOLO 9000的基本触发是用少量的有检测标注的数据和大量的图像分类数据合并到一块,来互相帮助,产生出可以生成很多类的预测。
具体实践过程

首先建立标签树(WordTree),这个树很大,如图红色的部分是ImageNet里面最流行的九千个类别,检测数据是来自COCO里面的80个类。这个标签树是基于WordNet构建的,总共9418个类,1846个内部节点。可以在每个tree的节点做一个softmax,节点概率是从原点的路径上的条件概率的乘积,最后输出的标签是节点概率高于阈值(0.5)的最深节点。

使用WordTree整合了数据集之后就可以在数据集(分类-检测数据)上利用层次分类的办法训练模型,使该系统可以识别超过9000种物品。训练时检测数据wordTree上的路径都有class loss,而imagenet数据只有class loss 和noobj loss。

YOLO 9000结构
如图所示,与之前相比,它的结构简化到24层,第23层是17*17*28269,17*17和以前YOLO 2的13*13类似,只是把prediction网格变成了17*17。然后每个位置有28269(3*(4+1+9418)),3是指每一个位置给了三个bounding box,每个bounding box包含有stx,sty,tw,th,confidence和9418个类。给了这些数之后就可以通过WordTree产生所需要的bbox等。

YOLO 9000的结果
如图是YOLO 9000在ilsvrc 2014上的表现。Ilsvrc 2014一共有200个category,ssd300在这个数据集上训练完以后可以得到43.4mAP,YOLO 9000只能得到19.7mAP。区别是YOLO 9000在训练过程中根本没有利用ImageNet上的ilsvrc训练数据,只利用了COCO和ImageNet数据,能得到19.7也是非常不错的结果。图右可以看出在不同类别的图像检测上的表现,可以看到在检测动物时表现最好,因为COCO上有一些动物的类。

总结
YOLO 2相比YOLO,提高了速度和准确率,基于darknet-19模型,除去完全连接层,用了边框聚类,两层组合,采用图像多分辨率的训练。
YOLO 9000可以利用无边框的数据和有边框的数据一起来实现9418类的监测。采用wordTree层次分类的办法。
下面为大家提供一些github上的开源代码,有训练好的YOLO 2和YOLO 9000模型。
https://pjreddie.com/darknet/
https://github.com/philipperemy/yolo-9000
▼点击可看直播视频


AI 研习社长期接受优秀文章投稿
同时免费为优质企业推广招聘信息
有意者请联系 jiazhilong@leiphone.com

后台回复 “我要进群” 加入 AI 技术讨论群
新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络/AI/大数据、教程、论文!】
内推时间 | AI研习社帮你找了28个职位
▼▼▼




