【TheWebConf 2022】基于图神经网络的细粒度语义挖掘方法研究

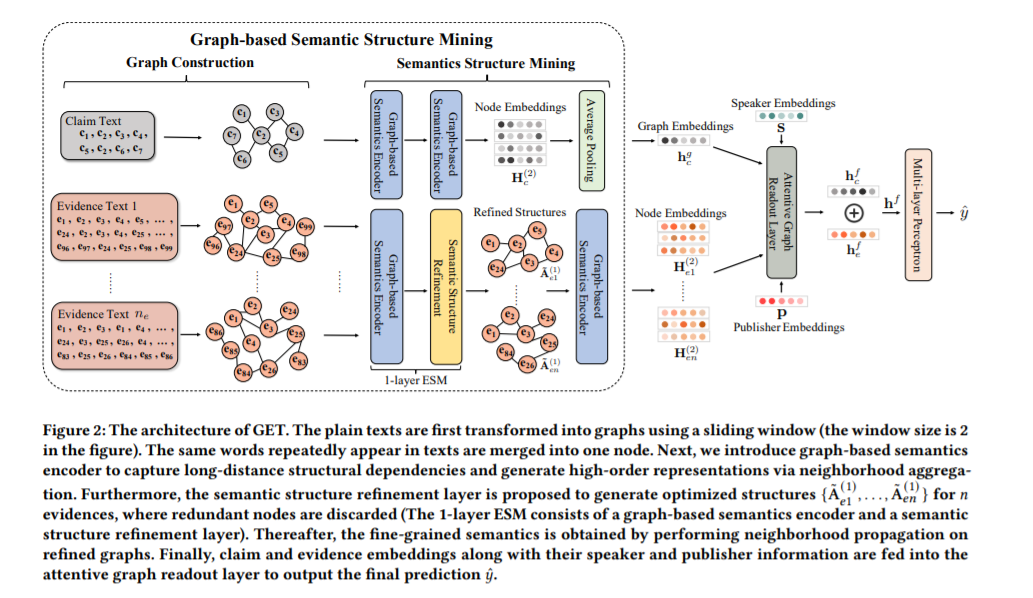
假新闻的流行和危害性一直是互联网上的一个关键问题,这反过来刺激了自动假新闻检测的发展。在本文中,我们关注的是循证假新闻检测,其中几个证据被用来调研新闻的真实性(即一个声明)。以往的方法首先采用顺序模型嵌入语义信息,然后根据不同的注意力机制捕获索赔-证据交互。尽管这些措施行之有效,但它们仍存在两个主要弱点。首先,由于序列模型固有的缺陷,不能将分散在证据中的相关信息整合起来进行准确性检验。其次,他们忽视了证据中包含的许多多余的信息,这些信息可能是无用的,甚至是有害的。为了解决这些问题,我们提出了一个统一的基于图的语义结构挖掘框架,简称GET。具体来说,不同于现有的将索赔和证据视为序列的工作,我们将其建模为图结构数据,并通过邻域传播捕获分散的相关片段之间的长距离语义依赖关系。在获取上下文语义信息后,我们的模型通过图结构学习来减少信息冗余。最后,细粒度的语义表示被输入到下游的索赔-证据交互模块中进行预测。综合实验已经证明了GET技术相对于SOTA技术的优越性。
https://www.zhuanzhi.ai/paper/34ca1b417712f223646fcd7ac5788cc5
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“EBFD” 就可以获取《【TheWebConf 2022】基于图神经网络的细粒度语义挖掘方法研究》专知下载链接



登录查看更多
相关内容
Arxiv
20+阅读 · 2021年5月27日




相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2021年5月27日