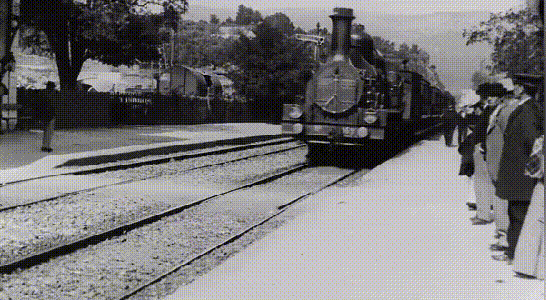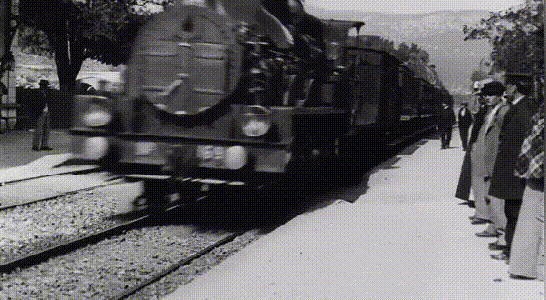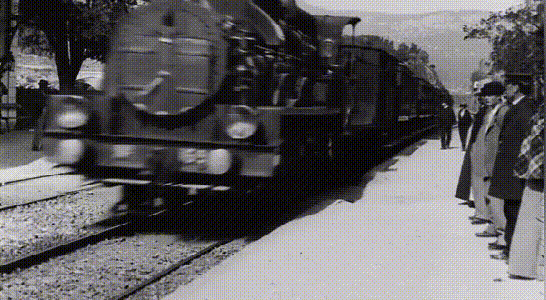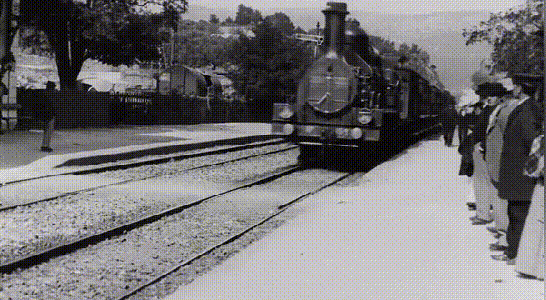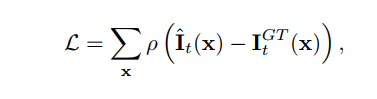点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
![]()
《火车进站》是人类历史上的第一部电影,由路易·卢米埃和奥古斯特·卢米埃于 1895 年拍摄于法国一沿海城市,整部电影只有45秒。
然而最近,在YouTube上出现了一个不一样的“火车进站”视频,不同在这是一部经过神经网络增强的“百年老片”,将原有模糊的视频直接提升到4k高清。
在125年前,《火车进站》这部电影采用了 35mm格式胶片制作,由于当时的放映机由手摇进行驱动,其原始帧率大概在16帧到24帧之间。
![]()
由于当时的胶片技术尚未成熟,我们可以看到画面景物都是比较模糊的,火车在驶来的同时还带有明显的拖影。
但经过了神经网络的画面分辨率增强和插帧之后,这部老电影获得了4K ~ 60fps的画质。如果不是电影黑白的画面和胶片电影独有的画面抖动,画面流畅度和清晰度几乎可以与现在的智能手机相媲美。
这部影片的修复工作是由一位名叫 Denis Shiryaev的男子完成的,其所使用的是Topaz实验室的Gigapixel AI以及DAIN image 图像编辑应用程序。在修复过程中,他不仅将镜头提高到4K,还将帧率提高到每秒60帧。
《火车进站》这部短片原始原片质量非常模糊,分辨率非常低。Shiryaev使用Gigapixel AI渲染后,自己为这部电影加上声音后,观影体验竟然完全符合现在的标准。
根据官网介绍,Gigapixel AI软件内嵌专有的插值算法,在分析图像的同时能够识别图像的细节和结构,即使将图像放大 600%,也能保证图像的清晰。值得一提的是,电影中的部分图像是通过GAN生成的。
另一方面, DAIN (Depth-Aware Video Frame Interpolation)可对电影中的帧进行预测,并将其插入现有视频之中。换句话说, DAIN分析并映射视频剪辑,然后在现有图像之间插入生成的填充图像。
为了在这段1896年的视频中达到与4K同样的效果,Shiryaev为电影填充了足够多图像,从而将“图片放映”提高到了每秒60帧。因此,DAIN每秒会自动生成36个图像然后添加到电影中。
除此之外,基于同样的AI技术,神经网络可以将一堆彩色照片转换为黑白,然后再训练它重建彩色原稿,训练后的模型就可以把黑白电影,转换成彩色。如下视频展示的那样。
将百年老片修成4K大片,深度学习技术出了不少力,更为具体的是视频插帧技术在深度学习里的体现。
当然,深度感知视频帧内插(Depth-Aware Video Frame Interpolation)也不是最近才出现的技术。早在2019年,此项技术的相关论文就被收录到CVPR 2019,相关算法也已经开源在了Github上。
论文下载地址:
https://arxiv.org/pdf/1904.00830.pdf
Github地址:
https://github.com/baowenbo/DAIN
这篇文章的第一作者Bao Wenbo,是上海交通大学电子信息与电气工程学院的博士生。具体工作是基于其在2018年发表的论文MEMC-Net做的改进。具体效果类似于英伟达开源的Super SloMo,即能够从普通的视频“脑补”出高帧率的画面,从30fps插帧到240fps,即使放慢8倍也不会感到卡顿。
而这个新的插帧算法DAIN比英伟达的算法效果更清晰、帧率更高,可以把30fps的进一步插帧到480fps。
具体到算法层面,研究人员提出了一种通过探索深度信息来检测遮挡的方法。
一个深度感知光流投影层来合成中间流,中间流对较远的对象进行采样。此外,学习分层功能以从相邻像素收集上下文信息。
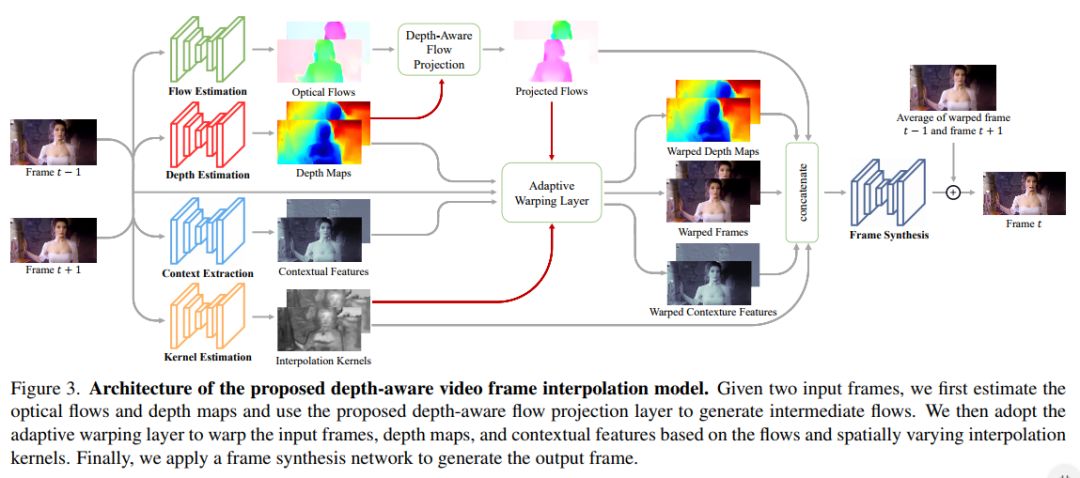
更为具体的如上图所示,整个算法分为光流、深度、上下文特征、插值kernel、框架合成这几个部分。
在光流估计模块,采用PWC-NET光流估计模型,由于在没有监督的情况下学习光流是非常困难的,所以作者从预先训练好的PWC-Net中初始化光流估计网络。
在深度部分,不同于过去的网络模型采用的是计算平均值的方式,为了处理处理遮挡区域的问题,此作者提出了一种使用深度辅助来计算tt时刻的光流融合结果。融合的权重使用的是深度值的倒数,简单的来说就是深度值越大的像素(距离越远的像素),在光流合成的时候所占的权重越小。
上下文特征部分,作者提出,在CtxSynNet论文中已经证明上下文信息(contextual feature)的加入对视频插值有一定帮助。所以在这篇论文中,作者基于Residual block自己设计了一个提取上下文特征的网络,并从头开始训练。
插值kernel自适应warping layer部分,主要思想是通过光流找到像素的新位置后,将其新位置周围4x4范围内与一个特殊的kernel相乘后作为该点的像素值。这个kernel由两部分相乘得出,一部分是我们图像缩放时常用的双线性插值,其中每个位置的权重只与坐标距离有关,另一部分也是一个内插值kernel,是通过网络学习得出的。
框架合成。为了生成最终的输出帧,作者构建了一个帧合成网络,该网络由3个个残差块组成。并将扭曲的输入warped深度图、warped上下文特征、warped和插值核连接起来作为帧合成网络的输入。此外,还对两个warped帧进行线性混合,并强制网络预测地面真实帧和混合帧之间的残差。
损失函数是真实帧和混合帧之间的残差,这种函数名为Charbonnier Loss,是一种L1 loss的变种,只不过加了一个正则项。
所采用的训练数据集是Vimeo90K,其有51312个三元组用于训练,其中每个三元组包含3个连续的视频帧,分辨率为256×448像素。具体在训练过程,作者用网络来预测每个三元组的中间帧(即,t=0.5)。在测试时,模型能生成任意中间帧。另外,还通过水平和垂直翻转以及颠倒三元组的时间顺序来增加训练数据。
在具体的训练策略中,作者使用AdaMax优化网络,分别设置 β1 and β2为0.9 和 0.999,并将核估计、上下文提取和帧合成网络的初始学习率设置为1e−4。由于流估计和深度估计网络都是从预先训练的模型初始化而来的,因此分别使用较小的学习率1e−6和1e−7。另外还对整个模型进行30个epoch的联合训练,然后将每个网络的学习率降低0.2倍,并针对另外10个epoch对整个模型进行微调。
值得一提的是,作者在NVIDIA Titan X(Pascal)GPU卡上训练模型,大约用了5天达到收敛状态。
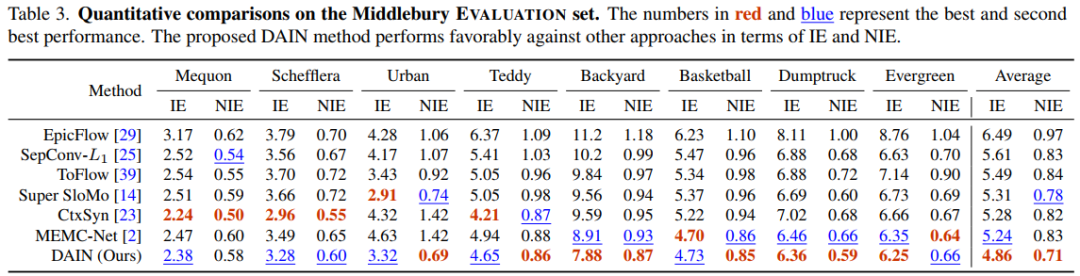
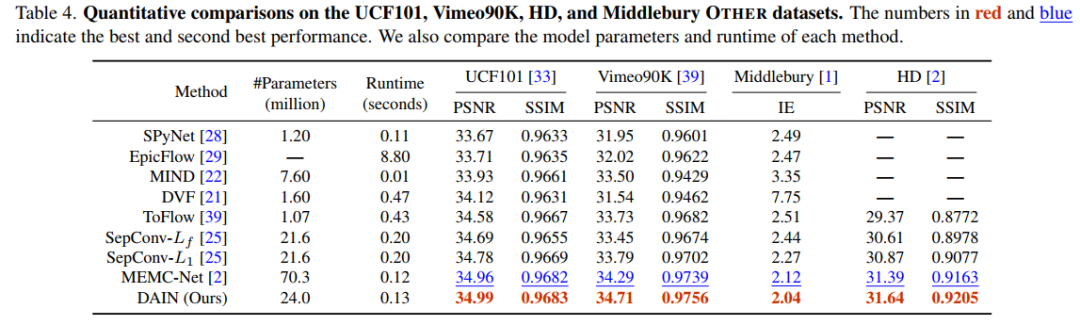
关于实验结果,放两张在不同数据集上与近年论文的优劣,这里不做过多分析。
总的来说,作者提出了一种depth-aware视频插帧方案,并尝试显式的解决遮挡区域的问题。借用PWC光流coarse-to-fine的思路,尝试解决large motions的问题。使用学习的分层特征和深度作为上下文信息,更好的合成中间帧。
那么,这种类型的深度学习技术在具体的电影修复中能发挥什么样的作用呢?
去年是建国70周年,除了气势恢宏的阅兵给人们留下了深刻的印象之外,10月下旬上映的《开国大典》也着实让人感动了一把,这部电影展现了三次战役胜利到开国大典的整个历史过程。
这部电影在1989年9月21日初映,全片分为18卷,共164分钟。由于当时的拍摄条件,重新上映必须修复画质。
在修复过程中,制作方最大化地利用DRS修复系统的功能,把自动化修复与人工修复结合。通过AI算法,老胶片存在的收缩、卷曲等问题都可以得到解决,但是胶片的撕裂、划痕等都需要专业的修复师一帧一帧地进行修补。
除了《开国大典》,9月份上映的《决胜时刻》也是采用了AI技术。据电影制片方爆料,这段材料来自于俄罗斯的一段彩色纪录片,但由于年代久远,画质模糊,色彩失真。而经过了复杂的 4K 修复工作之后,最终呈现出这般极致的画面体验。
另外,《厉害了,我的国》就是中影电影数字制作基地数字修复中心主任肖搏及其团队利用AI修复进行的一次尝试。
为了更顺利地进行修复工作,肖搏团队开发了“中影·神思”人工智能图像处理系统,靠计算机大数据深度学习算法,在四个月内修复增强了30万帧图像。利用“中影·神思”,修复一部电影的时间可以缩短四分之三,成本减少了一半。
而爱奇艺开发ZoomAI也是一款基于深度学习的视频修复技术,此技术内部由多个模块组成,每个模块负责一种或者几种画质增强的方向,比如超分辨率,去除噪声,锐化,色彩增强等等。每个模块都是由一个或者多个深度学习模型组成。
综上所述,利用卷积神经网络和最先进的图像识别技术,让经典老电影重现光彩已经不是遥不可及的事情。与其他方法相比,通过基于深度学习的技术来修复电影可以节省时间和精力。经典电影的修复和数字化也能使人们能够更方便地获得更多文化产品。
https://towardsdatascience.com/neural-networks-help-upscale-conversion-of-famous-1896-video-to-4k-quality-d2c3617310fe
https://cloud.tencent.com/developer/article/1507729
https://baijiahao.baidu.com/s?id=1657837274349020022&wfr=spider&for=pc
https://blog.csdn.net/olivertai/article/details/102776724
https://www.lizenghai.com/archives/46735.html
重磅!CVer-学术微信交流群已成立
扫码添加CVer助手,可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!