如何评价何恺明团队的最新工作RegNet?
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
问题:如何评价FAIR团队最新推出的RegNet?
知乎高质量回答
厦门大学计算机技术硕士在读 https://www.zhihu.com/question/384255803/answer/1121375506 本文来自知乎问答,回答已获作者授权,著作权归作者所有,禁止二次转载。
仔细读了一下文章,太牛逼了,好顶啊kaiming!
statistics 大法好,DL不是statistics,因为DL不如statistics。基本全文从统计学的角度解释了怎么设计网络搜索空间好,哪些要素是有用的,其深度广度以及坚若磐石的实验都令人瞠目结舌,绝对的2020年巅峰大作!这里就放结论,下面每个结论中的小点随便都能发一篇论文。
1. 实验中发现的几个关于性能的打脸结论:
无论模型多大,20个block的深度是最合适的。大网络越深越好是不对的。
bottleneck ratio设置成1是最好的。
width multiplier设置成2.5是最优质的。
剩下的初始网络宽度,group数量,宽度随深度的增长关系,这些随着模型增大而增加会是最佳选择。(大碗宽面2.0,你看我这面,就这么长,但是那么那么那么宽。)
2. 然后是几个关于复杂度(速度)的打脸结论,首先这里定义了一个所有卷积层输出tensor的大小叫做activations(这玩意你不管用啥卷积,出来tensor一样大这个值就不变):
flpos跟速度之间的关系明显没activations好,啪啪啪。具体见图:
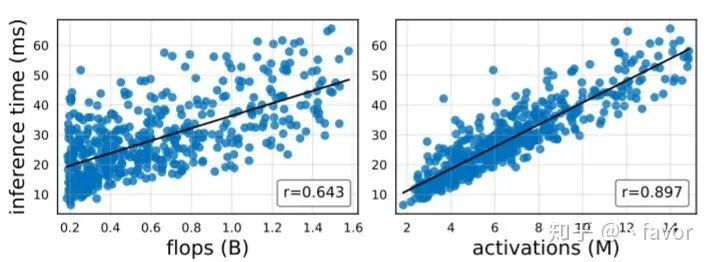
以后不要只用flops建模速度了,这玩意最好用根号flops以及线性的activations一起来建模。
3. 再是几个关于非常常见的一些设计比如inverted bottleneck以及depthwise conv的结论。首先前者稍微降低了点EDF(评价指标)(说白了就不好使),后者就还不如group conv。但是scaling the input image resolution是依然有用的。再说SE module,这玩意也有用。
------
小小地更新一下,发现10epoch 这个点争议很大。。其实从我粗浅地理解来看,文章的核心是population(总体估计),这个其实是我当时觉得有意思的一个点。。如果从NAS的individual视角来看,单个模型训10 epoch 你就评价它的好坏,那几乎没人信。但是即便是10 epoch的模型也能反应出最后的ranking结果,只不过它是带噪的,而且噪声还挺大。然而,在大量的采样下,核心规律是不会变的,只要它是有规律的而不是完全随机的,这就是大数定理大家应该都喜闻乐见。尤其是在imagenet这个量级的benchmark,如果不加trick的话,在我过往的体验里,一般刚开始好的模型大概率最后都会好。而且,文章就用了三个参数来拟合一个线性模型,这样的线性模型拟合不了任何复杂的分布,它只能反应出整体的趋势和规律。即便换成200epoch,它仍然是个线性模型。所以第一 10 epoch反映出的这个规律还是有一点的,第二采样量其实也不小(换句话说,训200epoch可能只需要采样50个模型就够了),第三模型又足够简单,这三者合一来发现一些核心规律其实是可以理解的。所以这个population的思想我觉得挺有意思的,真的非常statistics。
厦门大学计算机科学与技术博士在读 https://www.zhihu.com/question/384255803/answer/1122828283 本文来自知乎问答,回答已获作者授权,著作权归作者所有,禁止二次转载。
首先纠正一下大家,这个其实是Ilija Radosavovic 一系列的工作,Ilija Radosavovic 在这个系列上出了两篇工作第一篇评价搜索空间,挂没挂kaiming he 我忘记了,第二篇,也就是这篇,在第一篇的基础上,不断的 shrink 搜索空间来获取insight辅助设计网络。
首先看到这个文章第一个想法是作者土豪啊,大家现在NAS的做法是某点突破,首先在一个搜索空间上,怎么想着拼命节约时间,怎么节省怎么来,很多NAS文章都透露着穷酸相,这篇文章直接开始 农村包围城市了,直接对search space 指手画脚了。
例如上图,从A走到B大概需要在Imagenet上训练 500x10 epoch吧。
现在可以把NAS文章按照卡的等级分为这么几类:
1. 穷逼高校研究组,特点是基本上就搞cifar10,实在不行cifar100。
什么,搜索imagenet?搜索imagenet是不会搜索的,这辈子都不可能的,又没有卡,就是在cifar10上搜索这样子,然后加上autoaugmentation ,调试调试参数,刷刷performance这样子,在cifar10上搜索呢,感觉比imagenet上好多了,实验又容易做,每次随便搜索性能又好,超喜欢cifar10上搜索。然后搜索完成结构随便迁移到Imagenet训练一下这样子,才能稍微维持一点水文章的速度。
2. 中产高校研究组/start up 公司
这些单位有条件直接在ImageNet上搜索了,开始定点突破了,大家都在疯狂的刷 600FLOPS下最优的网络结构,主要就是在MobilenetV2/V3上面疯狂的搜索+调试参数。紧跟Google步伐,google公布一个架构backbone,大家疯狂的跟上,搜索一波,然后再PR,我beat 了 efficientNet!牛逼不牛逼???当然,请忽略我仅仅beat 了 efficientB0这个事实。但是其实讲道理,我挺喜欢这些工作的,也推荐大家使用这些结构,因为确实不错,里面真心推荐once for all,虽然代码复杂了点,但是目前 600M flops下我目前没看到谁超越。
3. 来到了我们的主角了,土豪研究组,众星捧月,一出文章大家疯狂follow,比如Facebook的 fair,或者 google quoc le团队。
每次Quoc Le 一发文章,所有人就follow,有的叫道“Quoc Le,你又发文章了!”Quoc Le也不回答,对Google集群说,提交1000个模型,每个模型设置不一样的参数,精确到小数点后两位,“你又调参数来涨点了”他便涨红了脸,额上的青筋条条绽出,争辩道,“修改参数不叫调参,又没有用hyperband,”接着便是一些难听的话,“为了获取更好的insight”引得众人都哄笑起来:店内外充满了快活的空气。讲道理,对于这两个公司,我感觉更喜欢Quoc le 吧,每次发的文章都很有insight,也确实看到他们在自己有很多卡的基础上,做了很多探索性质的工作,而且都很solid,文章一出实验上让人无话可说。比如NASbench 101,比如 efficientNet,mobilenetV3,Facebook显然后劲不足,当然,比我们是强多了,我指的是和Google相比。
回到这篇文章上来讲吧,做几个客观事实描述:
这篇文章有没有insight?有,而且还挺多,确实很不错,至少做了很多实验,让大家看到诚意。比如高赞回答的那些点都回答的很好了,主要就是这些优点。这些点都在设计网络上可以作为参考。
我来主要说一下缺点吧,
1. 在这个问题下面也有人描述,其实imagenet上训练10 epoch,显然不够的,其实epoch会对结果影响很大,没有大量的实验作为参考,莫名其妙就把epoch设定为10显然不合理,因为epoch改变对于结构的rank影响非常大,所以对于后面的结论都要有一点疑问。我作为搞nas的来讲,cifar10上10epoch都会极大地降低 相关度,更别提imagenet了。
2. Anynet search space 太overclaim了,很多参数明明就是按照现有的网络结构先验设定好的,比如开始卷积层,比如stage的设置,比如一些block的设置。
3. 搜索空间的跃迁太快了,比如一上来立马就固定/share一些超参数,但是现在很多都是不固定的,我要吹一波 hansong 组cai han的proxylessNAS 还有 once for all了,在他们搜索的时候很明显不share 获得更好的网络结构。
4. 最后的Flops指标的问题,这个其实很不错,FLOPS和GPU 下不是线性其实很多人都注意到了,其实FLOPS更能反应的是CPU上的运算速度。
总的来说,前面三个地方需要略微修改,特别是第一个,为什么正好是10epoch,比如在一个imagenet 的子集上证明了10 epoch, 100 epoch带来的变化不大,那就可以解释得通。其他其实都是小问题。相比于FAIR组之前的一些文章,纯粹的个人观点,工程可用性上不如FBnet,在insight上不如 random wired Net。不过这篇文章的实验已经足够solid,虽然不如之前的文章,当然大部分人已经都要好很多了,值得是一篇oral。
关于何恺明团队的最新工作RegNet,你怎么看?欢迎在下方留言区抒发你的见解~
*延伸阅读
何恺明团队最新力作RegNet:超越EfficientNet,GPU上提速5倍,这是网络设计新范式 | CVPR 2020
你需要关注的计算机视觉论文在这里!最新最全state-of-art论文,包含阅读笔记
谷歌开源EfficientDet:实现新SOTA,又快又准的目标检测器

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




