【速览】IJCV 2021| 基于贝叶斯学习的紧凑1比特卷积神经网络(BONN)
学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
基于贝叶斯学习的紧凑1比特卷积神经网络(BONN)
*通讯作者:张宝昌(bczhang@buaa.edu.cn)
◆ ◆ ◆ ◆
与全精度的同类网络相比,1比特卷积神经网络(CNN)的性能通常会显著下降。在本文中,我们提出了一种基于贝叶斯学习的1比特CNN(BONN),可以显著提高1比特CNN的性能。BONN将全精度卷积核、特征和过滤器的先验分布合并到贝叶斯框架中,以端到端的方式构造1比特CNN。我们的方法可用于在卷积核分布,特征监督和滤波器剪枝中,从而同时优化网络,大大提高了1比特CNN的紧凑性和性能。我们进一步介绍了一种新的基于贝叶斯学习的1比特CNN剪枝方法,该方法显著提高了模型效率,使得我们的方法能够在各种实际场景中使用。在ImageNet、CIFAR和LFW数据集上进行的大量实验表明,与各种最先进的1比特CNN模型相比,BONN在分类性能方面达到了最佳水平。除此之外,BONN在目标检测任务上实现了很强的泛化性能。
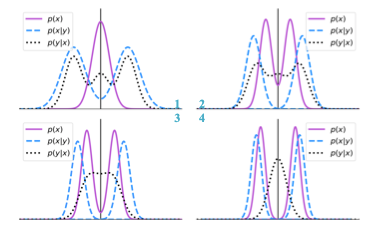
图 1 基于贝叶斯学习的权重分布的演变
贝叶斯学习的引入有两种优点:
1、通过设计每一层权重的分布,得到更稳定的双峰分布,在sign函数的阈值0附近的权重更少,从而在训练过程中有更少的符号反转。
2、通过对每层的滤波器的分布分析,在学习过程中对具有相似分布的组进行聚类,基于最大后验概率对每个滤波器到聚类中心的距离进行最小化,从而得到具有相同分布的滤波器,进行剪枝。
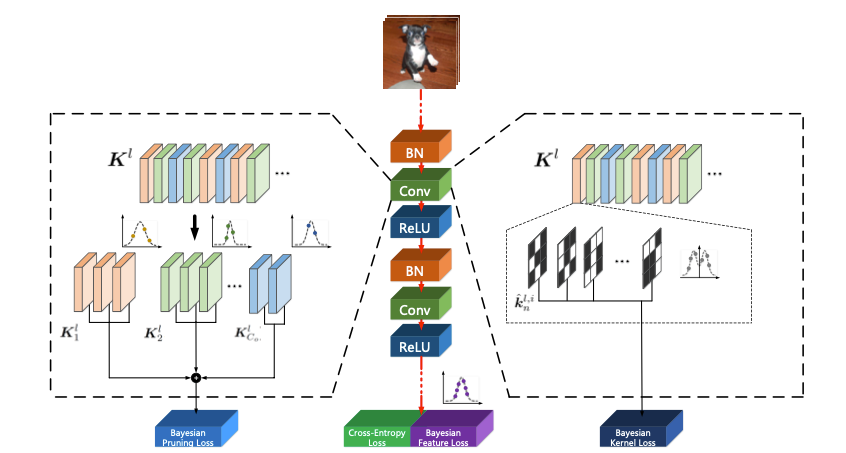
图 2 BONN训练的的总体框架
BONN的总体框架如图2所示,我们利用贝叶斯学习同时端到端地进行二值网络的训练与剪枝。我们研究了在1比特CNN的剪枝中使用贝叶斯学习的可能性,贝叶斯学习是一种成熟的全局优化方案。首先,贝叶斯学习将全精度卷积核二值化为两个量化值(中心),以获得1比特CNN。在量化误差最小化的前提下,当全精度卷积核遵循混合高斯模型时,每个高斯核以其相应的量化值为中心。给定1比特CNN的两个分布,采用构成混合模型的两个高斯函数对全精度核进行建模。随后,我们基于贝叶斯学习设计了剪枝框架来剪枝1比特CNN。特别地,我们将滤波器分成两组,假设一组中的滤波器遵循相同的高斯分布。然后使用其平均值替换该组中过滤器的权重。图2说明了我们BONN的整体框架,其中在1比特CNN的学习过程中引入了三个创新点:1)最小化量化前后参数的重建误差,2)将参数分布建模为以二值化值(-1,+1)为中心的双峰高斯混合分布,3)通过最大化后验概率剪枝量化网络。基于进一步的分析,我们得到了的三个新损失和相应的学习算法,称为贝叶斯核损失、贝叶斯特征损失和贝叶斯剪枝损失。这三种损失可在同时使用。贝叶斯学习在模型量化和剪枝过程中具有本质上的优点。所提出的损失可以进一步从权重分布和特征分布两方面全面监督1比特CNN的训练过程。
我们将BONN的训练流程具体分为两个步骤:基于贝叶斯学习的1-bit网络训练、基于贝叶斯学习的1-bit网络剪枝。
给定网络权重参数
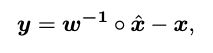
基于贝叶斯学习,在最可能的
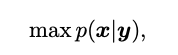
从贝叶斯学习的角度来看,我们通过最大后验概率(MAP)来解决这个问题:
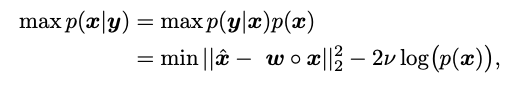
在此:
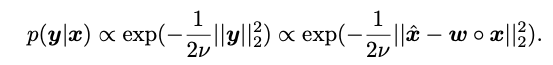
对于1比特CNN,
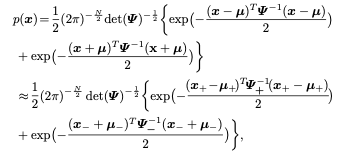
因此,优化目标可以改写为:
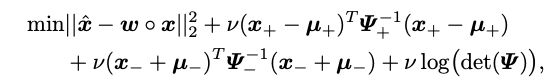
我们进一步设计了一个贝叶斯特征损失,以缓解1比特CNN中极端量化过程造成的干扰。考虑到类内紧凑性,第
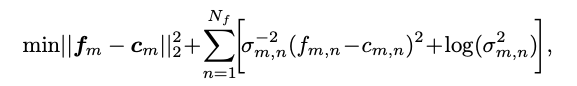
基于上述分析,我们在同一框架中考虑了卷积核和特征的潜在分布,并引入贝叶斯损失来提高1比特CNN的能力。
在对CNN进行二值化之后,我们在相同的贝叶斯学习框架下进一步修剪1比特CNN。我们认为,不同的信道可能遵循类似的分布,基于相似的信道相结合进行剪枝。从数学方面,我们通过直接扩展贝叶斯学习的基本思想,实现了关于BNN修剪的贝叶斯公式,这实际上为计算紧凑的1比特CNN提供了一种系统的方法。因此,我们定义
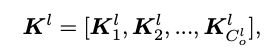
其中,
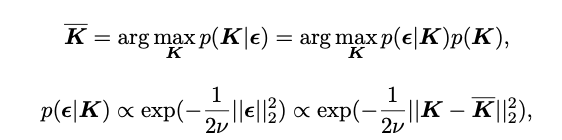
因此,我们可以得到:
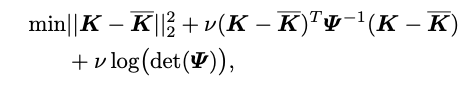
综上所述,我们我们使用三个贝叶斯损失来优化1比特CNN,这形成了我们的BONN。为此,我们重新制定了第一个用于训练损失函数为:
在训练完成后,贝叶斯剪枝损失
综上,将交叉熵损失
上述内容从理论上分析了我们BONN的作用,实验时我们在多个任务上测试了BONN的效果(包括图像分类、目标检测、人脸识别)。我们在包括CIFAR-10/100、ImageNet、PASCAL VOC、COCO、LFW、CFP、AgeDB的数据集上进行测试,来验证其性能。
在图像分类任务上,基于ImageNet数据集,我们在ResNet-18/50、MobileNet骨架网络上验证了BONN的有效性。如表1所示,我们达到了新的行业领先效果。特别的,我们的BONN* 将预先训练的ReActNet在Top-1精度方面提高了0.3% (Top-1 66.2%)。然而,ReActNet没有从预先训练的权重中获得任何改进。
表 1 ImageNet数据集上的图像分类效果
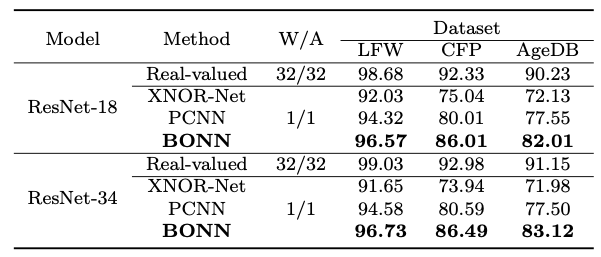
在人脸识别任务上,BONN在LFW、CFP、AgeDB数据集上取得了最优的效果,领先于XNOR-Net与PCNN。
表 2 人脸识别任务上的效果
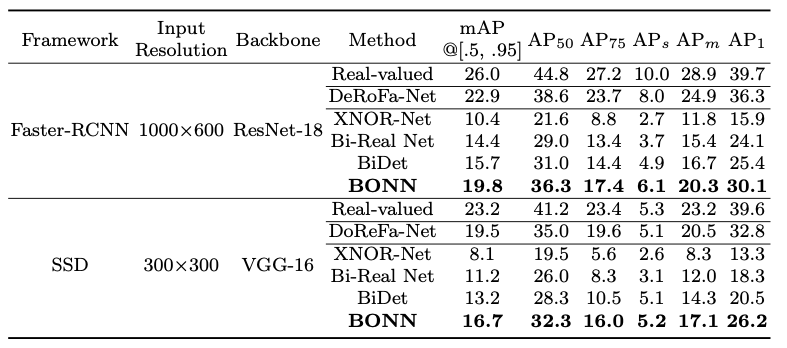
在目标检测任务上,在基于ResNet-18骨架网络的Faster-RCNN检测器上,BONN分别在PASCAL VOC与COCO数据集上取得了63.4%与19.8%的mAP;在基于VGG-16骨架网络的SSD检测器上,BONN分别在PASCAL VOC与COCO数据集上取得了69.0%与16.7%的mAP,均为行业领先。
表 3 PASCAL VOC数据集上的实验效果

表 4 COCO数据集上的实验效果
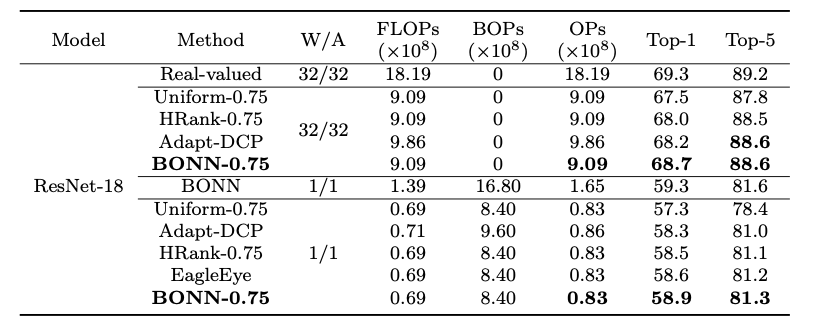
在剪枝任务上,我们先运用主成分分析,验证了我们的高斯分布假设(图3)。如表5所示,在ImageNet数据集上,BONN剪枝方法对全精度ResNet-18模型与1比特ResNet-18模型能达到较好的效果。
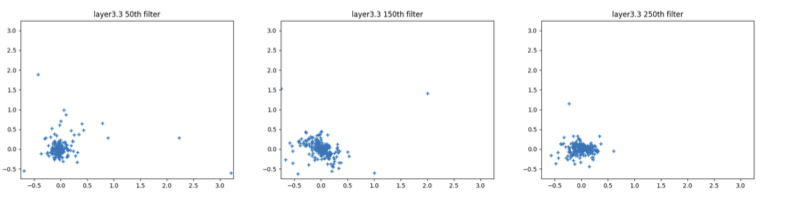
图 3 使用主成分分析(PCA)在贝叶斯剪枝中可视化ResNet-18的滤波核
表 5 ImageNet数据集上的模型剪枝效果
这篇文章提出的BONN方法同时考虑了全精度卷积核与特征分布,将全精度卷积核、特征和滤波器的先验分布纳入贝叶斯框架,以全面的端到端方式构建1比特CNN。这证明了贝叶斯学习算法可以被用提高1比特CNN的紧凑性和效果。在多个任务与数据集上的大量实验表明,BONN具有最佳的性能。在未来,我们将结合我们的方法和神经结构搜索(NAS)来构建数据自适应的1比特CNN。我们还将尝试贝叶斯优化,以找到CNN的最佳剪枝率。
[1] Gu, J., Zhao, J., Jiang, X., Zhang, B., Liu, J., Guo, G., Ji, R.: Bayesian optimized 1-bit cnns. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4909–4917 (2019)
[2] Liu, Z., Luo, W., Wu, B., Yang, X., Liu, W., Cheng, K.T.: Bi-real net: Binarizing deep network towards real-network performance. International Journal of Computer Vision 128(1), 202–219 (2020).
[3] Lin, M., Ji, R., Wang, Y., Zhang, Y., Zhang, B., Tian, Y., Shao, L.: Hrank: Filter pruning using high-rank feature map. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1529–1538 (2020).
[4] Xu, S., Zhao, J., Lu, J., Zhang, B., Han, S., Doermann, D.: Layer-wise searching for 1-bit detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5682–5691 (2021).
[5] Wang, Z., Wu, Z., Lu, J., Zhou, J.: Bidet: An efficient binarized object detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2049–2058 (2020).





