经历了围棋、星际争霸、Dota、扑克、麻将……强化学习似乎正在挑战难度越来越高的人类游戏。但 OpenAI 近日的一份研究似乎打破了这种刻板印象,让 AI 玩起了捉迷藏。在训练了 3.8 亿轮之后,AI 学会了各种围追堵截和反围追堵截的套路,而且有些套路还是研究者始料未及的操作。
为了进行这个捉迷藏游戏,OpenAI 首先构建了一个包含墙、盒子和斜坡的 3D 环境。在这个环境中,智能体以团队为单位进行捉迷藏游戏。
隐藏方(蓝色小人)的任务是躲避搜索方(红色小人)的视线,而搜索方的任务是紧紧追逐隐藏方。
环境中不仅散布着隐藏方和搜索方可以适时抓取和锁定的目标,而且还有智能体必须学习操控的随机生成的固定房间和墙壁。
在捉迷藏游戏开始前,隐藏方(蓝)会进入准备阶段,这时搜索方(红)固定不动,给隐藏方逃跑或改变环境的机会。
![]()
在这个游戏中,赢得游戏的隐藏方和搜索方都会获得奖励,因此他们要不断更新自己的策略。
当然,这种奖励是以团队为单位的。如果所有隐藏方成功隐藏,则奖励+1;相反,如果任何隐藏方被搜索方发现,则奖励-1。搜索方的奖励方式恰恰相反,即如果所有隐藏方成功隐藏,则奖励-1;如果任何隐藏方被发现,则奖励+1。
游戏中智能体的行为需要控制在合理的空间,如果超出游戏区域,则会受到惩罚。在准备阶段,所有智能体的奖励为零。
在经过了多轮训练之后,智能体学会了 6 种策略:1)奔跑和追逐;2)隐藏方学会移动砖块构建堡垒;3)搜索方学会移动斜坡以跳进隐藏方的堡垒;4)隐藏方学会将所有的斜坡搬进自己的堡垒;5)搜索方学会跳到盒子上滑行,进而跳到隐藏方的堡垒;6)隐藏方学会将所有的盒子锁定在适当的位置,以防被搜索方利用。
![]()
![]()
![]()
![]()
隐藏方学会将所有的盒子锁定在适当的位置,以防被搜索方利用。
虽然游戏环境非常简单,但这一过程中智能体以自监督方式学到的策略复杂度逐渐升高,表明多智能体互适应有朝一日可能会产生极其复杂和智能的行为。
为了进一步了解 OpenAI 这一研究背后的意义及动机,机器之心对研究者进行了采访。在谈到为何选择捉迷藏游戏训练智能体时,OpenAI 的研究者表示,因为这个游戏规则比较简单。
从生物进化的角度来看,人类是一个可以不断适应新环境的物种,但人工智能却没有这种特性。近年来机器学习在围棋以及 Dota 2 等复杂的游戏中取得了显著进步,但这些特定领域的技能并不一定适应现实场景中的实际应用。因此,越来越多的研究者希望构建在行为、学习和进化方面更类人的机器智能。
由于捉迷藏游戏中的目标相对简单,多个智能体通过竞争性的自我博弈进行训练,学习如何使用工具并使用类人技能取得胜利。研究者观察到,智能体在简单的捉迷藏游戏中能够实现越来越复杂的工具使用。在这种简单环境中以自监督方式学到的复杂策略进一步表明,多智能体协同适应将来有一天可能生成极度复杂和智能的行为。OpenAI 相信,这一研究会成为一个智能体开发和部署的非常有前景的方向。
文章的作者之一、OpenAI 研究员吴翼 告诉机器之心,「社区的研究真的需要优质和有趣的环境,这一环境比 2D 粒子世界复杂一点,但又不至于像星际争霸那么复杂。」
OpenAI 正在开源他们的代码和环境,以鼓励这一领域的进一步研究。
如何训练捉迷藏智能体
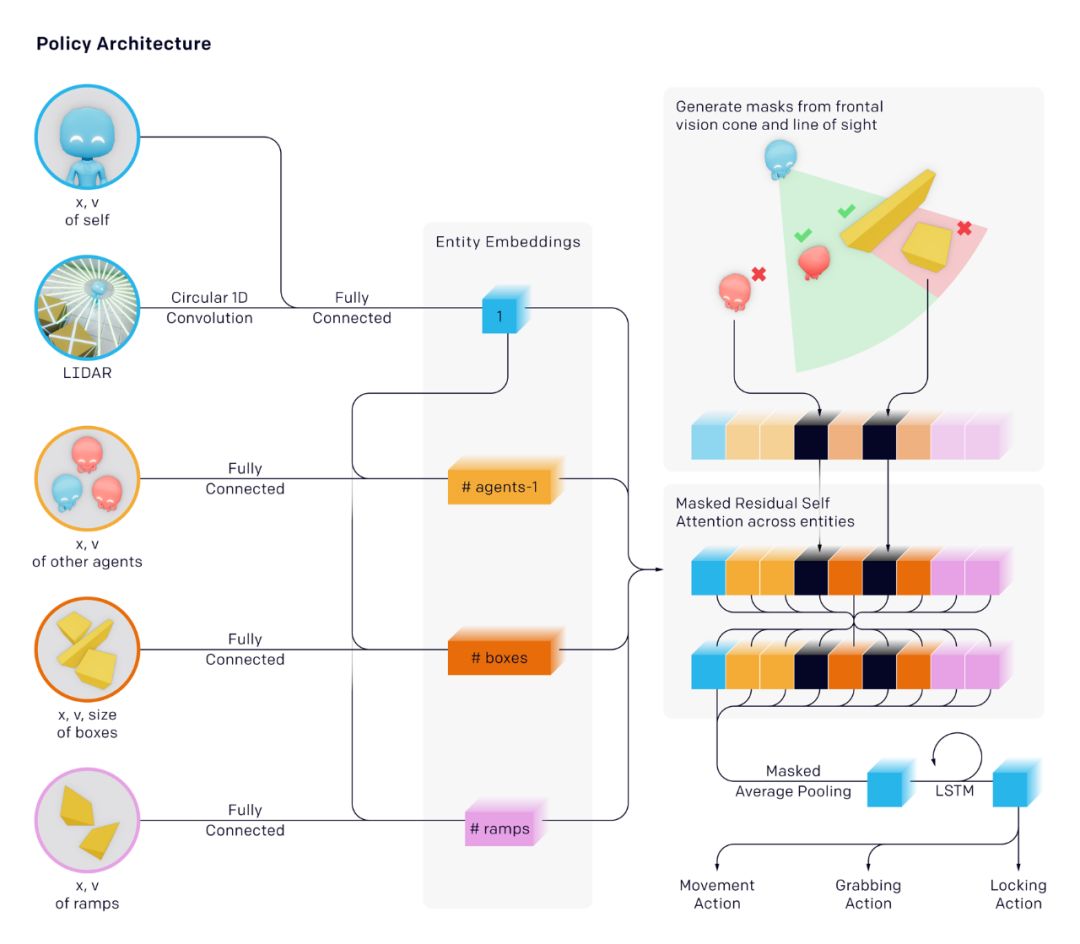
在此研究中,研究者使用了和 OpenAI Five、Dactyl 相同的培训基础架构和算法。但是,在该环境中,每个智能体都使用自己观察和隐藏的记忆状态独立行动。智能体使用以实体为中心的、基于状态的世界表征,也就是对其他目标和智能体是排列不变的。
在该研究中,嵌入的每个目标被传递通过一个 mask 残差自注意块,这类似于 Transformer,其中的注意力集中在目标上而不是时间上。不在视线内以及在智能体前面的目标被 mask 掉,以使得智能体没有它们的信息。
![]()
然后,通过自我博弈和临近策略优化(Proximal Policy Optimization (https://openai.com/blog/openai-baselines-ppo/))训练智能体策略。在优化期间,智能体可以在价值函数中使用有关被遮挡目标和其他智能体的特权信息。
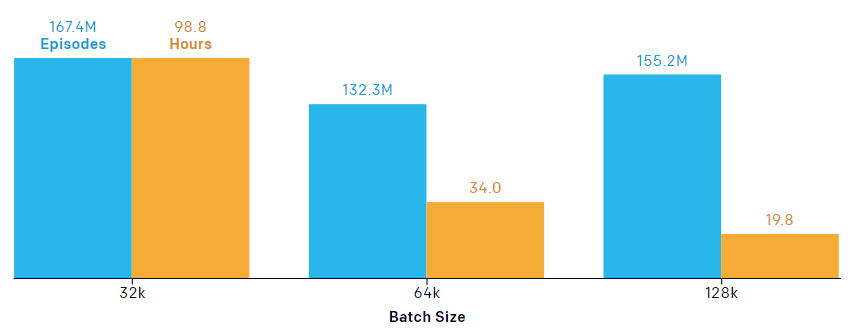
研究者发现,大规模训练对于各个阶段的智能体学到何种策略来说至关重要。下图展示了智能体在各种 batch 大小情况下,学会第 4 种策略(将斜坡搬进自己的堡垒)所需的 episode 和时间。他们发现,增加 batch 大小可以大大提升收敛速度,然而当 batch 大小为 32k 或更高时,采样效率不会受到影响。但是,他们还发现,在指定的 episode 数量下,batch 大小为 8k 和 16k 时,智能体从未学会第 4 种策略。
![]()
增加 batch 大小加速收敛。注意:作者给出的是在反向传播中使用转换连续块的数量的 batch 大小,每个包含 10 个转换,也就是图中 64k batch 实际上包含 640k 个转换。
多智能体竞争 VS 内在动机(intrinsic innovation)
在此项研究中,研究者证明了智能体可以在捉迷藏游戏中通过自监督 autocurriculum 学习复杂的策略和反策略。另一种以无监督方式学习技能的方法是内在动机,它激励智能体通过模型误差或状态计数等各种度量进行探索。研究者在构建的环境中进行了基于计数的探索,其中智能体对它们访问的状态进行明确计数,并在激励下前往很少访问的状态。
在当前设置下进行调整的主要建模选择是状态表征,比如在首个基线中,状态中只包含 2D 盒子位置,这样智能体在激励下与盒子进行交互并且将盒子推到新的位置。然后,研究者与基于计数的策略进行比较,这种基于计数的策略获取捉迷藏游戏中智能体获得的完整状态。
可以看出,在捉迷藏游戏中进行训练的智能体本质上是围绕人类可解释性更强的行为,如搭建堡垒等。但是,接受内在激励训练的智能体却似乎以一种无明确方向的方式移动物体。此外,随着状态空间复杂度的增加,研究者发现内在奖励方法与环境中物体的有意义交互越来越少。因此,研究者相信,随着环境大小和复杂度的增加,多智能体竞争将会是一种更加可扩展的类人技能无监督生成方法。
在上文中,研究者对捉迷藏游戏中学习的行为与利用内在动机学习的行为进行了定性对比。但是,随着环境规模的扩大,对游戏进程展开定性衡量也变得越来越困难。在多智能体设置中追踪奖励作为评价指标是不够的,因为这项指标无法确切地说明智能体在均衡改进还是陷入了停滞。
ELO 或 Tureskill 等度量指标能够更可靠地衡量性能相较于之前的策略版本或其他策略是否实现了提升。但是,这些度量指标依然无法揭示性能的提升是得益于新的适应性还是之前学到的技能。最后,使用目标运动等特定环境下的统计数据也具有不确定性(比如,追踪绝对运动并不能明确指出智能体的运动方向),并且设计充分的度量指标将随着环境的扩大而变得更加困难,花费也更大。
研究者建议使用一套特定领域的智能测试,其目的在于衡量智能体最终可能获得的能力。迁移性能在这些设置中充当质量或技能表征的定量度量,并且研究者将迁移性能与基于计数探索的预训练和从头训练的基线进行比较。
尽管捉迷藏智能体在很多迁移任务上表现的更好,但性能或收敛时间并没有显著提升。通过观察智能体在捉迷藏游戏中的表现,研究者知道它们具有准确移动物体和搭建堡垒的潜能。但在接受少样本训练时,智能体并不能在其他场景中利用这种能力。
研究者认为,混合迁移结果的原因在于智能体学习的技能表征是混乱且难以微调的。随着未来环境变得更加多样化以及智能体必须在更多场景下使用技能,他们相信将来会基于这种评价方法出现更泛化的技能表征和更有效的信号。此外,研究者还开源了评估任务,用来评估捉迷藏环境中的学习进程。
研究者已经证明,智能体能够在高保真物理模拟器中学习使用复杂工具,但在这一过程中,它们也吸取了一些教训。构建环境非常不容易,而且智能体经常以一种人类始料未及的方式探索环境:
借助盒子滑行:由于智能体可以通过自己施力来移动,他们可以抓住一个盒子并站在盒子上滑行至隐藏者的位置;
不停地奔跑:在不给离开游戏区域的智能体添加任何额外奖励的情况下,在极少数情况下,隐藏着会学习待着一个盒子不停地奔跑;
利用斜坡(隐藏方):强化学习非常擅长利用一些小的技巧。隐藏方发现,如果它们把坡道推到墙脚处,坡道会莫名穿过墙壁然后消失;
利用斜坡(搜索方):搜索方发现,如果它们在有斜坡的墙上以正确的角度奔跑,则能飞起来。
![]()
研究者表示,这些「作弊行为」揭示了算法安全性在机器学习中的重要作用。「在问题出现之前你是预料不到的。这类系统总是存在缺陷。」「我们能做的基本就是观察,并将策略可视化,这样我们就会看到奇怪的事情发生。然后我们再尝试修复这些物理问题。」
当然,这些意料之外的策略也让我们看到了解决问题的其他思路。「如果你将这些智能体放进一个足够丰富的环境中,而它们又表现出了人类未知的策略,也许它们能为我们提供新的解决方案,」论文作者说道。
微软 AI 研究员 Katja Hofman 表示,「我发现游戏或类似游戏中的这种设置是探索一个安全环境中现有方法能力和局限性的一种极好方式。这些结果可以帮助我们更好地理解如何验证和调试机器学习系统,这是通往现实世界应用的关键一步。」
参考链接:
https://openai.com/blog/emergent-tool-use/
https://spectrum.ieee.org/tech-talk/robotics/artificial-intelligence/ai-agents-startle-researchers-with-unexpected-strategies-in-hideandseek
https://syncedreview.com/2019/09/17/why-playing-hide-and-seek-could-lead-ai-to-humanlike-intelligence/
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com