【速览】ECCV 2022 | 针对二值神经网络的循环双线性优化
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
ECCV 2022:针对二值神经网络的循环双线性优化
*通讯作者:Baochang Zhang
◆ ◆ ◆ ◆
二值神经网络(BNN)在现实世界的嵌入式设备中显示出巨大的前景。作为实现高性能的BNN的关键步骤之一,缩放因子(scale factor)的计算在减少与全精度对应的性能差距方面起着至关重要的作用。然而,现有的BNN忽略了实值权重和比例因子之间的本质的双线性关系,导致了由于训练过程不足而导致的次优模型。为了解决这个问题,我们提出了一种循环双线性优化(RBONN),通过在反向传播过程中关联内在双线性变量来改进BNN的学习过程。我们的工作是首次尝试从双线性角度来建模BNN的优化问题。具体而言,我们提出了一种循环优化和密度-ReLU函数(DReLU)来时序回溯稀疏的实值权重,这些权重将经过充分训练,并基于一种可控的学习过程达到其性能极限。我们获得了鲁棒的RBONN,它在各种模型和数据集上表现出行业领先的性能。特别是在目标检测任务上,RBONN具有良好的泛化性能。
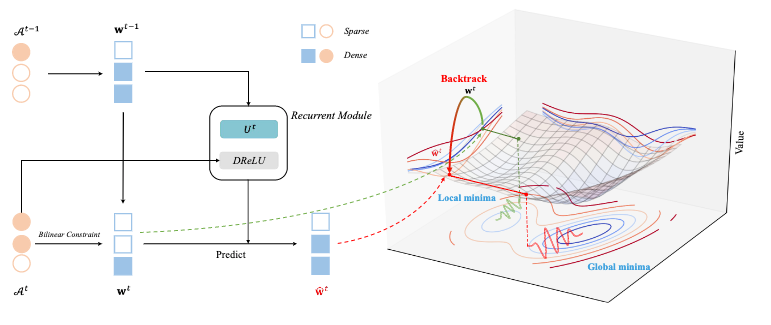
图 1 RBONN的框架。传统的基于梯度的算法假设双线性模型中的隐藏变量是独立的,由于忽略了与缩放因子矩阵A之间的关系,导致w的训练不足,如损失面(右部分)所示。我们的RBONN可以帮助w摆脱局部极小值(绿色虚线),并获得更好的解(红色虚线)。
以前的BNN [1, 2]学习方法通过近似实值权重滤波器
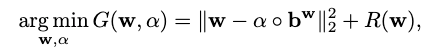
或者
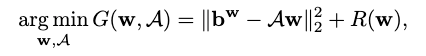
其中
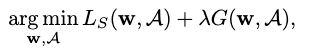
其中
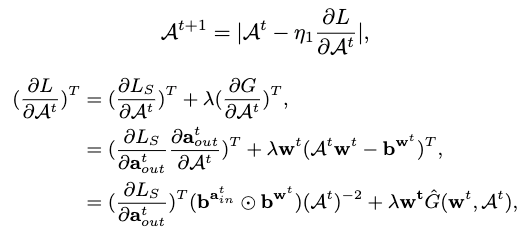
其中,
我们从一个新的角度解决了等式(1)中的问题,即
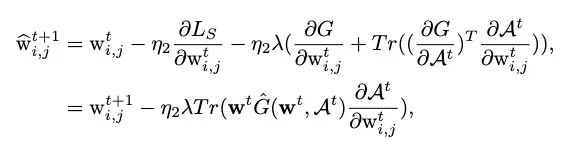
其基于

然后得到
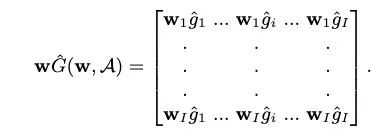
结合上面两个公式可以得到
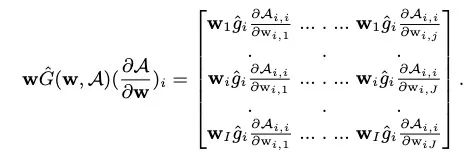
之后,更新公式中的迹项的第
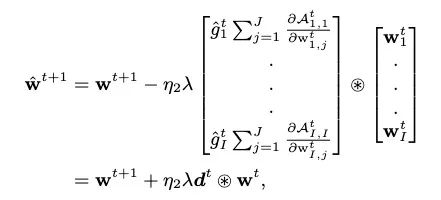
其中
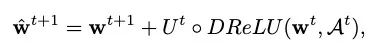
并且
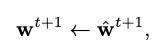
其中,我们引入了一个隐藏层,该隐藏层具有按通道可学习的权重
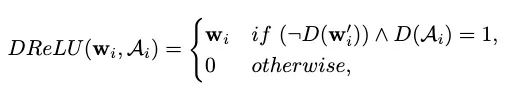
其中
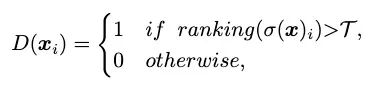
其中
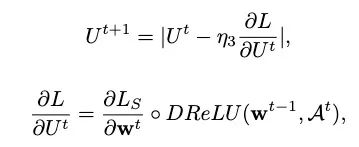
其中
我们在图像分类以及目标检测任务上验证了算法的性能。首先,我们在ImageNet数据集上调整并寻得了最优的超参数设定。
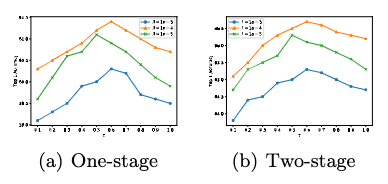
图 2 超参数λ和τ对使用二值ResNet-18的单阶段和两训练的影响
如上图所示,当
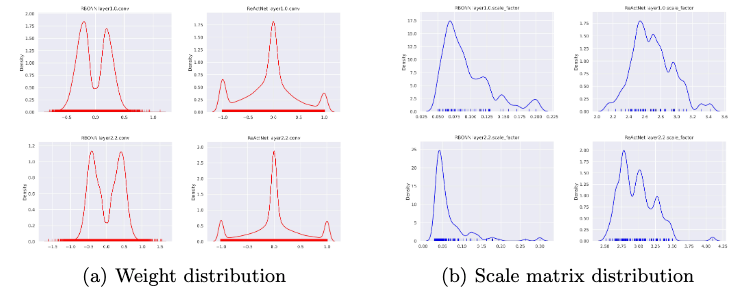
图 3 经由两阶段训练的二值ResNet-18上,RBONN和ReActNet的权重(红色)和比例矩阵(蓝色)分布
我们首先分析训练ReActNet和RBONN的权重分布,以比较分析
在图像分类任务上,我们首先在单阶段训练上验证了RBONN的性能。
表 1 与单阶段训练二值ResNet-18网络在的ImageNet上的SOTA的性能比较
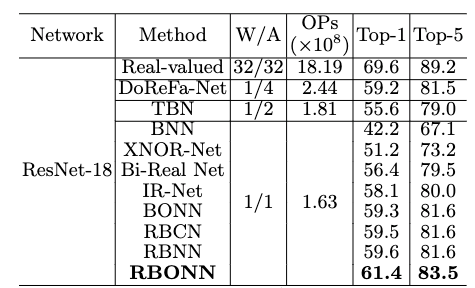
如上表所示,在与其他SOTA方法的比较中,RBONN在Top-1和Top-5精度方面优于所有评估的二值模型。使用ResNet-18模型下,RBONN的op-1和Top-5精度分别达到61.4%和83.4%,比RBNN [5]提高了1.8%和1.9%。
我们进一步比较了二阶段训练的性能,如下表所示:
表 2 与两阶段训练二值ResNet-18网络在的ImageNet上的SOTA的性能比较
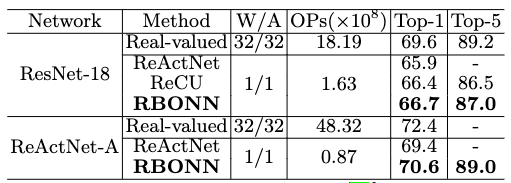
相比于此前的ReActNet[4]与ReCU[6],RBONN分别在ResNet-18的骨架网络上提高了0.8%与0.3%的Top-1精度。在ReActNet-A网络上,提高了1.2%的Top-1精度,实现了一个新的SOTA性能。
在目标检测任务上,我们进一步测试了RBONN的性能。
表 3 RBONN与其他方法在在PASCAL VOC上的性能对比
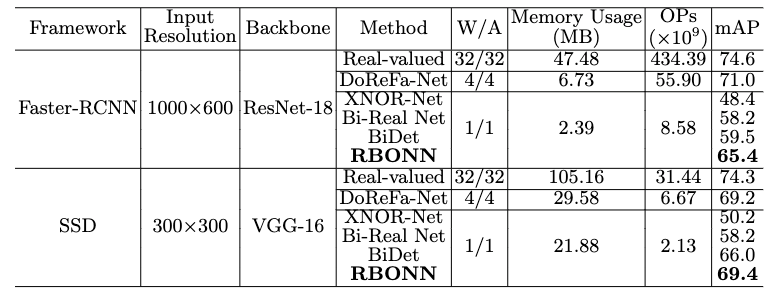
首先,在PASCAL VOC数据集上,RBONN超越了存在的SOTA方法的性能。我们将提出的RBNN与现有的最先进的BNN进行了比较,如BiDet [7]。与其他二值方法相比,我们的RBONN比其他方法有显著改进。在相同的内存利用率和FLOPs情况下,我们的RBONN比BiDet的性能在Faster-RCNN和SSD检测框架上分别高出5.9%与3.4%,这在目标检测任务中是相当显著的。
表 4 RBONN与其他方法在在COCO上的性能对比
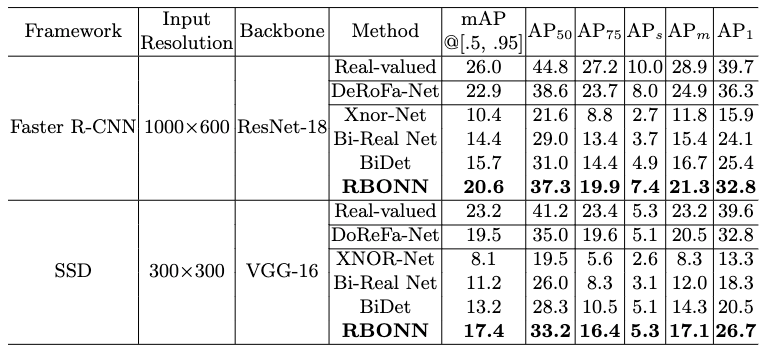
在PASCAL VOC数据集上,RBONN超越了存在的SOTA方法的性能。与BiDet法相比,我们的RBONN比在Faster-RCNN和SSD检测框架上在mAP指标分别高出4.9%与4.1%,这在目标检测任务中是相当显著的。
[1] Gu, J., Li, C., Zhang, B., Han, J., Cao, X., Liu, J., Doermann, D.: Projection convolutional neural networks for 1-bit cnns via discrete back propagation. In: Proc. of AAAI. pp. 8344–8351 (2019)
[2] Zhao, J., Xu, S., Zhang, B., Gu, J., Doermann, D., Guo, G.: Towards compact 1- bit cnns via bayesian learning. International Journal of Computer Vision 130(2), 201–225 (2022)
[3] Petersen, K., Pedersen, M., et al.: The matrix cookbook. Technical University of Denmark 15 (2008)
[4] Liu, Z., Shen, Z., Savvides, M., Cheng, K.T.: Reactnet: Towards precise binary neural network with generalized activation functions. In: Proc. of ECCV. pp. 143– 159 (2020)
[5] Lin, M., Ji, R., Xu, Z., Zhang, B., Wang, Y., Wu, Y., Huang, F., Lin, C.W.: Rotated binary neural network. In: Proc. of NeurIPS. pp. 1–9 (2020)
[6] Xu, Z., Lin, M., Liu, J., Chen, J., Shao, L., Gao, Y., Tian, Y., Ji, R.: Recu: Reviving the dead weights in binary neural networks. In: Proc. of ICCV. pp. 5198–5208 (2021)
[7] Wang, Z., Wu, Z., Lu, J., Zhou, J.: Bidet: An efficient binarized object detector. In: Proc. of CVPR. pp. 2049–2058 (2020)





