让陌生人说出你的兴趣:基于深度学习的推荐模型—PARL

「论文访谈间」是由 PaperWeekly 和中国中文信息学会社会媒体处理专委会(SMP)联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。


在过去十几年,推荐系统一直是数据挖掘领域和各大互联网公司持续关注的一个热点技术。其核心目的在于根据用户的行为挖掘出用户的兴趣并由此对用户提供精准的推荐。
传统的推荐系统主要依赖于协同过滤技术从用户对商品的历史打分行为中学习用户个性化的品味。虽然基于协同过滤的推荐系统取得了不错的推荐效果,但受限于用户行为数据的稀疏性等原因,其在推荐性能上存在比较明显的瓶颈。
近年来,基于评论的推荐系统已经引起了学术界和工业界的广泛关注。其核心思想在于根据用户(商品)的评论构建用户(商品)评论文档(user/item document),并从对应的用户文档和商品文档中挖掘出用户的兴趣(商品的特征)以进一步辅助推荐。
这类同时利用用户打分数据和评论数据来学习用户-商品关系的推荐模型取得了比协同过滤模型更好的效果。其主要原因在于,作为用户评分数据以外另一个重要的用户生成内容,评论数据不仅能缓解用户-商品交互数据的稀疏性问题,并且能为推荐系统的推荐行为提供一定程度上的可解释性。
虽然大部分的基于评论的推荐系统被证明能有效缓解推荐领域中用户-商品交互数据稀疏的问题,它们自身仍然存在一些不足:
1. 评论数据本身面临的稀疏性问题:大多数用户在完成网上购物/评分后,并不会留下相应的评论来表达他们的观点。
2. 用户的评论不能完整反应用户的感受:虽然平台并不对评论的字数作出限制,但大多数用户留下的评论字数较少,无法完整表达出用户的想法。
为解决上述问题,本文提出了一个深度推荐模型——PARL。PARL 尝试从同好用户(like-minded user)所写的辅助评论(auxiliary reviews)中提取语义特征,来提升现有的基于评论的深度推荐模型在分数预测任务上的预测精度。我们认为同好用户所做出的评论能够辅助模型对目标用户进行更好的画像,进而提升推荐系统的最终效果。

从图 1 可以看出,两位 IMDB 的用户“Shawn”和“Jayden”均对“复仇者联盟 3”给出了十分的满分。虽然他们在真实世界里可能互为陌生人,但他们对“复仇者联盟 3”所给出的评价均有利于我们对另一个用户做出更好的画像(例如:根据 Jayden 的评论,我们可以合理推测 Shawn 也会喜欢“蚁人”这部电影)。
模型
模型第一步是为每个用户构建对应的辅助评论文档(auxiliary document)。该辅助评论文档,由此用户的同好用户所写的评论所组成。辅助评论文档的构造主要遵循三个原则:
文档不能被热门商品的评论所主导;
不同的用户有不同的打分习惯;
大多数用户倾向于给高分。
所以在构建文档时,我们将和用户对同一商品有相近打分行为的用户都当作同好用户,并倾向于选择和目标用户打相同分数或者比目标用户打分高的用户所写的评论作为辅助评论。对于用户所有的打分行为,我们都随机挑选一位同好用户所写的辅助评论加进辅助评论文档中。
完成对辅助评论文档的构建后,如图 3 所示,PARL 利用四层网络结构来从辅助文档中提取语义特征:1)卷积层(Convolution layer)。2)抽象层(Abstracting layer)。3)过滤层(Filtering layer)。4)融合层(Fusion)。
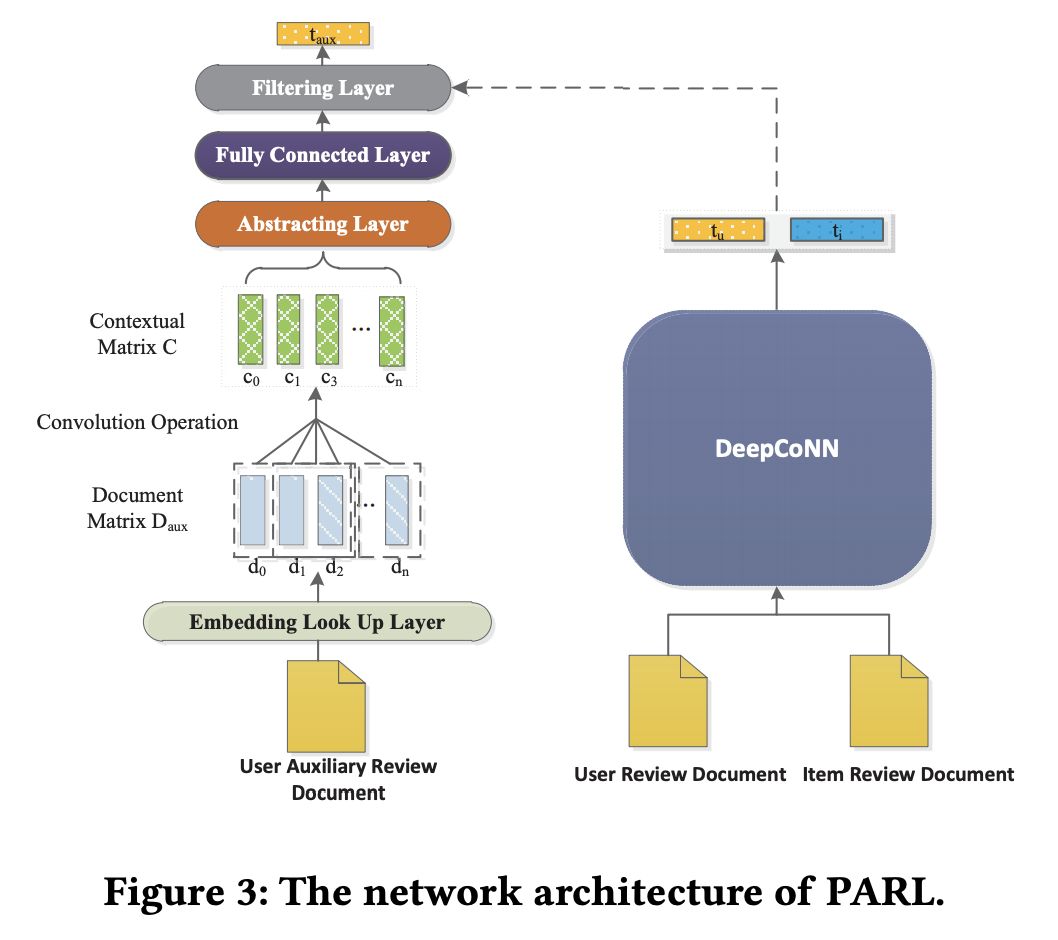
卷积层
给定一篇辅助评论文档,卷积层先通过一个映射矩阵把文档中的单词转换成对应的词向量,从而得到词向量矩阵。得到
后,PARL 利用一层卷积操作来捕捉文档中的短语和词组信息,并且将矩阵 D 转换成带上下文信息的矩阵 C:
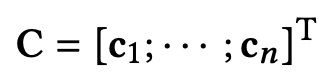
其中 C 里面的每一列向量 c 都建模了短语的上下文信息。
抽象层
由于辅助评论文档里面包含的评论内容并不是目标用户本人所写,所以一个比较合理的假设是:辅助评论文档中只有部分观点可以有效反映目标用户的兴趣。所以在得到矩阵 C 后,我们会再利用一层基于最大池化操作的卷积神经网络(max-pooling based CNN)来进一步抽像辅助评论文档中提取出来的语义特征:
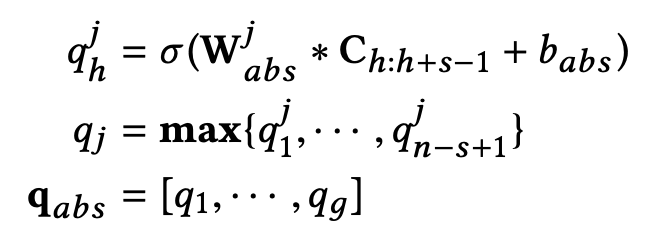
其中,是经过抽象后从辅助评论文档中得到的初级语义隐向量。在得到
后,我们会让它经过一层非线性变化的全连接层,从而得到最终的语义表达向量
:
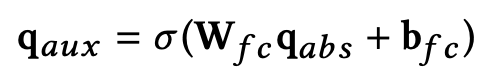
过滤层
一般来说,可以被认为是从辅助评论文档中提取出来的语义特征,并可作为额外的信息用以辅助其他基于评论的推荐系统,以获得更好的分数预测效果。但由于用户对不同的商品会体现出不一样的兴趣点,并最终影响用户对不同商品所打的分数。
为了有针对性地提取对目标用户-商品对有效的语义特征,从而更好地预测目标用户对目标商品的评分。过滤层通过结合高速网络(highway network)和门机制(gated mechanism)来进一步优化所携带的语义信息。
首先,PARL 用一层高速网络来优化所携带的信息流:
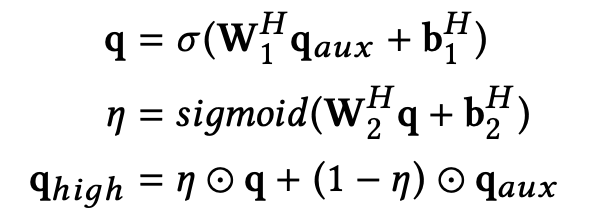
通过高速网络后,为了过滤无效特征,PARL 利用门机制,结合已经得到的用户表达和商品表达来最终选择向量所携带的语义信息:
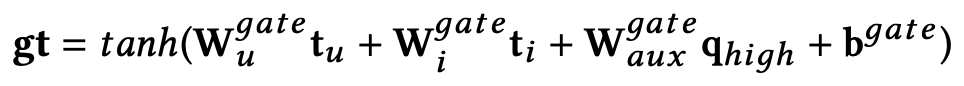
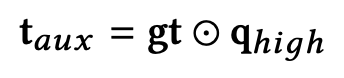
其中,
是基础的基于评论的推荐模型(本文中是 DeepCoNN)分别从用户评论文档(user document)和商品评论文档(item document)中提取出的用户向量和商品向量。而
被认为是最终的从辅助评论文档中提取出来的特征向量,其携带针对目标用户-商品对的语义特征信息。
融合层
在学到后,每一个用户 u 会关联两个向量:从用户评论文档中学出的隐向量
和从用户辅助评论文档中提取出的隐向量
。为了完整地刻画用户,我们利用单层的全连接层把它们合并成一个向量,得到用户的最终表达
如下:
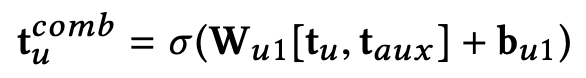
然后 PARL 把和
拼接起来:
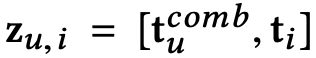
后,把它送进分解机(Factorizaiton Machine)来实现分数预测的功能。
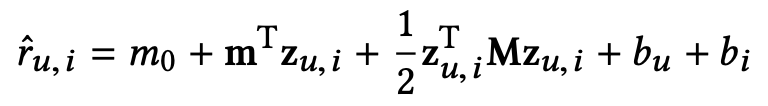
最后,我们基于回归的平方损失函数来优化整个模型:
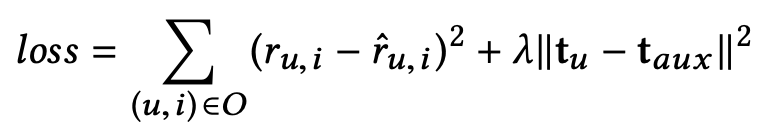
由于和
是分别从两份异构的文档中提取出来的语义特征向量,它们所携带的特征具有不兼容性。为了消融这种不兼容,我们给目标函数设置了第二项,并利用 λ 参数来控制两个向量之间的兼容程度。
实验结果
本文在五个数据集上做了实验来验证模型的有效性。同时为了验证 PARL 是否能有效改善基于评论的推荐系统在评论数据稀疏时对分数的预测精度,本文把用户文档根据长度划分成不同的用户群并分别进行了分数预测的实验。最后,本文通过一个可视化实验来说明 PARL 具有从辅助文档中提取有效语义特征的能力。
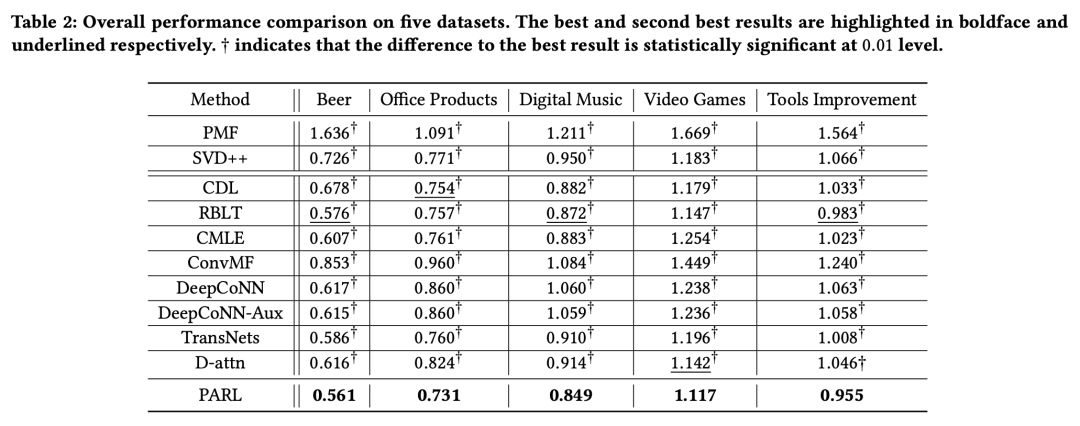
表 2 列出的是各推荐模型在不同数据集的分数预测任务上的总体表现。可以看出:本文所提出的 PARL 模型的表现更好。同时 DeepCoNN-Aux 模型是在把用户辅助文档拼接在用户文档后尝试通过 DeepCoNN 模型来提取额外的语义特征。
但根据 DeepCoNN-Aux 和 DeepCoNN 模型的效果对比来看,在分数预测的精度上该操作并没有取得明显的提升。这一对比也说明了利用额外网络结构来单独提取辅助文档中包含的语义特征的必要性。
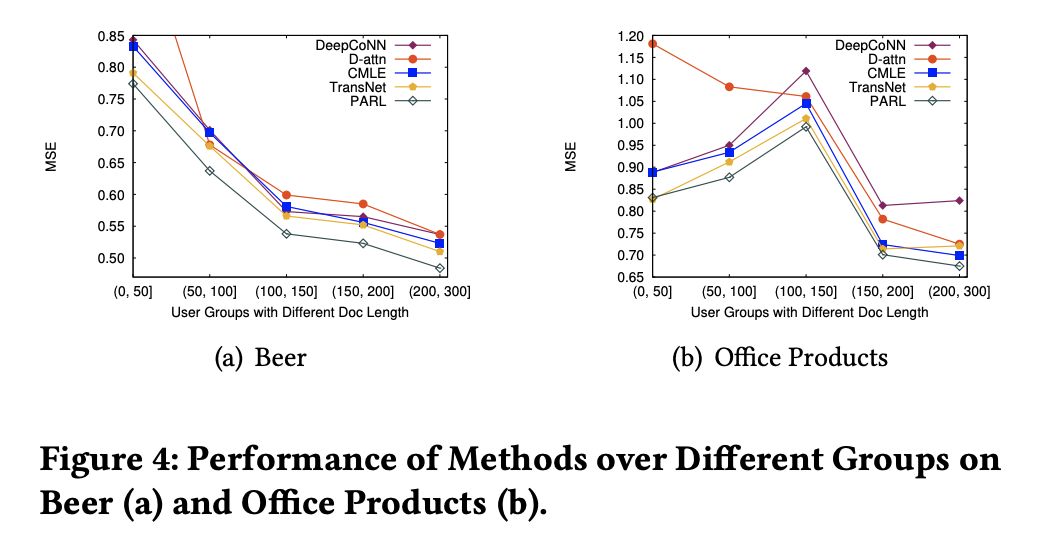
另外,为了验证 PARL 是否能通过利用辅助文档改善基于评论的推荐系统在评论数据稀疏时的表现。作者根据用户评论文档的长度把用户划分为 5 组。我们可以发现在 Beer 和 Office Products 数据集的大多数分组上,PARL 都能达到最低的预测误差。因此说明 PARL 可以通过利用辅助评论文档更好地提高分数预测的精确度。另外随着文档长度越长,PARL 带来的效果提升也更明显。
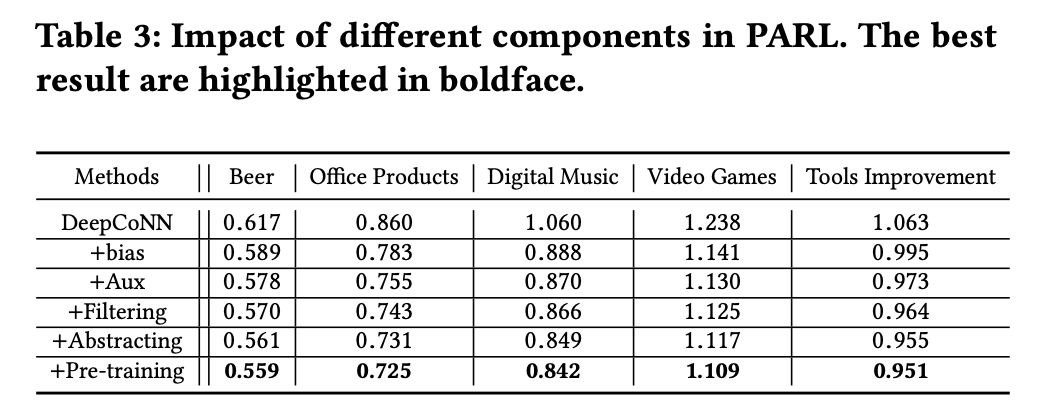
表 3 是本文对 PARL 模型做的消融实验的结果,可以观察到:每个组件层都对提升分数预测的精度起到了正面的影响。
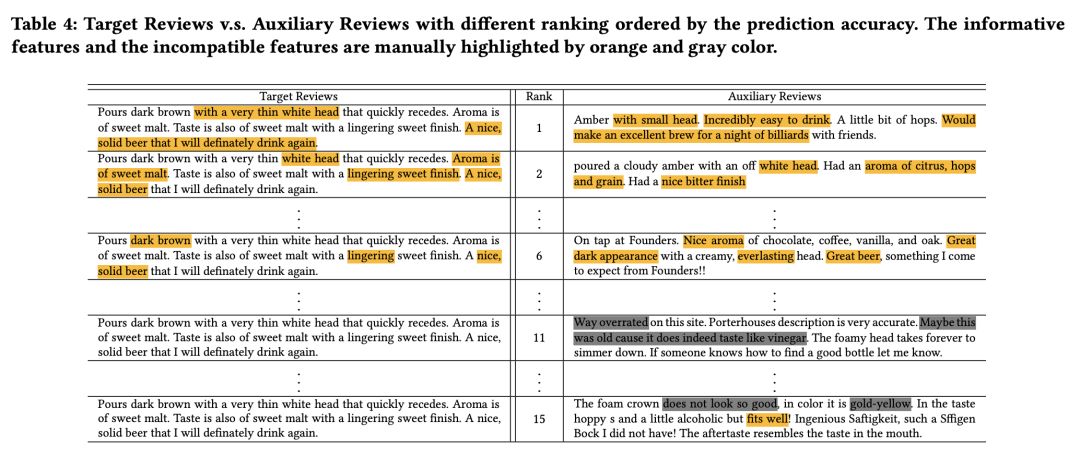
表 4 展示了辅助文档中和目标评论相关联的语义特征之间的可视化。可以看出,当辅助文档与当前目标的评论在语义上关联度越大,他对分数预测的精确度就会越好(排名就会越高)。也在一定程度上展示了 PARL 模型具有有效地提取用户-商品对相关的语义特征的能力。
总结
本文提出一个基于深度学习技术的推荐模型 PARL。PARL 可以通过从同好用户所写的辅助评论中提取有效的语义特征来优化基于评论的深度推荐模型在分数预测任务上的性能。PARL 也是第一个尝试解决文本稀疏性的推荐工作。
未来,我们尝试利用注意力机制来更有针对性地挑选辅助评论文档,并进一步提升推荐系统的性能和可解释性。
关于作者

吴黎兵,武汉大学计算机学院教授。主要研究方向为大数据、无线网络、网络管理、分布式计算等。近年来主持国家自然科学基金、湖北省创新群体、湖北省科技支撑计划、湖北省自然科学基金重点项目和面上项目、武汉市科技攻关、国家科技部支撑计划子课题、中国博士后科学基金特别资助、武汉市软件发展基金等项目的研究工作,曾参加国家863计划引导项目、可信软件重大研究计划等研究工作。目前已发表160余篇学术论文,其中110多篇被SCI/EI收录,曾获第十二届中国计算机网络与通信学术会议优秀论文奖。获得ICoC2016中国互联网学术会议Best Paper奖。担任杂志IEEE TVT,IEEE Transactions on Cloud Computing,IEEE Transactions on SMC等国际期刊审稿人。

全聪,武汉大学计算机学院博士研究生。主要研究方向为推荐系统,自然语言处理等。

李晨亮,武汉大学国家网络安全学院副教授,硕导,武汉大学珞珈青年学者。研究兴趣包括信息检索、自然语言处理、机器学习和社交媒体分析,在SIGIR、TOIS、TKDE、ACL、AAAI、CIKM相关领域权威会议及期刊发表论文30余篇。担任中国中文信息学会青年工作委员会委员、社交媒体专委会委员、信息检索专委会委员。长期担任相关领域国际权威学术期刊审稿人和重要学术会议 程序委员会委员(TPC)。担任信息检索国际权威学术期刊JASIST的编委。获SIGIR2016 年Best Student Paper Award Honorable Mention;SIGIR2017 年Outstanding Reviewer Award。

姬东鸿,武汉大学国家网络安全学院教授,博士生导师,武汉大学珞珈特聘教授。先后在武汉大学和牛津大学获计算机和语言学博士学位。主要研究方向为自然语言处理、深度学习、大数据平台(智慧医疗、智慧建筑、智慧教育等)和对话机器人等。近年来主持省部级以上项目近20项,在AAAI,EMNLP,COLING等国际顶级会议与期刊发表论文40多篇。
主办单位



点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码



