嘿,朋友,老夫掐指一算你就是“水军” | 论文访谈间 #13

论文作者 | 王雪鹏,刘康,何世柱,赵军(中科院自动化所)
特约记者 | 吴桐(东南大学)
不知多少人会像小编一样网购时需要绕过挡在头几条的层层水军,才能找到相对客观的评论,每当这个时候不免幻想如果机器能帮自己先筛一遍会是多么的方便。
仔细想来,这件事也不是那么难,假如我们可以获取评论者在历史操作中丰富的行为信息,依靠领域专家知识提取出有效特征就可以对评论的价值做出判断。然而没有历史记录的条件下这个问题会变得十分棘手。就像一幕话剧中,张三出场后一直在寻衅滋事,观众轻轻摇头——“一看就不是好东西”。如果这时李四出场了,那么问题来了,李四是好人么?……啊咧,李四还没做过什么呀,你问我我问谁?
这便是垃圾评论检测中的冷启动问题,在新用户刚刚发布了一条评论时,传统方法很难获取足够量的信息,形成有效的特征,如此致使垃圾评论检测系统难以及时检测出新用户的评论。
中科院自动化所的王雪鹏同学、刘康老师、何世柱老师和赵军老师,在 ACL2017 上发表了一篇名为“Handling cold-start problem in review spam detection by jointly embedding texts and behaviors”的文章,针对这个未被前人探索过的问题,提出了一个基于图结构与卷积神经网络的模型,该模型通过对文本与行为信息联合编码来学习表示新用户的新评论。
实验结果显示本文所提出的模型能够有效地在冷启动状态下检测垃圾评论,并具有较好的领域适应性。该模型同样适用于无监督大规模数据学习。
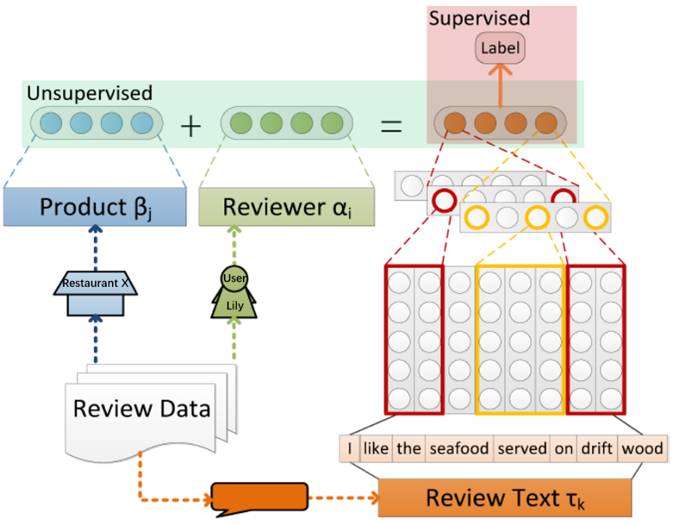
▲ 图1:模型框架图
如图 1 所示,文中提出了基于图结构与卷积神经网络的模型来将文本信息与行为信息联合编码到评论的表示向量中,以在冷启动状态下检测垃圾评论。通过对评论系统的图结构进行建模,模型能够以一种无监督的方式记录现有用户的全局性行为足迹,从而进一步地捕捉到用户行为足迹中的潜在个人特性信息。
这种联合学习评论向量表示的方法能够有效地对用户的文本信息与行为信息之间的关联耦合性进行建模。当一个新用户发表了一条评论时,模型能够使用从大量已有评论中学习到文本信息(词向量)来表示这条评论,同时耦合关联在词向量中的行为信息也随之一起编码到了新评论的向量表示中去。最终,将新评论的表示向量输入到训练好的分类器中进行垃圾评论的检测。
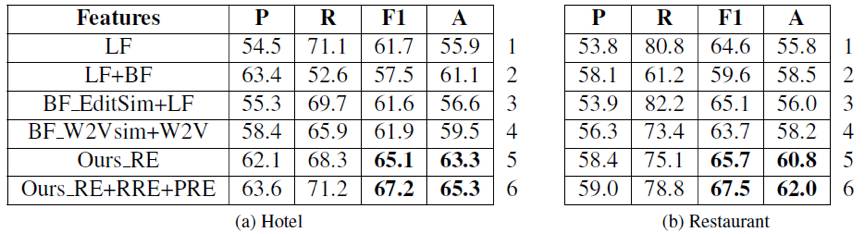
▲ 图2:实验结果
实验部分通过如下几种特征及方法的组合在宾馆和餐厅的评论数据集上进行验证。其中 LF(linguistic features)代表传统评论文本特征,BF(behavioral features)代表传统用户行为特征,BF_EditSim 代表通过编辑距离计算后得到的相似评论的评论者的行为特征,BF_W2Vsim 代表通过计算评论(预训练)词向量平均值表示得到的相似评论的评论者行为特征,在文中另外定义了 RE(review embeddings),RRE(review’s rating embeddings)和 PRE(product’s average rating embeddings)等三种经训练得到的特征向量。
利用 SVM 对以上组合特征分别进行分类测试,文中所提出的模型在两个测试集上均表现不俗(图 2 中,1、2 行展示的是传统方法,3、4 行展示的是直觉方法,5、6 行展示的是本文联合学习方法)。
冷启动问题是垃圾评论检测中的一项迫切而重要的任务,冷启动问题的解决能够及时而有效地减轻垃圾评论者对评论网站的攻击伤害。本文首次探索了冷启动问题,定性与定量地分析验证了传统文本特征与行为特征很难有效地在冷启动状态下检测垃圾评论,提出了一个基于图结构与卷积神经网络的模型,在冷启动状态下检测垃圾评论。
也许真的有一天技术成熟了,我们可以再也不用为满屏的垃圾评论感到苦恼了,想想真的还有点小激动呢。
迎点击「阅读原文」查看论文:
Handling cold-start problem in review spam detection by jointly embedding texts and behaviors
关于中国中文信息学会青工委
中国中文信息学会青年工作委员会是中国中文信息学会的下属学术组织,专门面向全国中文信息处理领域的青年学者和学生开展工作。

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


点击 | 阅读原文 | 查看论文





