【干货】3万字剖析强化学习在电商环境下应用
新智元推荐
来源:阿里巴巴
【新智元导读】淘宝的搜索引擎涉及对上亿商品的毫秒级处理响应,而淘宝的用户不仅数量巨大,其行为特点以及对商品的偏好也具有丰富性和多样性。本文介绍了4篇强化学习论文,结合淘宝的实践经验,用近三万字深度剖析了强化学习在电商环境下进行实时搜索排序、分层流量调控、搭建虚拟环境等的应用。
论文地址:https://pan.baidu.com/s/1hrJttqs

随着搜索技术的持续发展,我们已经逐渐意识到监督学习算法在搜索场景的局限性:
搜索场景中,只有被当前投放策略排到前面的商品,才会获得曝光机会,从而形成监督学习的正负样本,而曝光出来的商品,只占总的召回商品中的很小一部分,训练样本是高度受当前模型的 bias 影响的。
监督学习的损失函数,和业务关注的指标之间,存在着不一致性。
用户的搜索、点击、购买行为,是一个连续的序列决策过程,监督模型无法对这个过程进行建模,无法优化长期累积奖赏。
与此同时,强化学习的深度学习化,以及以 Atari 游戏和围棋游戏为代表的应用在近几年得到了空前的发展,使得我们开始着眼于这项古老而又时尚的技术,并以此为一条重要的技术发展路线,陆陆续续地在多个业务和场景,进行了强化学习建模,取得了一些初步成果,相关的工作已经在整理发表中。同时我们也深知,目前强化学习的算法理论上限和工业界中大规模噪声数据之间,还存在着很大的 gap,需要有更多的智慧去填补。
基于强化学习的实时搜索排序调控
淘宝的搜索引擎涉及对上亿商品的毫秒级处理响应,而淘宝的用户不仅数量巨大,其行为特点以及对商品的偏好也具有丰富性和多样性。
因此,要让搜索引擎对不同特点的用户作出针对性的排序,并以此带动搜索引导的成交提升,是一个极具挑战性的问题。传统的 Learning to Rank(LTR)方法主要是在商品维度进行学习,根据商品的点击、成交数据构造学习样本,回归出排序权重。
尽管 Contextual LTR 方法可以根据用户的上下文信息对不同的用户给出不同的排序结果,但它没有考虑到用户搜索商品是一个连续的过程。这一连续过程的不同阶段之间不是孤立的,而是有着紧密的联系。换句话说,用户最终选择购买或不够买商品,不是由某一次排序所决定,而是一连串搜索排序的结果。
图1:搜索的序列决策模型
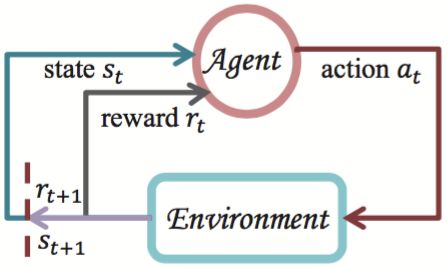
图2:强化学习agent和环境交互
本文接下来的内容将对淘宝具体的方案进行详细介绍。
强化学习为何有用?——延迟奖赏在搜索排序场景中的作用分析
我们用强化学习(Reinforcement Learning,RL)在搜索场景中进行了许多的尝试,例如:对商品排序策略进行动态调节、控制个性化展示比例、控制价格 T 变换等。
虽然从顺序决策的角度来讲,强化学习在这些场景中的应用是合理的,但我们并没有回答一些根本性的问题,比如:
在搜索场景中采用强化学习和采用多臂老虎机有什么本质区别?
从整体上优化累积收益和分别独立优化每个决策步骤的即时收益有什么差别?
每当有同行问到这些问题时,我们总是无法给出让人信服的回答。因为我们还没思考清楚一个重要的问题,即:在搜索场景的顺序决策过程中,任意决策点的决策与后续所能得到的结果之间的关联性有多大?
从强化学习的角度讲,也就是后续结果要以多大的比例进行回传,以视为对先前决策的延迟激励。也就是说我们要搞清楚延迟反馈在搜索场景中的作用。
本文将以继续以搜索场景下调节商品排序策略为例,对这个问题展开探讨。
本文余下部分的将组织如下:
第二节对搜索排序问题的建模进行回顾。
第三节将介绍最近的线上数据分析结果。
第四节将对搜索排序问题进行形式化定义。
第五节和第六节分别进行理论分析和实验分析并得出结论。
基于强化学习分层流量调控
今天的淘宝俨然已经成为了一个规模不小的经济体,因此,社会经济学里面讨论的问题,在我们这几乎无不例外的出现了。早期的淘宝多数是通过效率优先的方式去优化商品展示的模式,从而产生了给消费者最初的刻板印象:低价爆款,这在当时是有一定的历史局限性而产生的结果,但肯定不是我们长期希望看到的情形。
因为社会大环境在变化,人们的消费意识也在变化,如果我们不能同步跟上,甚至是超前布局的话,就有可能被竞争对手赶上,错失良机。因此有了我们近几年对品牌的经营,以至于现在再搜索 “连衣裙” 这样的词,也很难看到 9 块 9 包邮的商品,而这个在 3 年之前仍然很常见。
而这里的品牌和客单等因素,是通过一系列的计划经济手段来进行干预的,类似于上文福利经济学第二定理中的禀赋分配,依据的是全局的的观察和思考,很难而且也不可能通过一个局部的封闭系统(例如搜索的排序优化器)来实现。
因此,越来越多的运营和产品同学,鉴于以上的思考,提出了很多干预的分层,这里的分层指的是商品 / 商家类型的划分,可以从不同的维度来划分,比如,按照对平台重要性将天猫商家划分成 A、B、C 和 D 类商家;按照品牌影响力将商品划分为高调性和普通商品;按照价格将商品划分为高端、中等、低端商品等。
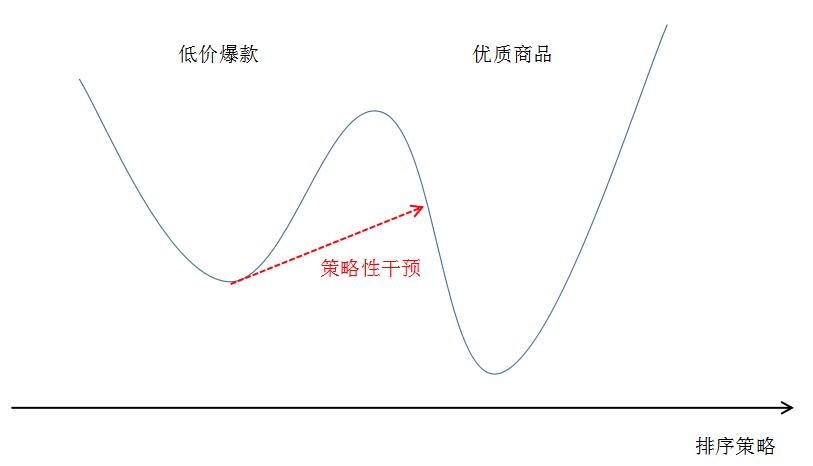
局部最优和全局最优
而早期的算法同学对这些可能也不够重视,一个经典的做法即简单加权,这通常往往会带来效率上的损失,因此结果大多也是不了了之。但当我们认真审视这个问题的时候,我们其实可以预料,损失是必然的,因为一个纯粹的市场竞争会在当前的供需关系下逐步优化,达到一个局部最优,所以一旦这个局部最优点被一个大的扰动打破,其打破的瞬间必然是有效率损失的,但是其之后是有机会达到比之前的稳定点更优的地方。
虚拟淘宝(联合研究项目)
在某些场景下中应用强化学习 (例如围棋游戏中的 AlphaGo), 进行策略探索的成本是非常低的。而在电商场景下, 策略探索的成本会比较昂贵, 一次策略评估可能需要一天并且差的策略往往对应着经济损失, 这是在线应用强化学习遇到的一个普遍问题, 限制了强化学习在真实场景下的应用。
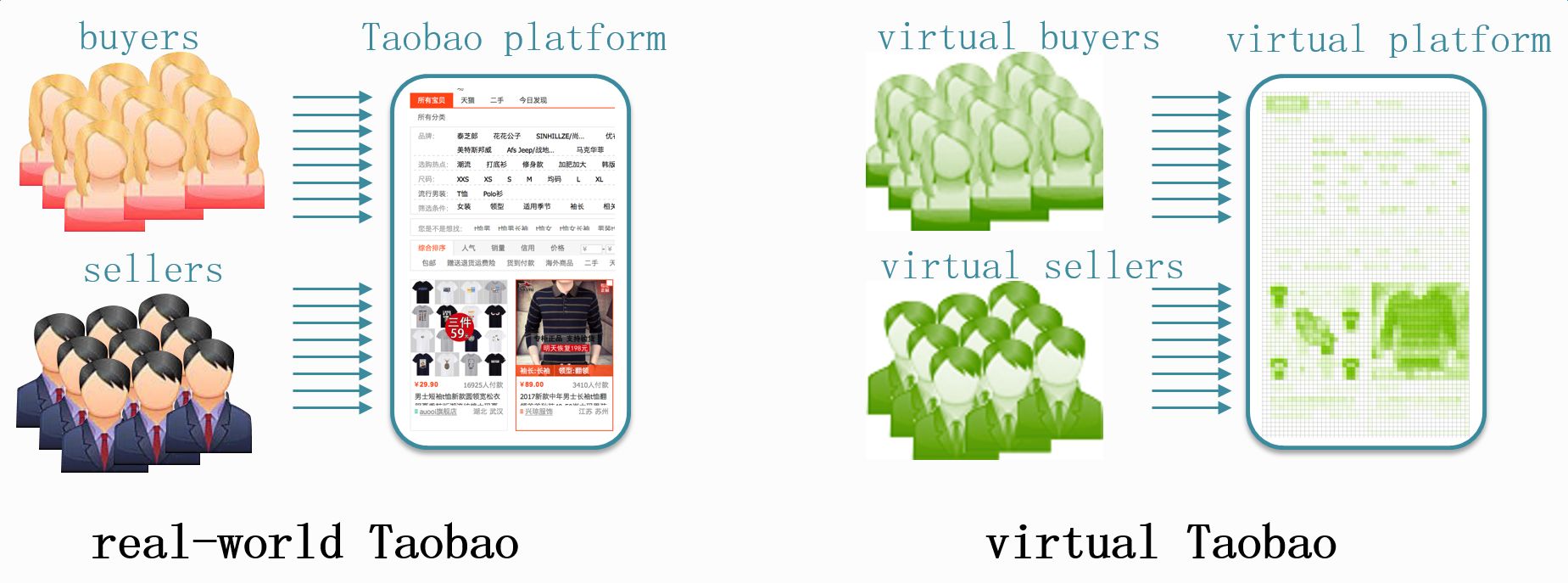
真实淘宝和虚拟淘宝
针对这个问题, 我们和强化学习方面的知名专家, 南京大学机器学习与数据挖掘研究所的俞扬副教授进行了深度合作, 通过逆向建模环境, 尝试构建了一个 “淘宝模拟器”, 在该模拟器上, 策略探索的几乎没有成本, 并且可以快速进行策略评估。而且在这样一个模拟器上, 不仅可以对各种 RL 算法进行离线尝试, 而且还可以进行各种生态模拟实验, 辅助战略性决策。
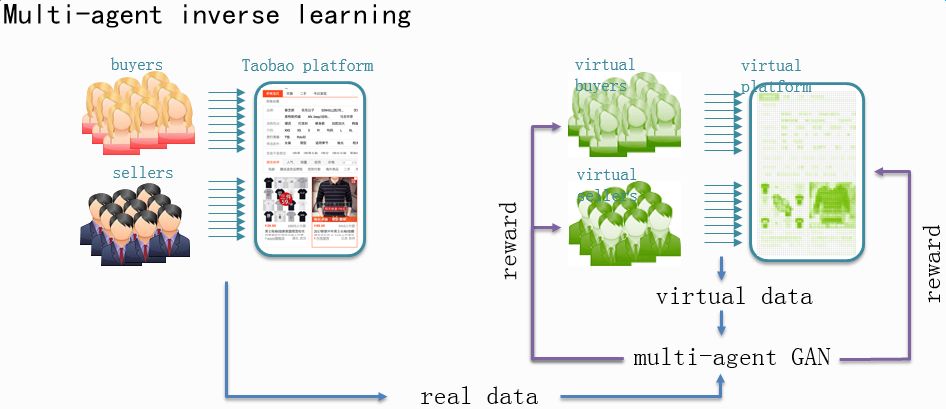
多智能体逆强化学习
参与人员:阿里巴巴 搜索事业部 - AI 技术及应用:胡裕靖、詹宇森、潘春香、笪庆、曾安祥
虚拟淘宝合作方 南京大学:侍竞成、陈士勇、俞扬(副教授)
这四篇文章,结合淘宝的实践经验,用了近三万字深度剖析了强化学习在电商环境下的若干应用与研究!

加入社群
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号: aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名-公司-职位;专业群审核较严,敬请谅解)。
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群 共享AI+开放平台