2022年,图机器学习Graph ML发展到哪了?

原文链接:https://mgalkin.medium.com/graph-ml-in-2022-where-are-we-now-f7f8242599e0
对于 Graph ML 来说已经过去了一年:成千上万的论文,无数的会议和研讨会,如何赶上这么多很酷的进展?

本文对 Graph ML 进行结构化分析,重点介绍热门趋势和重大进步。

Graph Transformers + Positional Features
虽然 GNN 在通常在稀疏的图上运行,但 Graph Transformers (GT) 在全连接图上运行,其中每个节点都连接到图中的每个其他节点。一方面,这带来了节点数 N 的 O(N²) 复杂度。另一方面,GT 不会遭受过度平滑,这是长距离消息传递的常见问题。(为什么不会过平滑?)
全连接图意味着我们有来自原始图的“真”边和从全连接变换添加的“假”边,我们想区分它们。更重要的是,我们需要一种方法来为节点注入一些位置特征,否则 GT 会落后于 GNN(如Dwivedi 和 Bresson的2020 年论文所示)。今年最引人注目的两个Graph Transformers可能是SAN(Spectral Attention Nets)和Graphormer。
-
SAN采用的top-k的拉普拉斯特征值和特征向量,其可以单独区分由1-WL测试考虑同构的图。SAN 将光谱特征与输入节点特征连接起来,在许多分子任务上优于稀疏 GNN。
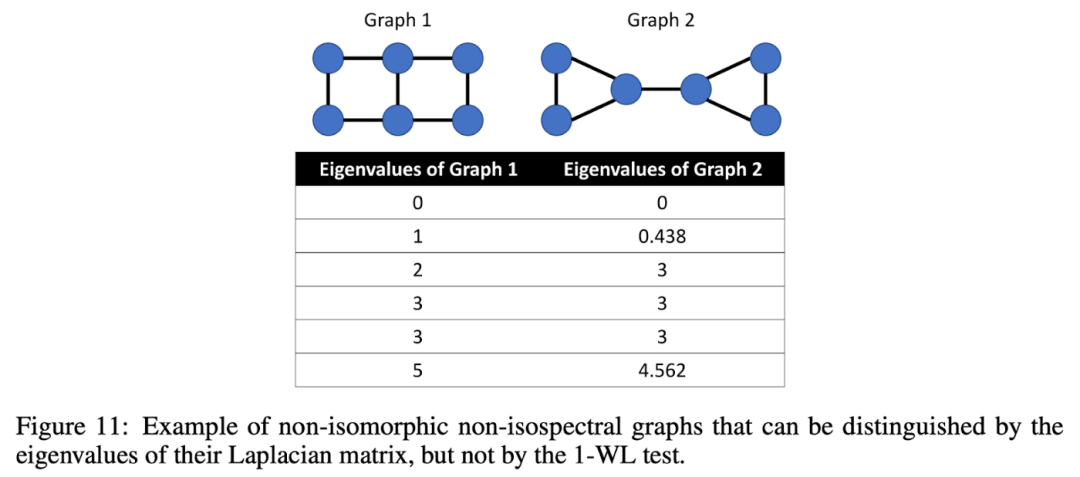
-
Graphormer采用不同的方法主要在空域来搞。首先,节点特征考虑了中心性编码——可学习的入度和出度嵌入。然后,注意力机制有两个偏置项:(1) 节点i和j之间最短路径的距离;(2) 边特征编码,其取决于可用的最短路径之一。
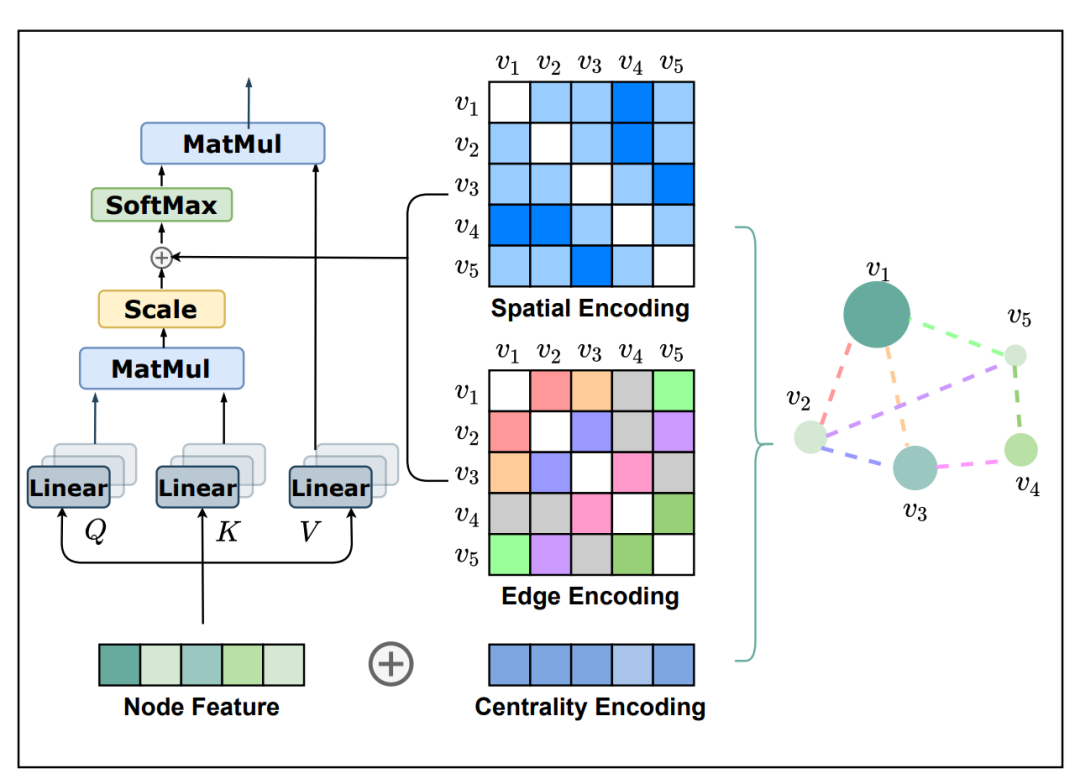
🏅 Graphormer 完成了 2021 年 Graph ML 的大满贯:在 OGB大规模挑战和开放催化剂挑战的图回归任务中获得第一名!
🤔 开放性问题:可扩展性和计算开销。SAN 和 Graphormer 在分子任务上进行了评估,其中图相当小(平均 50-100 个节点),我们可以负担得起,例如,运行 O(N³) Floyd-Warshall 所有对最短路径。此外,Graph Transformers 仍然受到 O(N²) 注意力机制的限制。对于大图是不可接受的。您是否只是想到“Linear transformers from NLP”?😉 是的,他们可能会伸出援手,但由于其未实现注意力矩阵,因此需要找到一种聪明的方法将边特征置于此类模型中。当然,我们会在 2022 年看到更多关于这方面的研究!
Equivariant GNNs
Geoffrey Hinton 承认其酷炫的等效性有何独特之处?
一般来说,equivariance定义在某些变换组上,例如,3D 旋转形成 SO(3) 组,3 维特殊正交组。equivariance模型在 2021 年掀起了 ML 的风暴🌪,在 Graph ML 中,它在许多分子任务中尤其具有破坏性。应用于分子,Equivariant GNN 需要一个额外的节点特征输入——即分子物理坐标的一些表示,这些表示将在 n 维空间中旋转/反射/平移。
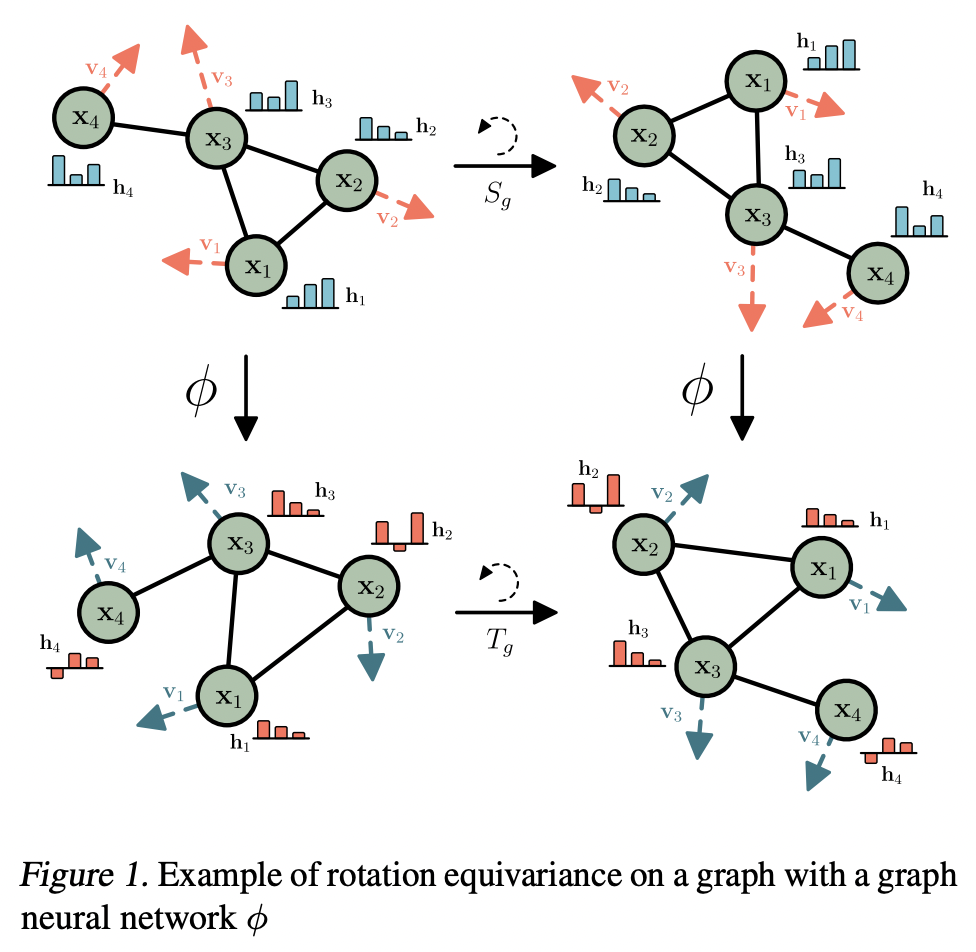
使用等变模型,尽管变换顺序不同,我们仍会达到相同的最终状态。
Satorras、 Hoogeboom和 Welling提出了EGNN、E(n) 等变 GNN,其与普通 GNN 的重要区别在于向消息传递和更新步骤添加物理坐标。等式 3 👇将相对平方距离与消息 m 相加,等式。4 更新位置特征。EGNN 在建模 n 体系统、作为自动编码器和量子化学任务(QM9 数据集)方面显示出令人印象深刻的结果。
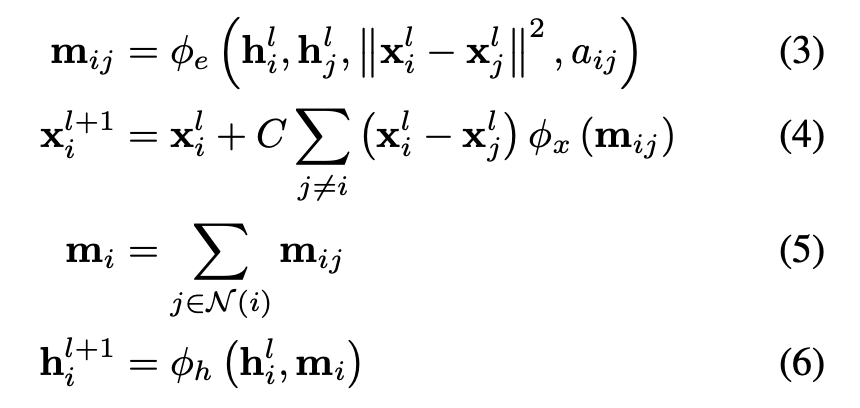
与普通 GNN 的重要区别:等式 3 和 4 在消息传递和更新步骤中添加了物理坐标。
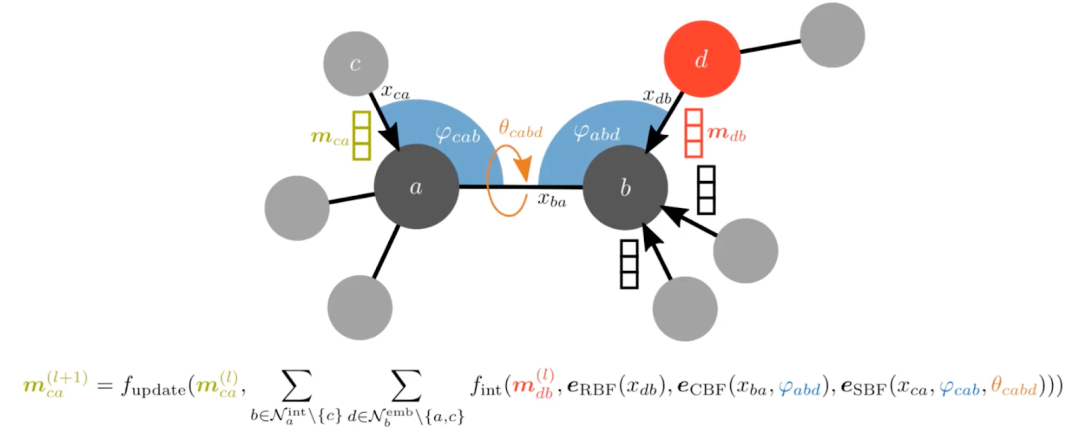
另一种选择是在原子之间掺入角度。这可能需要将输入图转换为线性图,其中来自原始图的边变成线性图中的节点。这样,我们就可以将角度作为新图中的边缘特征。
Generative Models for Molecules
由于几何深度学习,整个药物发现 (DD) 领域在 2021 年得到了显着的推动🚀。DD 的众多关键挑战之一是生成具有所需属性的分子(图)。这个领域很大,所以我们只强调模型的三个分支。
-
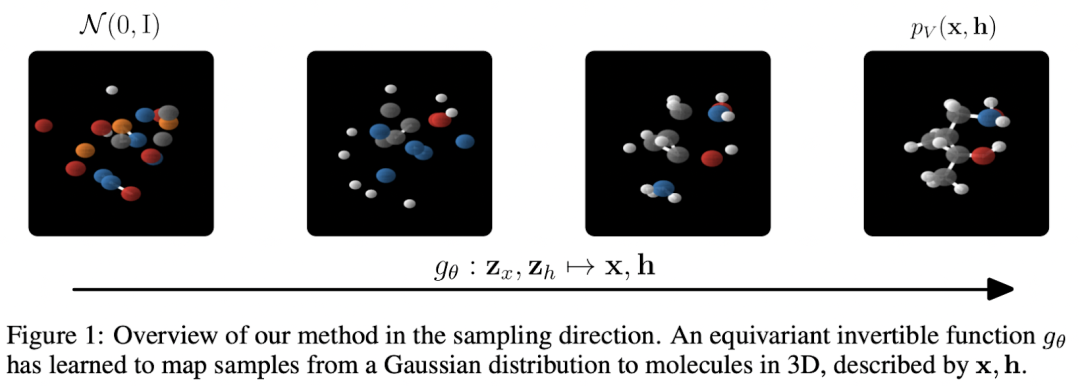
规范化流程。Satorras、Hoogeboom 等人应用上述等方差框架来创建E(n) 等变归一化流,能够生成具有位置和特征的 3D 分子💪
-
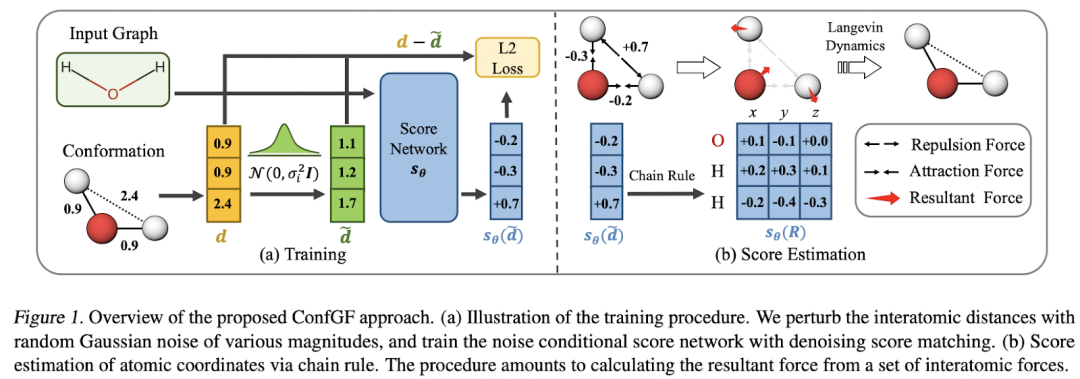
概率模型。Shi、Luo 等人研究了在给定 2D 图形的情况下生成 3D 构象异构体(即 3D 结构)的问题。模型 ConfGF估计原子坐标对数密度的梯度场。这些字段是旋转平移等变的,作者想出了一种方法将这种等变属性合并到估计器中。Conformer 采样本身是通过退火动态采样完成的。
-
RL 方法。以一种非常非科学的方式描述,这些方法通过逐步附加“构建块”来生成分子。我们可以根据这些方法对构建过程的调节方式对其进行广义分类。例如,Gao、Mercado 和 Coley以可合成性为构建过程的条件,即我们是否可以在实验室中实际创建 🧪 这种分子。为此,他们首先学习如何创建构建块的合成树(一种模板)。
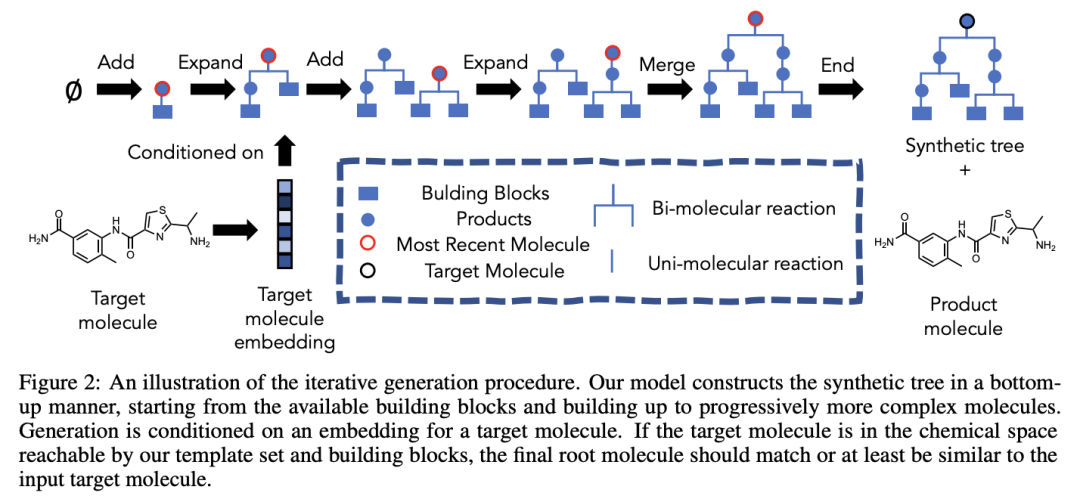
由 Yoshua Bengio 领导的 Mila 和斯坦福研究人员团队提出了一个更通用的框架,他们引入了生成流网络(GFlowNets)。很难用几句话来概括——首先,当我们想要对不同的候选者进行采样时,GFlowNets 可以用于主动学习案例,并且采样概率与奖励函数成正比。此外,他们最近的 NeurIPS'21 论文展示了 GFlowNets 应用于分子生成任务的好处。
GNNs + Combinatorial Optimization & Algorithms
2021 年对于这个新兴的子领域来说是重要的一年!Xu 等人在他们杰出的 ICLR'21 论文中研究了神经网络的外推,并得出了几个惊人的结果。通过算法对齐的概念,作者表明 GNN 与动态规划 (DP)很好地对齐(查看插图 👇)。事实上,比较经典 Bellman-Ford 算法的迭代以寻找最短路径和通过 GNN 的消息的聚合组合步骤——你会发现很多共同点。此外,作者表明,在建模特定 DP 算法时,为 GNN 选择合适的聚合函数至关重要,例如,对于 Bellman-Ford,我们需要一个最小聚合器。我还建议您查看一个非常具有说明性的演讲 作者:Stefanie Jegelka 在 2021 年深度学习和组合优化研讨会上解释了这项工作的主要成果。
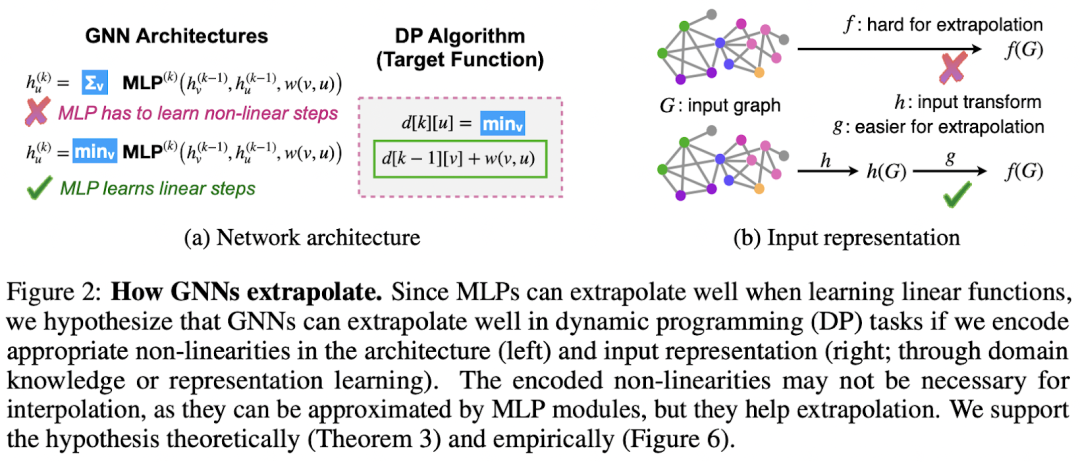
为了更全面地介绍该领域,我想重点介绍Cappart 等人 在IJCAI'21 上进行的一项全面调查,该调查涵盖了组合优化中的 GNN。这篇文章首次出现了神经算法推理蓝图。

📘 蓝图解释了神经网络如何在嵌入空间中模仿和授权通常离散算法的执行过程。在编码-处理-解码方式中,抽象输入(从自然输入获得)由神经网络(处理器)处理,其输出被解码为抽象输出,然后可以映射到更自然的任务特定输出。例如,如果抽象输入和输出可以表示为图形,那么 GNN 可以是处理器网络。的离散算法的一个常见的预处理步骤是壁球无论我们了解这个问题,到像“的标量距离”或“边缘容量' 并在这些标量上运行算法。相反,向量表示和神经执行可以轻松启用高维输入而不是简单的标量,并附加反向传播以优化处理器。
Subgraph GNNs: Beyond 1-WL
🤝 如果说 2020 年是第一次尝试离开 GNN 表现力的 1-WL-landia 的一年,那么我们可以确认 2021 年是与超越 1WL-landia 的外星人建立稳固联系的一年👾。
如果您想真正深入研究 WL 的最新研究,请查看由 Christopher Morris、Yaron Lipman、Haggai Maron 和合著者撰写的最新调查Weisfeiler 和 Leman go Machine Learning: The Story so far。
Scalability and Deep GNNs: 100 Layers and More
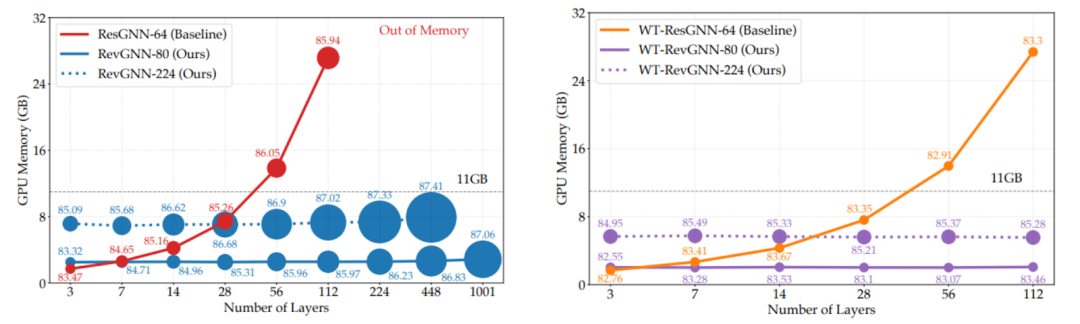
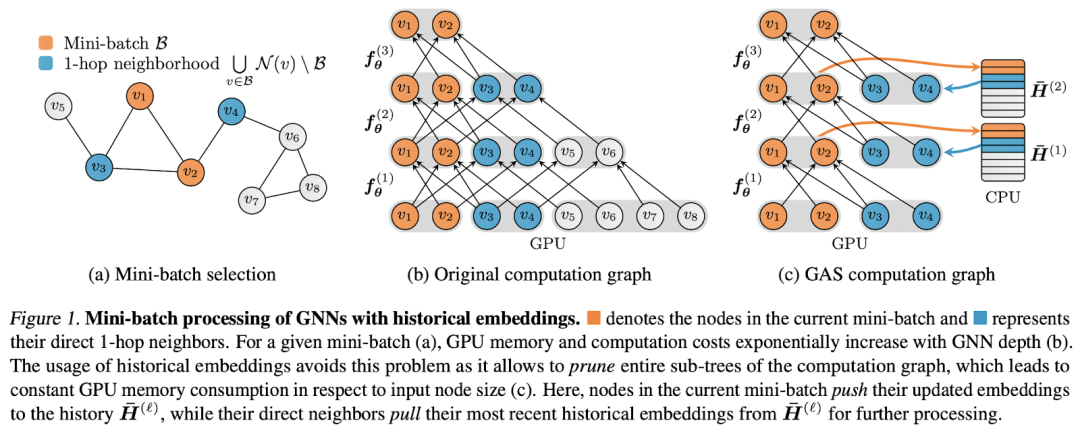
如果您在使用 2-4 层 GNN 时嫉妒深度 ResNets 或 100 层以上的巨大 Transformer,那么是时候欢呼了🤩!2021 年为我们带来了 2 篇随意训练100-1000 层GNN 的论文,以及一篇关于几乎恒定大小的邻域采样的工作。Li 等人提出了两种机制,在训练极深的超参数化网络时,将 GPU 内存消耗从L 层的O(L)显着降低到O(1)。作者展示了如何使用 1️⃣ 可逆层在 CV 或高效的 Transformer 架构(如Reformer )中使用多年;2️⃣ 在层之间共享权重(权重绑定)。然后可以训练多达 1000 层的 GNN 👀。下面的图表展示了对 GPU 要求适中的层数的不断扩展。
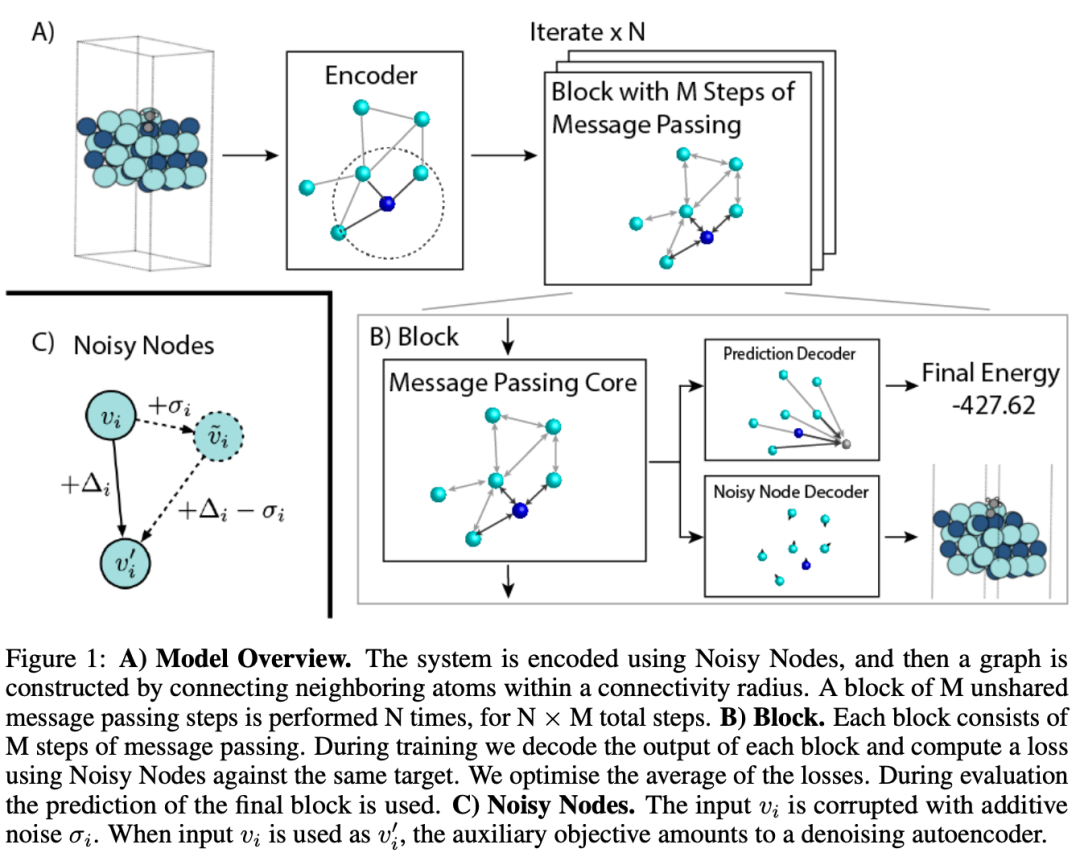
Godwin 等人介绍了一种利用循环学习深度 GNN 的方法——消息传递步骤组织在块中,每个块可以有 M 个消息传递层。然后,循环应用 N 个块,这意味着块共享权重。如果您有 10 个消息传递层和 10 个块,您将得到一个 100 层的 GNN。一个重要的组成部分是噪声节点正则化技术,它扰动节点和边缘特征并计算额外的去噪损失。该架构适合更好的分子任务,并在 QM9 和 OpenCatalyst20 数据集上进行了评估。
最后,如果我们想将任意 GNN 缩放到非常大的图,除了采样子图之外,我们别无选择。通常,对 k 跳子图进行采样会导致指数级内存成本和计算图大小。
PyG 的作者Matthias Fey 等人创建了GNNAutoScale,这是一个在恒定时间内利用历史嵌入(来自先前消息传递步骤的缓存的奇特版本)和图聚类(在这种情况下是众所周知的 METIS 算法)扩展 GNN 的框架. 在预处理期间,我们将图划分为 B 个集群(小批量),以便最小化集群之间的连通性。然后我们可以在这些集群上运行消息传递以跟踪缓存中更新的节点功能。在实验上,深度网络的 GNNAutoScale(最多 64 层)的性能与全批次设置一样好,但显着降低了内存要求(小了约 50 倍)——因此您可以在商品级 GPU 上安装深度 GNN 和大图 💪
Knowledge Graph
KGs 上的表征学习终于突破了转导的天花板。在 2021 年之前,模型明确分为转导和归纳,具有不同的归纳偏差、架构和训练机制。换句话说,转导模型没有机会适应看不见的实体,而归纳模型在中大型图上训练成本太高。2021 年带来了两种架构
-
在转导和归纳环境中工作, -
不需要节点特征, -
可以在归纳模式中以与转导模式相同的方式进行训练, -
可扩展到现实世界的 KG 大小。第一个是 Neural Bellman-Ford nets。作者找到了一种非常优雅的方法将经典的 Bellman-Ford 推广到更高级别的框架,并展示了我们如何通过使用特定运算符实例化框架来获得其他知名方法,例如Katz index、PPR或Widest Path。更重要的是,他们表明广义 Bellman-Ford 本质上是一个关系 GNN 架构(算法对齐的另一个确认GNN 和动态规划之间)。NBFNet 不学习实体嵌入(仅关系和 GNN 权重),这使模型通过设计和泛化到看不见的图具有归纳性。该模型在关系图和非关系图上的链接预测任务上都表现出色。应用于 KG,NBFNet 从 2019 年开始为 FB15k-237 和 WN18RR 带来最大的性能提升,同时参数减少了 100 倍💪。

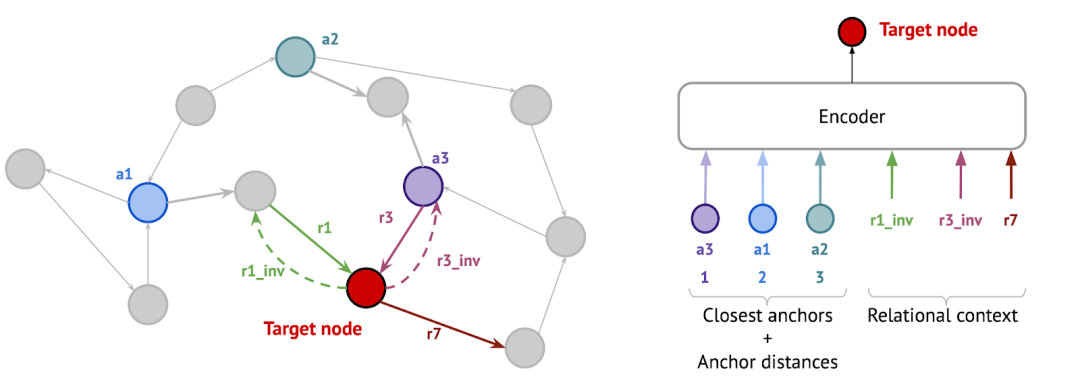
🍰 Galkin 等人的另一种方法(免责声明:本文的作者之一是论文的作者)的灵感来自 NLP 中的标记化算法,该算法具有固定的标记词汇表,能够标记任何单词,甚至是那些在训练期间看不见的单词时间。应用于KG,NodePiece将每个节点表示为一组top-k最近的锚节点(可选地在预处理步骤中采样)和m节点周围的唯一关系类型。锚点和关系类型被编码为可用于任何下游任务(分类、链接预测、关系预测,仅举几例)和任何归纳/转导设置的节点表示。NodePiece 特征可以直接被 RotatE 等非参数解码器使用,也可以发送到 GNN 进行消息传递。该模型在归纳链接预测数据集上与 NBFNet 相比具有竞争力,并在大图上表现出高参数效率——OGB WikiKG 2上的 NodePiece 模型需要的参数比浅层转导模型少约 100 倍。
Generally Cool Research with GNNs
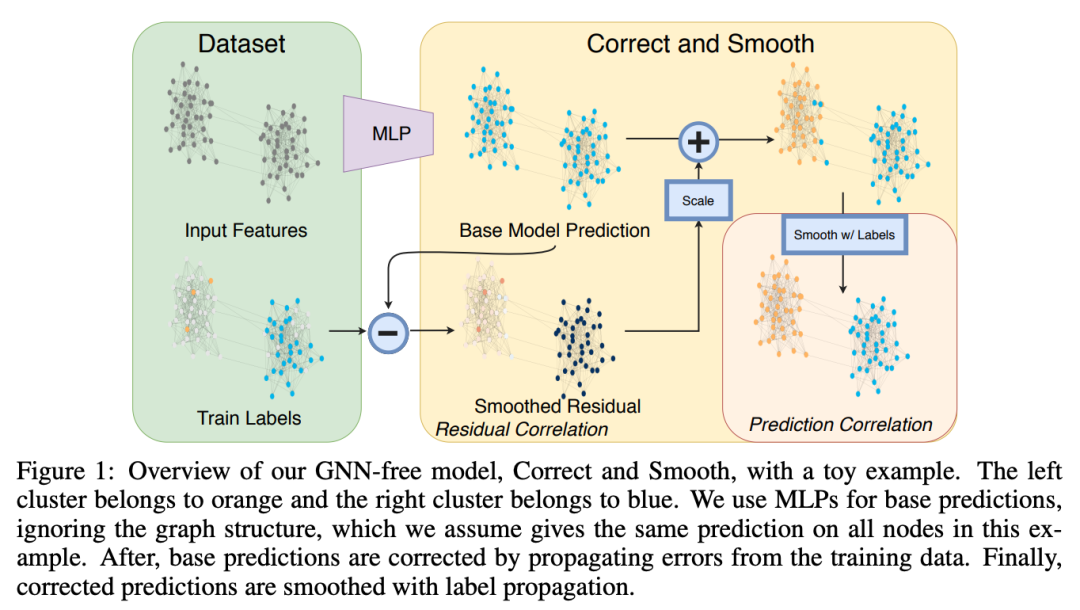
本节提到了几个特别酷的作品,它们使用了 GNN,但不属于某个特定类别。Huang、He 等人在 ICLR'21 上展示了Correct & Smooth — 一个通过标签传播改进模型预测的简单程序。仅与 MLP 搭配使用,该方法在不使用任何 GNN 且参数少得多的情况下以最高分冲击 OGB 排行榜!今天,几乎所有OGB 节点分类轨道中的顶级模型都使用 Correct & Smooth 来挤压更多的点。
🪄 Knyazev 等人在 11 月以一次前向传递中预测各种神经网络架构参数的工作震惊了 ML 社区。也就是说,不是随机初始化模型,而是可以立即预测出好的参数,这样的模型已经比随机模型好得多了👀。当然,如果你用n 个SGD 步骤优化一个随机初始化的网络,你会得到更高的数字,但本文的一个主要贡献是,通常可以在不 训练这个特定架构的情况下找到合适的参数。参数预测实际上是一个图学习任务——任何神经网络架构(ResNet、ViT、Transformers,你说的)都可以表示为一个计算图,其中节点是具有可学习参数的模块,节点特征是那些参数,我们有一堆节点类型(比如,线性层、卷积层、批范数,作者使用了大约 15 种节点类型)。参数预测则是一个节点回归任务。计算图使用 GatedGNN 进行编码,并将其新表示发送到解码器模块。为了训练,作者收集了一个包含 1M 个架构(图)的新数据集。该方法适用于任何神经网络架构,甚至适用于其他 GNN!
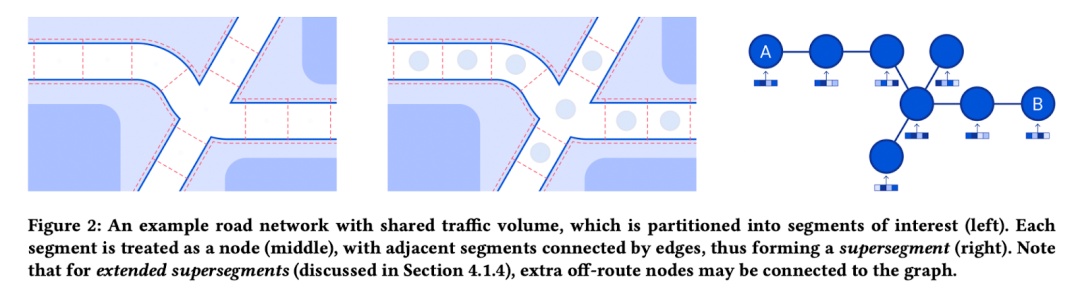
🗺 DeepMind 和谷歌通过将道路网络建模为超分段图并在其上应用 GNN,极大地提高了谷歌地图中 ETA 的质量。在Pinion 等人的论文中,该任务被定义为节点级和图级回归。除此之外,作者还描述了许多需要解决的工程挑战,以便在谷歌地图规模上部署系统。应用 GNN 解决数百万用户面临的实际问题的完美示例!
Transgene 和 NEC最近宣布了GNN 在癌症研究中的另一个潜在影响应用。根据NEC 首席研究员Mathias Niepert 的说法,GNN 被用于通过嵌入传播来估算丢失的患者数据(查看最近关于此方法的Twitter 线程)以及对候选肽进行评分以引发免疫反应。最后,DeepMind 的Davies 等人最近使用 GNN 来帮助制定与核心数学问题有关的猜想(关于 🪢 结 🪢 在他们的工作中),实际上确实找到并证明了一个新定理!你看,GNN 也可以处理非常抽象的事情 👏
New Datasets, Challenges, and Tasks
如果您厌倦了 Cora、Citeseer 和 Pubmed — 我们会感觉到您。2021 年带来了大量不同大小和特征的新数据集。
-
OGB 在 KDD'21组织了大规模挑战,其中包含 3 个非常大的图用于节点分类(240M 节点)、链接预测(整个 Wikidata,90M 节点)和图回归(4M 分子)。在 KDD 杯中,大多数获胜团队使用了 10-20 个模型的合奏——查看研讨会录音以了解有关他们方法的更多信息。新版本的 LSC 数据集现在可用于新的排行榜! -
Meta AI 的Open Catalyst NeurIPS'21 Challenge提供了一项大型分子任务——在给定具有原子位置的初始结构的情况下预测松弛态能量。数据集很大,需要大量的计算,但组织者暗示会发布一个更小的版本,这对 GPU 预算有限的小型实验室会更友好一些。结果和录音可用——等变模型和变压器达到了顶峰。事实上,Graphormer 在 OGB LSC 和 OpenCatalyst'21 中都获得了前 1 名,几乎在 2021 年收集了 Graph ML 的大满贯 🏅 -
WebConf 2021带来了新的数据集,包括收集非homophilous图由Lim等,图形模拟由Tsitsulin等,时空图由Rozemberczki等人,更多的人 -
NeurIPS'21 Datasets & Benchmarking Track就像一个新数据集的 SXSW 节:今年我们有MalNet——图分类,其中平均图大小为 15k 节点和 35k 边,比分子大得多;ATOM3D — 新的 3D 分子任务的集合;RadGraph — 从放射学报告中提取信息。最后, Liu 等人报告了创建图学习数据集分类法的挑战——社区肯定会从中受益。
Courses and Books
新的和值得注意的课程和书籍:
-
几何深度学习原书和课程,作者为 Michael Bronstein、Joan Bruna、Taco Cohen 和 Petar Veličković。包含 12 个讲座和实践教程和研讨会。如果您喜欢视频录制,Michael 的 ICLR'21主题演讲是今年发布的关于图形的最佳视频。 -
由 18 (!) 位作者撰写的关于知识图谱的新开放书。整本书可以通过网络形式免费获得;它包含许多关于方法、模式和查询的详细信息。威廉汉密尔顿的图表示学习书。虽然技术上于 2020 年发布,但从现代深度学习的角度来看,它仍然是对 GML 最好的简短介绍。
Libraries & Open Source
2021 年发布的新库:
-
TensorFlow GNN — GNN作为 Tensorflow 世界中的一等公民。 -
TorchDrug — 用于分子和 KG 任务的基于 PyTorch 的 GNN 库 已建立的 Graph ML 库已更新: -
PyG 2.0 — 现在支持异构图、GraphGym 以及一系列改进和新模型 -
DGL 0.7 — GPU 上的图形采样、更快的内核、更多模型 -
PyKEEN 1.6 — 用于训练 KG 嵌入的首选库:更多模型、数据集、指标和 NodePiece 支持! -
Jraph -用于JAX爱好者GNNS,看看这个新鲜的前奏建设和评估GNNS由汪明荃(DeepMind)和尼古拉·约万诺维奇(ETH苏黎世)

