【NAACL2021-Google】通过词汇替换实现对多语言机器翻译的持续学习

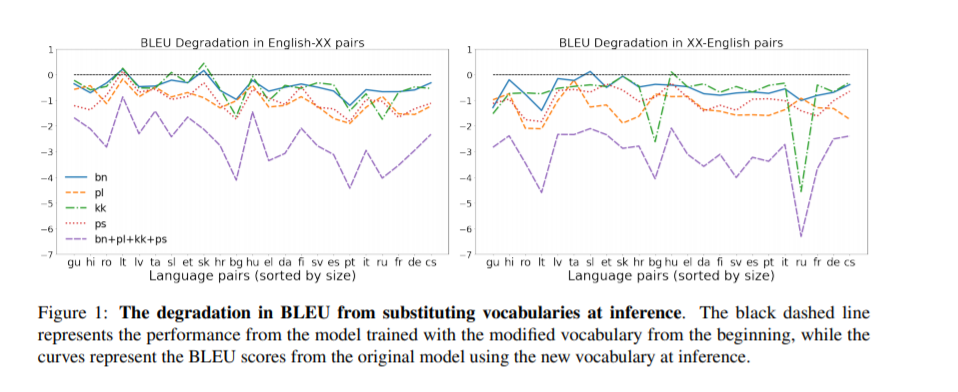
我们提出了一个简单的词汇适应方案来扩展多语言机器翻译模型的语言能力,为多语言机器翻译的高效持续学习铺平了道路。该方法适用于大规模的数据集,适用于具有不可见脚本的远程语言,仅对原语言对的翻译性能有较小的降低,即使在仅对新语言拥有单语数据的情况下,也能提供具有很好的性能。
https://www.zhuanzhi.ai/paper/e0b15338f98c37775bd0113ceaa1d9dd
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CLMT” 就可以获取《【NAACL2021-Google】通过词汇替换实现对多语言机器翻译的持续学习》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2021年6月21日
Arxiv
10+阅读 · 2019年9月15日
Arxiv
4+阅读 · 2018年3月30日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年6月21日
Arxiv
10+阅读 · 2019年9月15日
Arxiv
4+阅读 · 2018年3月30日