【AAAI2022】上下文感知的词语替换与文本溯源

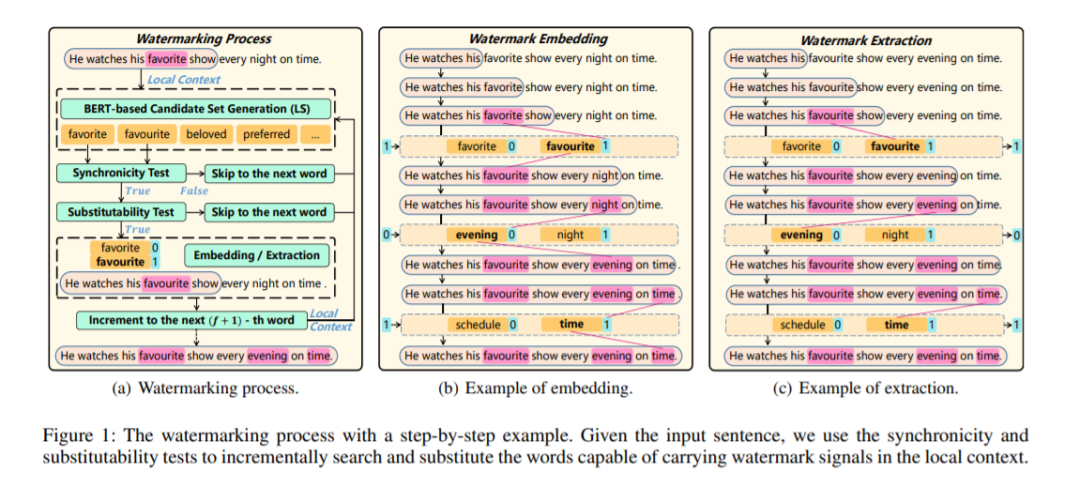
由人类或语言模型创建的文本内容经常被对手窃取或滥用。追溯文本来源可以帮助声明文本内容的所有权,或识别发布机器生成的假新闻等误导性内容的恶意用户。为了实现这一目标,人们进行了一些尝试,主要是基于水印技术。具体来说,传统的文本水印方法通过稍微改变文本格式(如行间距和字体)来嵌入水印,然而,这对于像OCR这样的跨媒体传输来说是脆弱的。考虑到这一点,自然语言水印方法通过使用手工制作的词汇资源(例如WordNet)中的同义词替换原始句子中的单词来表示水印,但它们没有考虑替换对整个句子意义的影响。最近,提出了一种基于Transformer的网络,通过修改影响句子逻辑和语义连贯的非突兀词(如虚词)来嵌入水印。此外,一个训练有素的网络在其他不同类型的文本内容上也会失败。针对上述局限性,我们提出了一种基于上下文感知词汇替换(LS)的自然语言水印方案。具体来说,我们采用BERT方法,通过推断候选词与原句之间的语义相关度来提出LS候选词。在此基础上,进一步设计了一种同步性和可替换性的选择策略,以测试一个词是否完全适合携带水印信号。大量实验表明,无论在客观指标还是主观指标下,我们的水印方案都能很好地保持原句子的语义完整性,并且比现有的水印方法具有更好的可迁移性。此外,所提出的LS方法在斯坦福字词替换基准上的表现优于最先进的方法。
。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TTPS” 就可以获取《【AAAI2022】上下文感知的词语替换与文本溯源》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月20日
Arxiv
16+阅读 · 2018年1月31日



相关VIP内容
相关资讯