少即是多?非参数语言模型,68页ppt
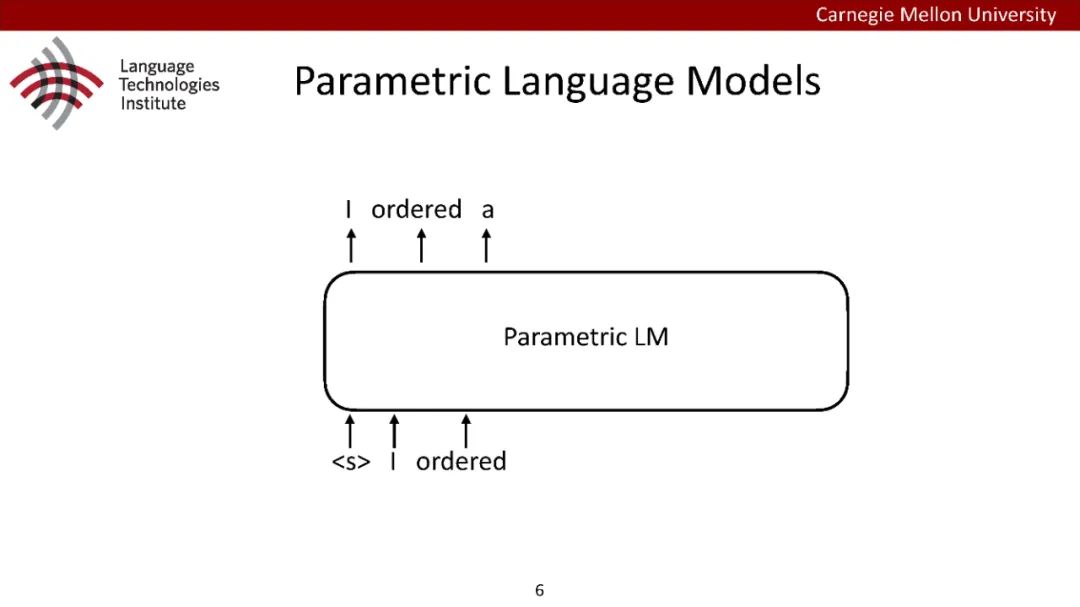
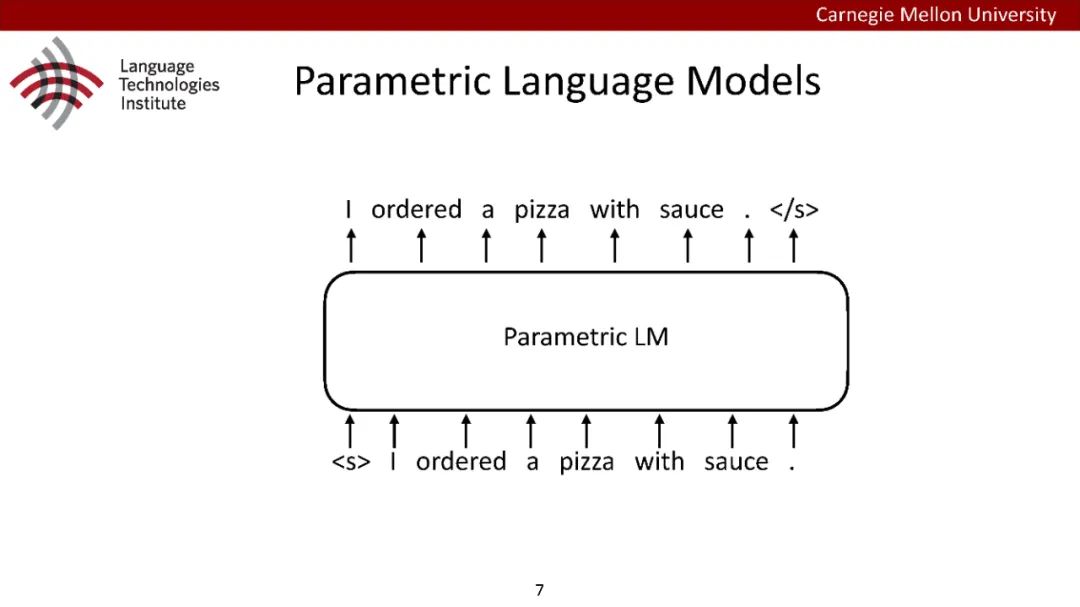
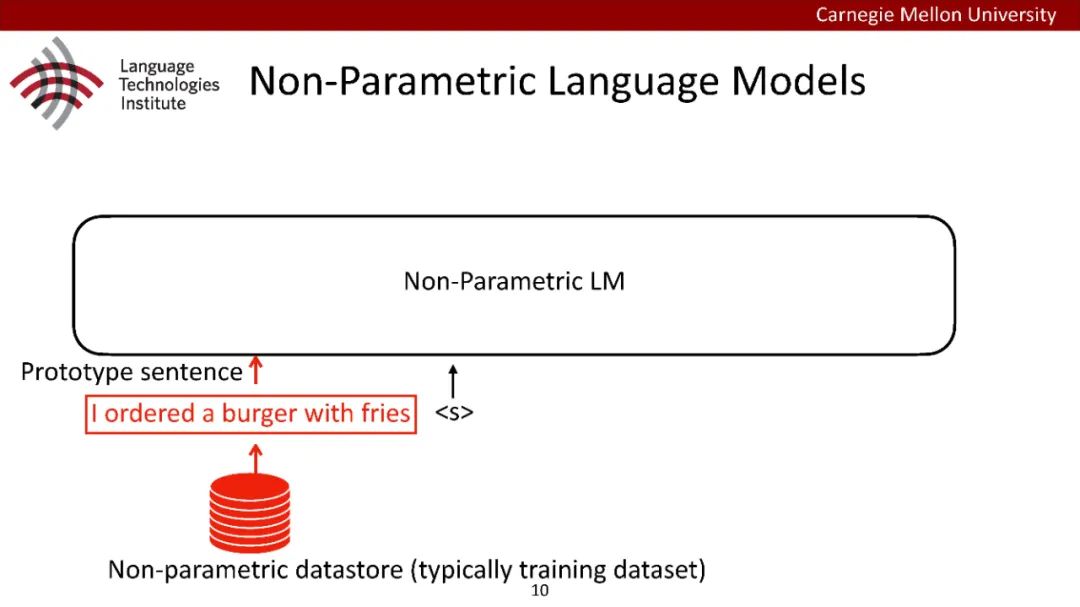
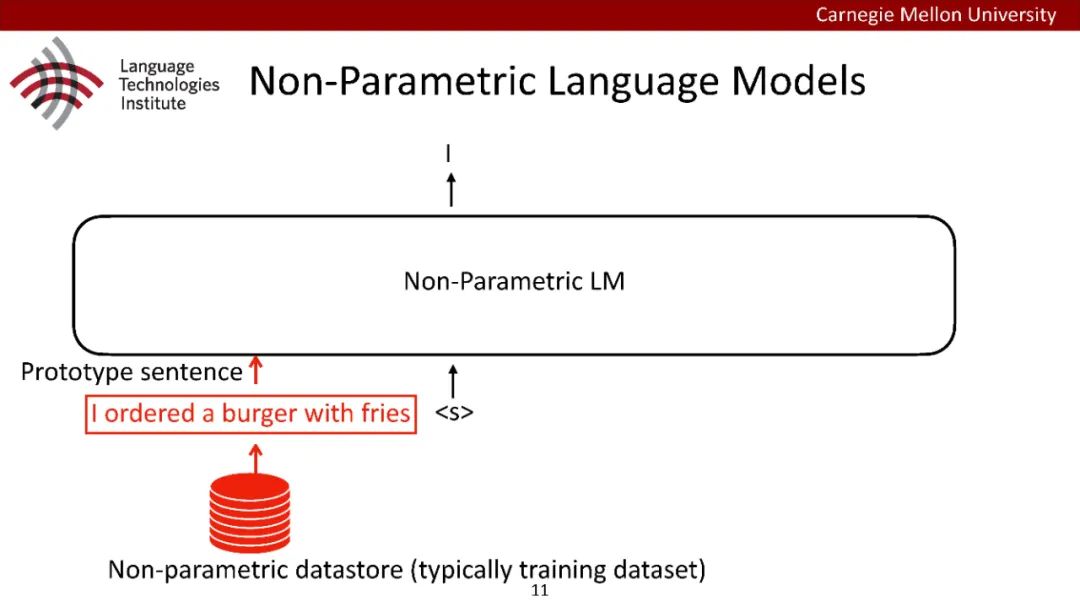
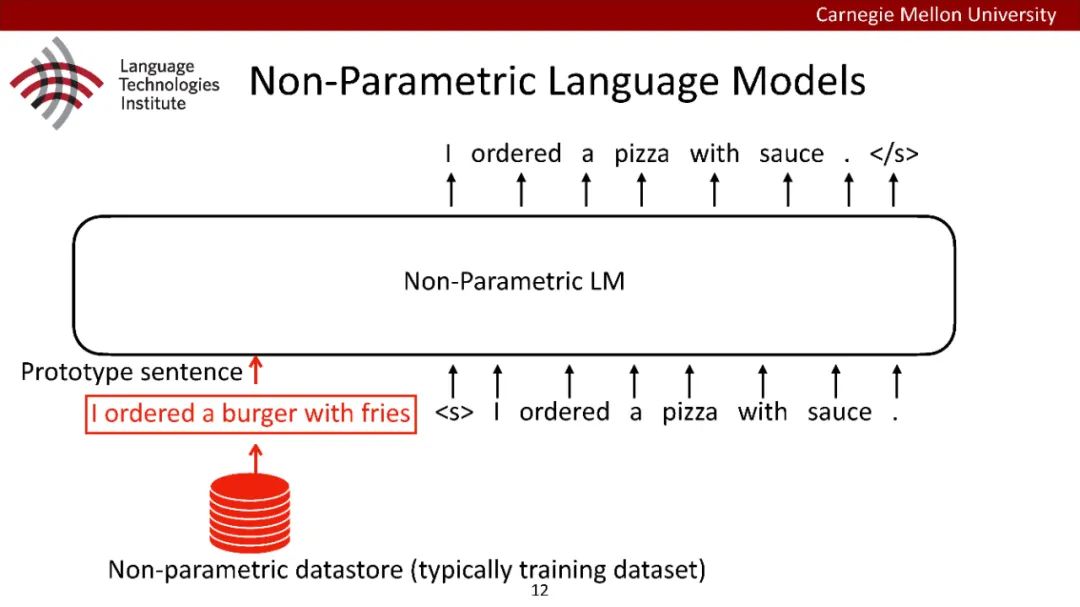
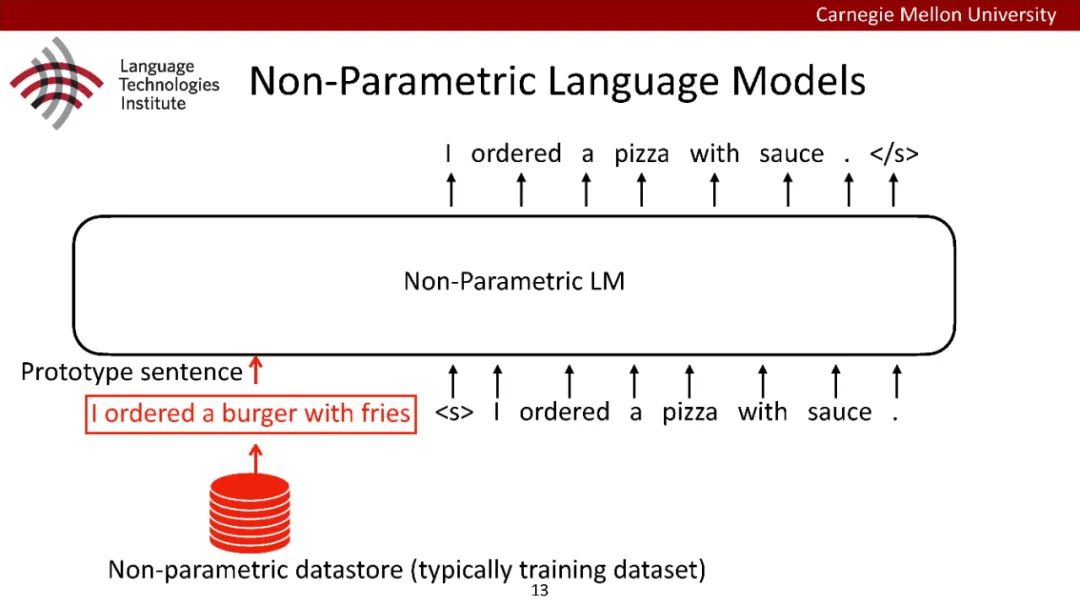
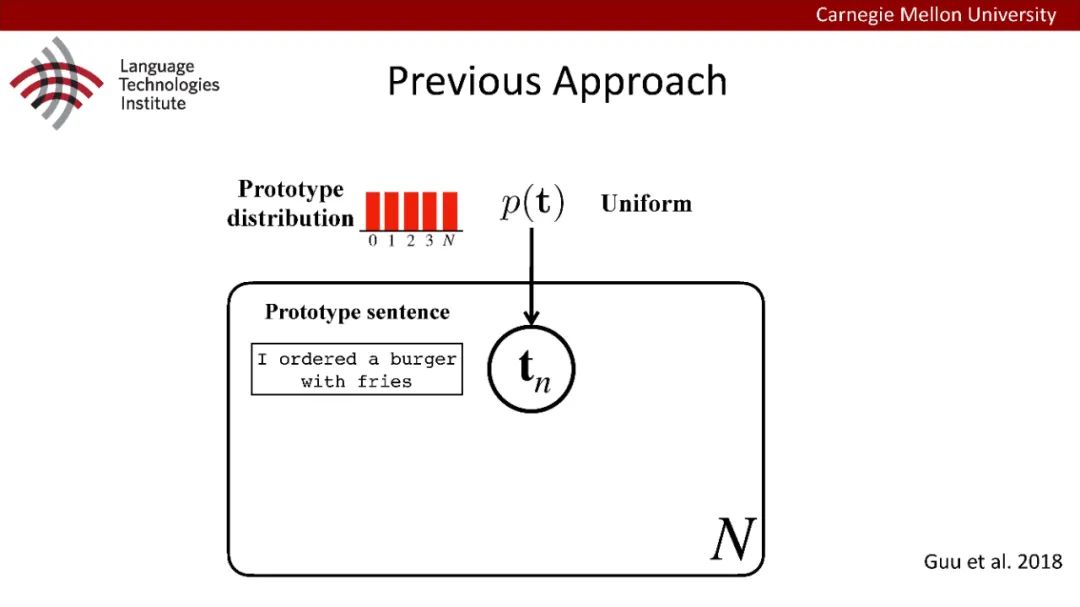
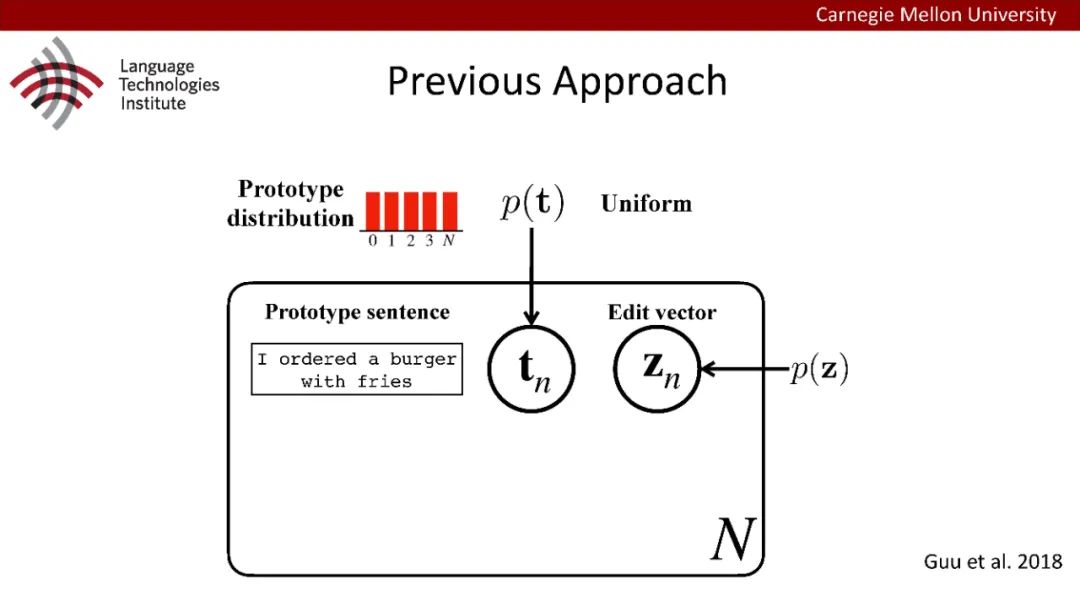
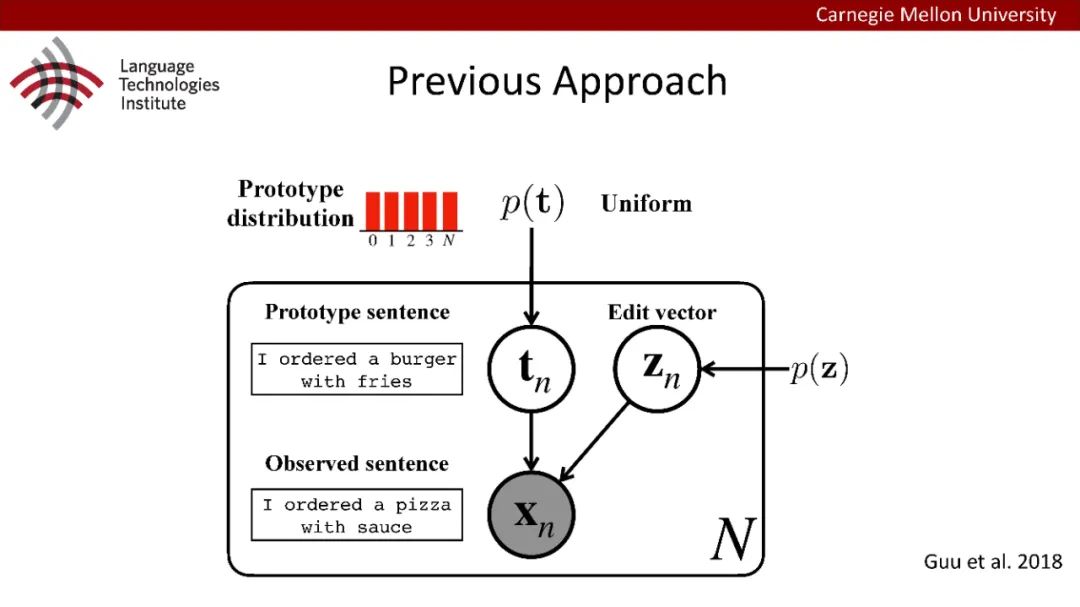
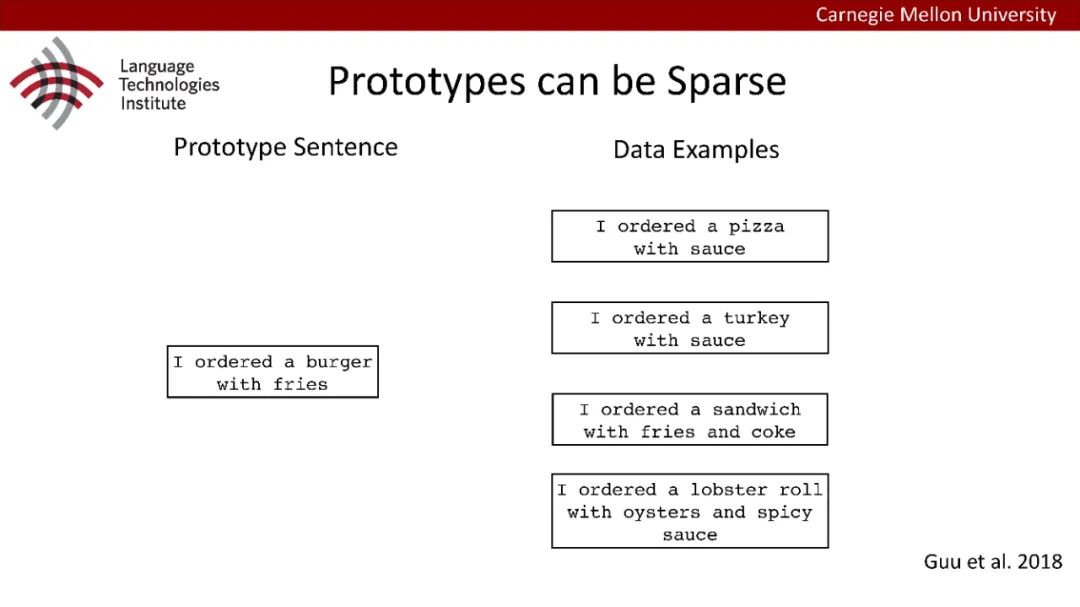
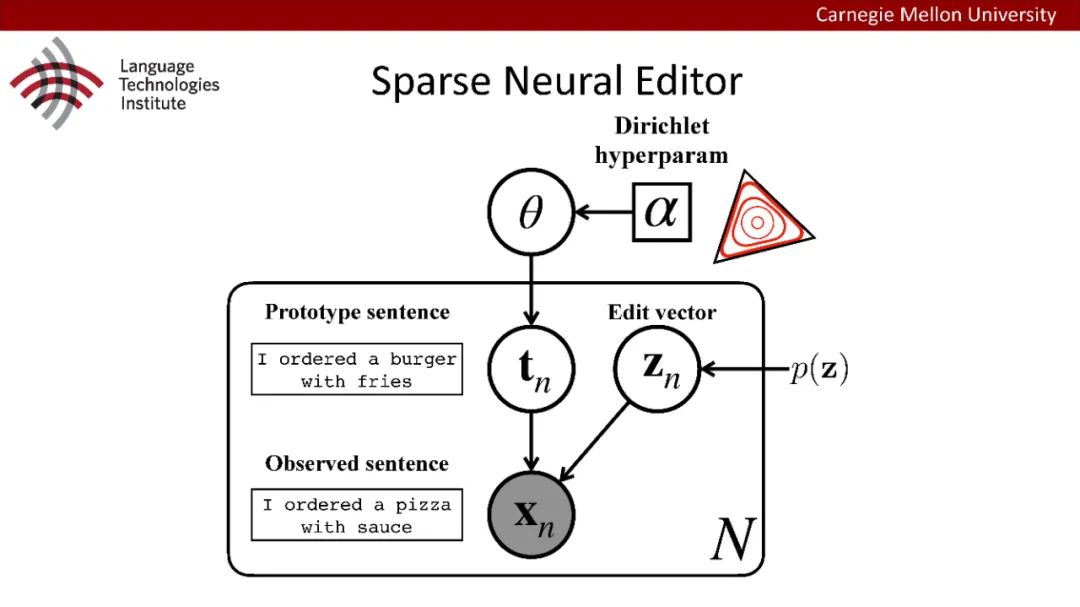
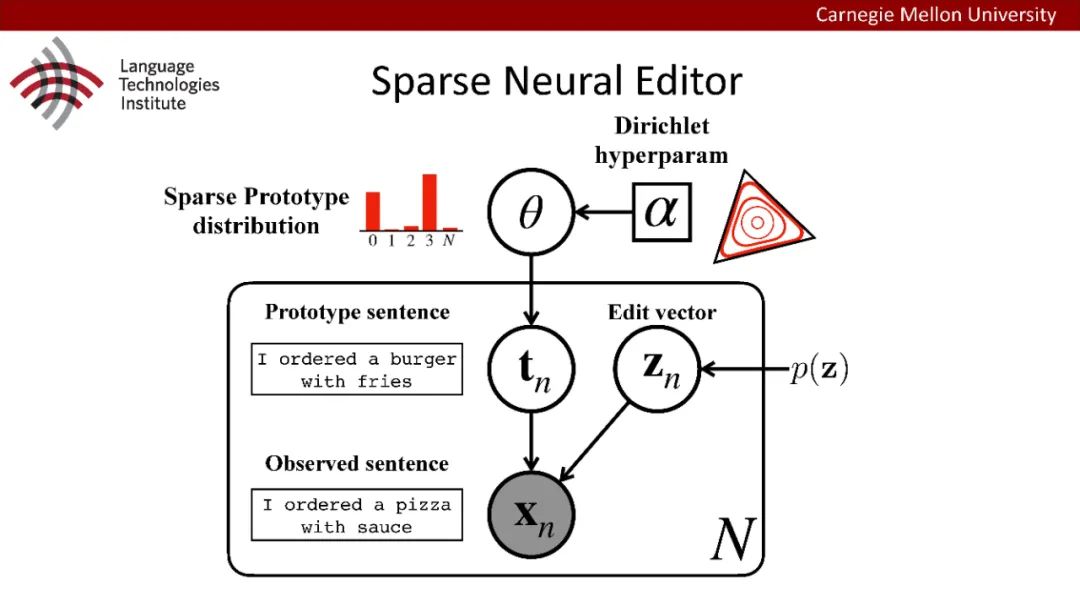
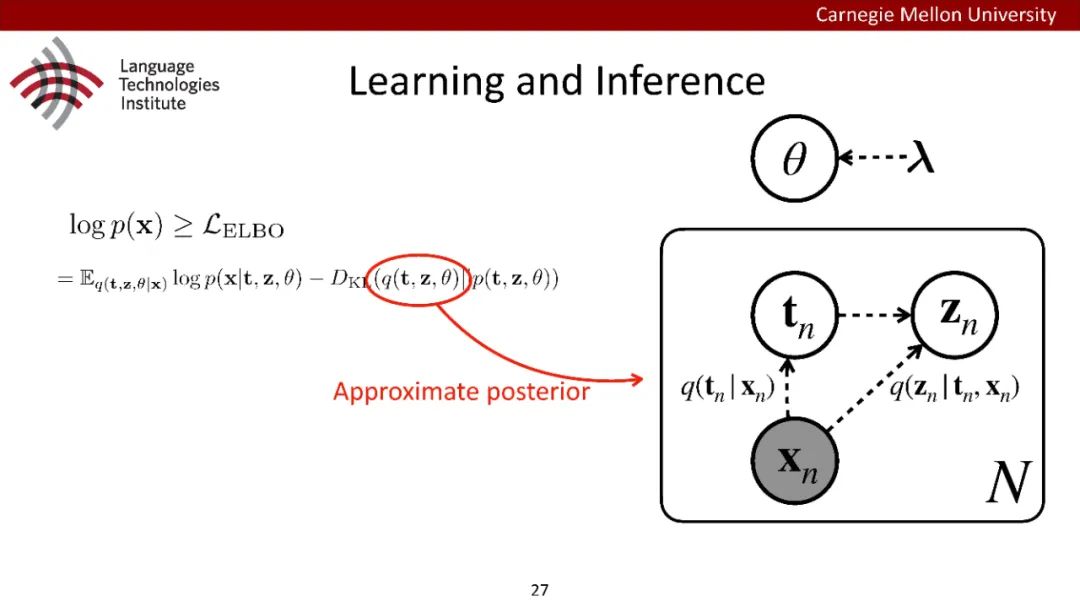
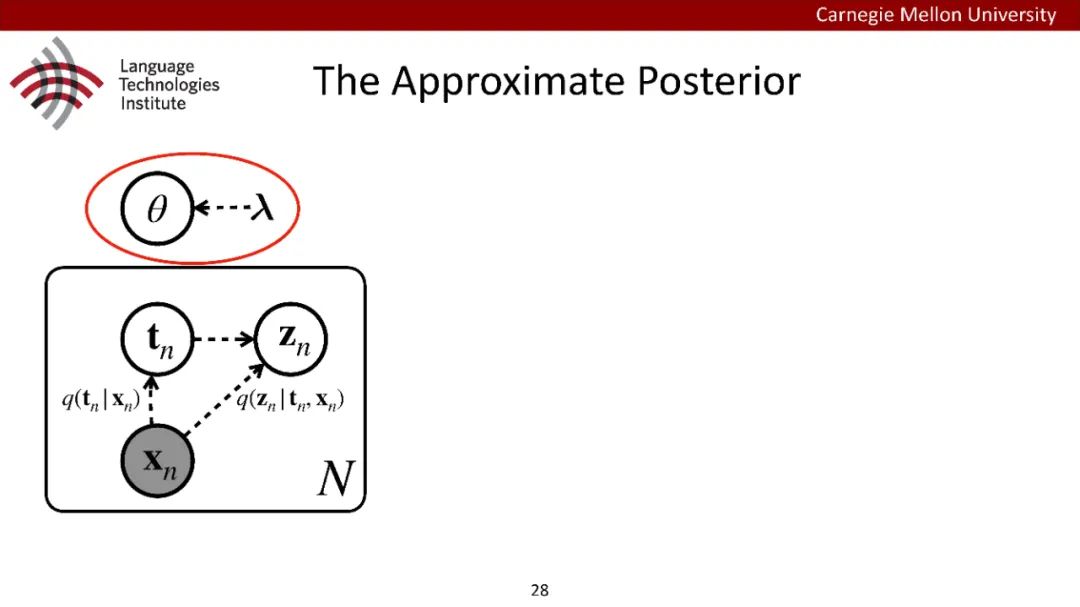
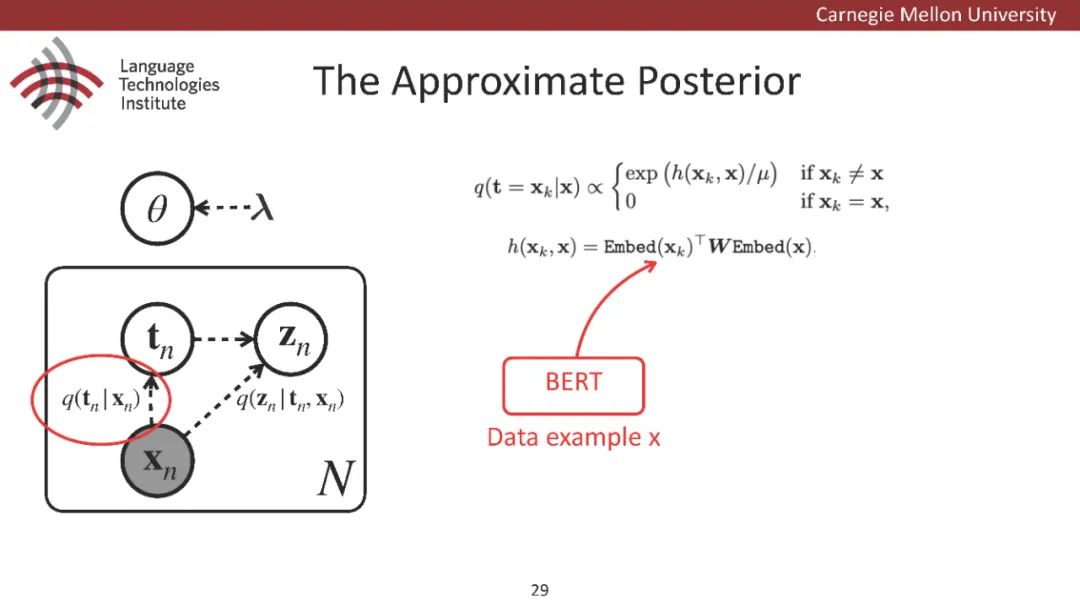
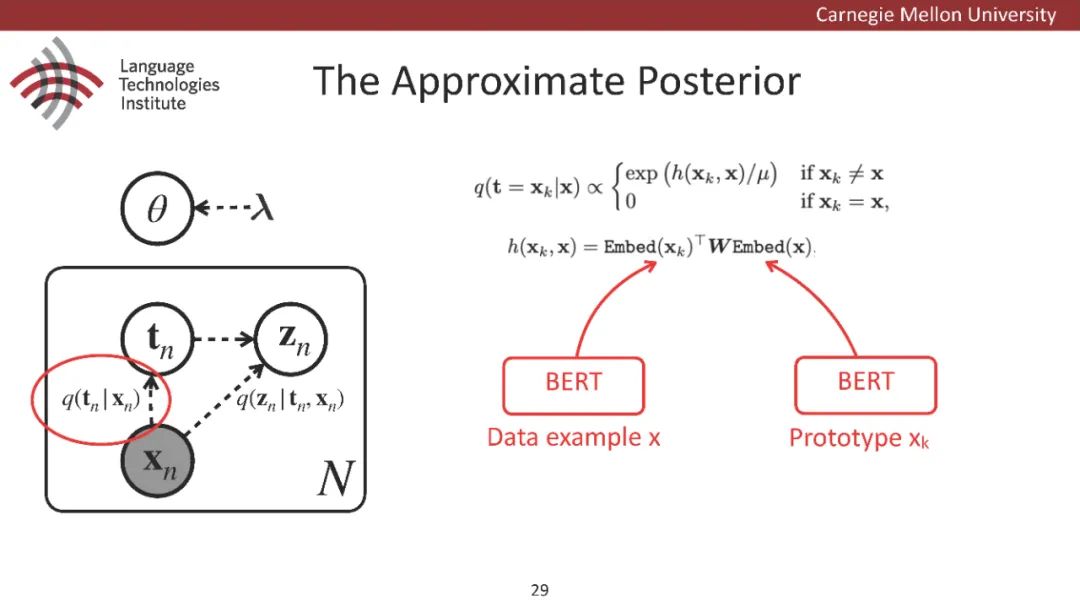
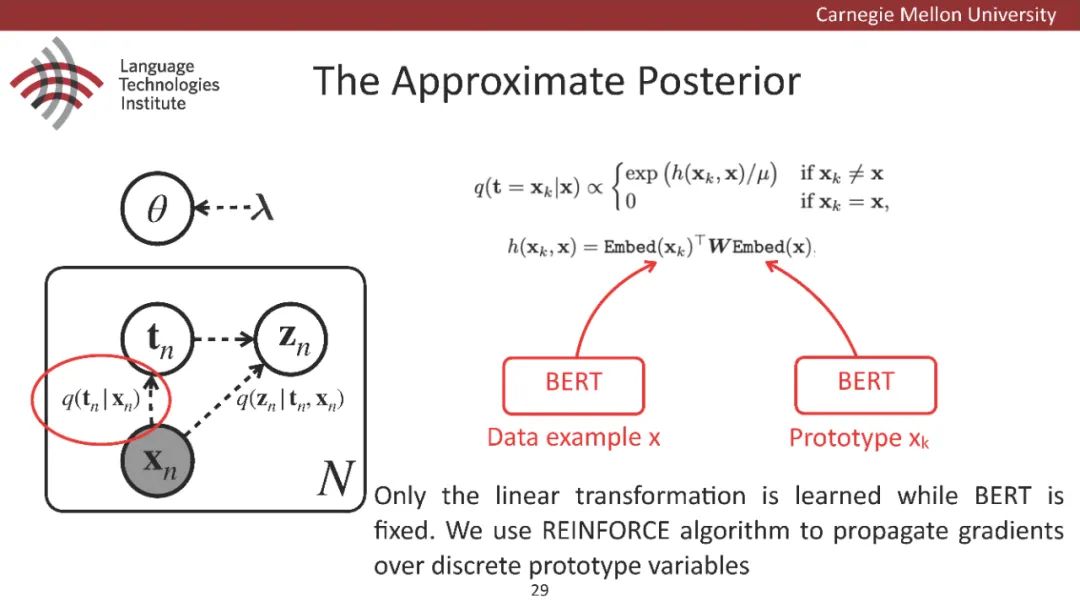
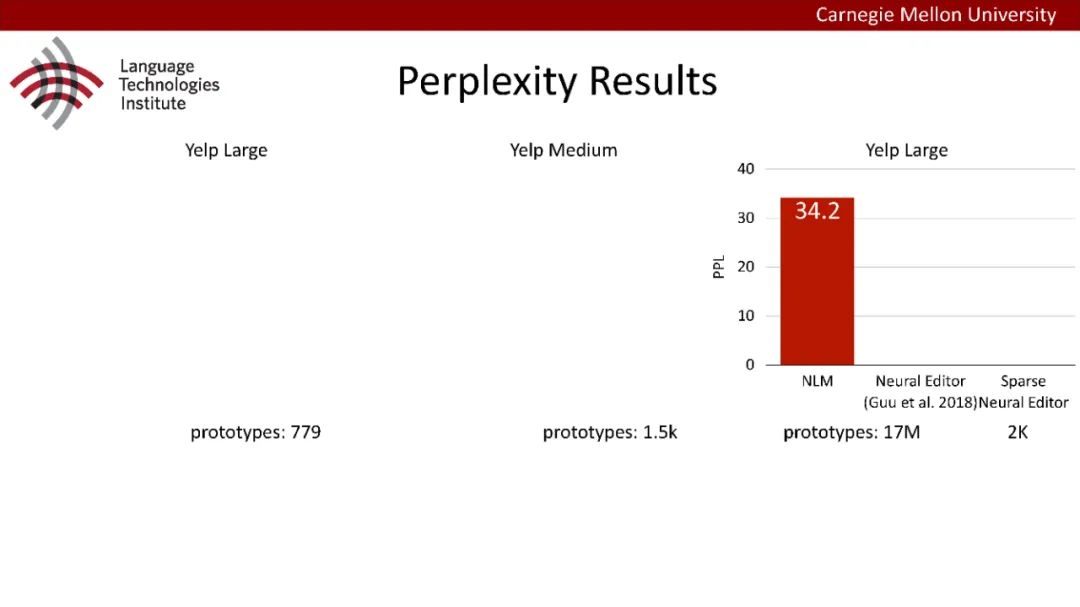
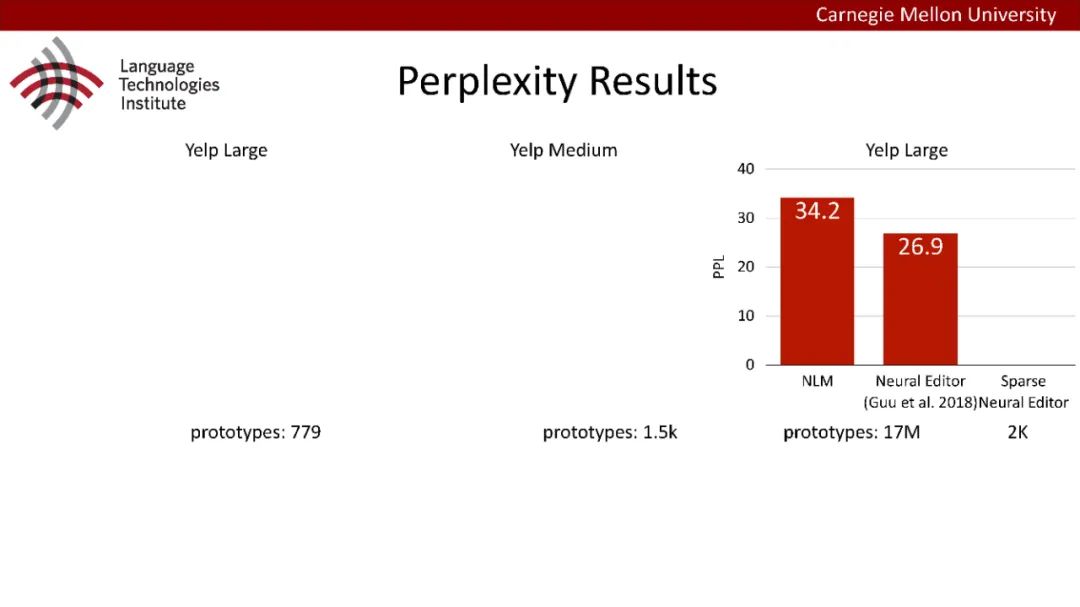
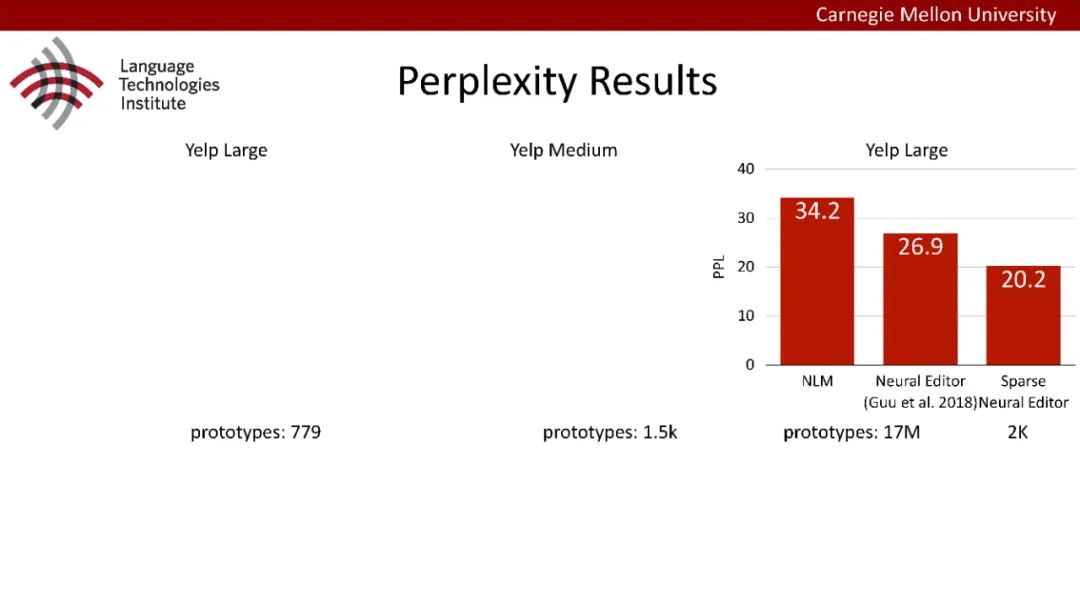
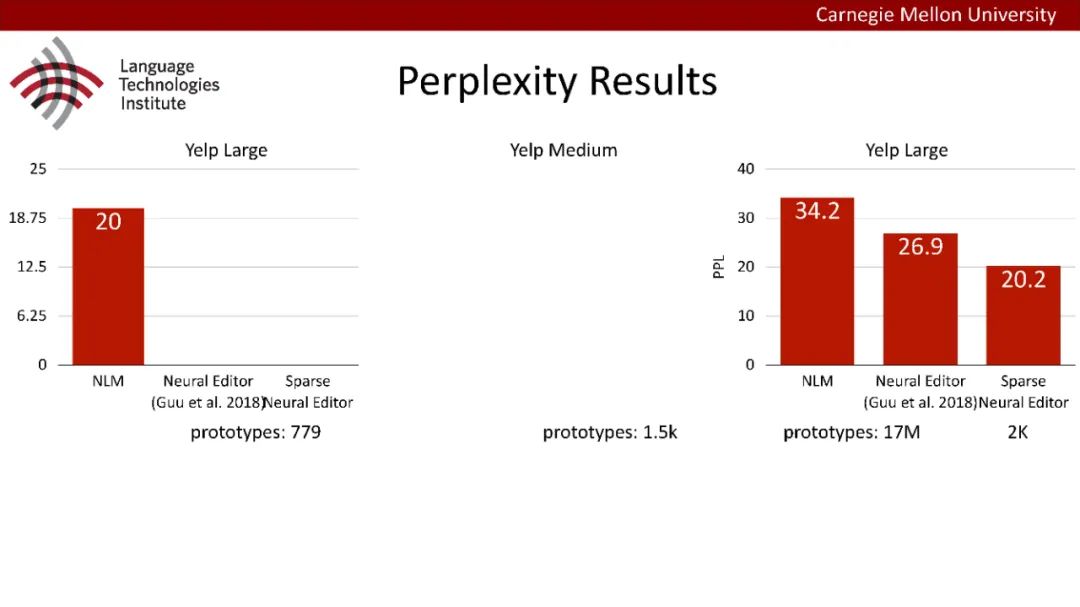
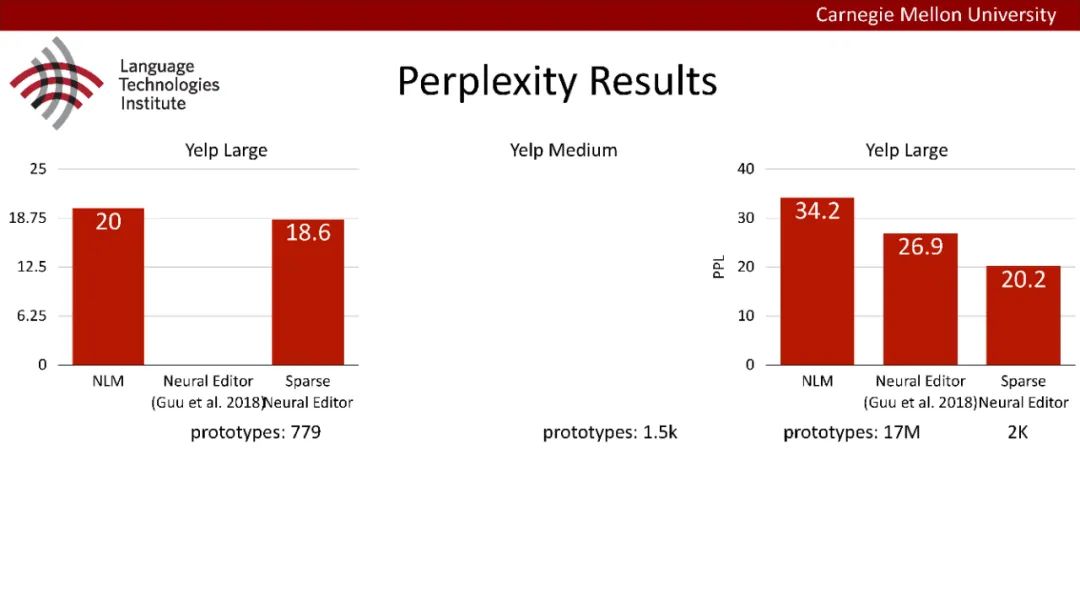
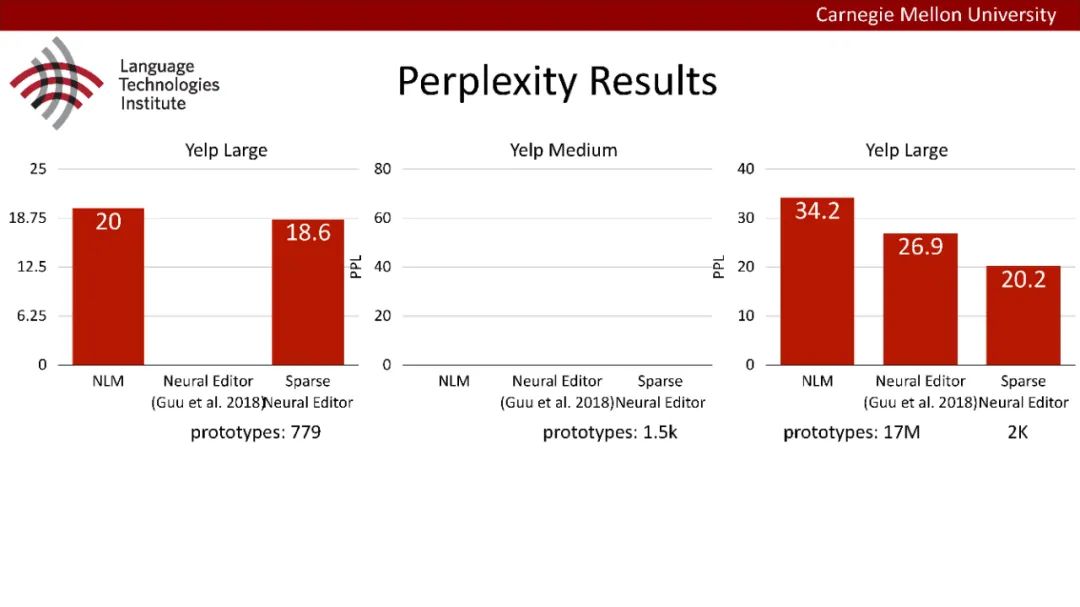
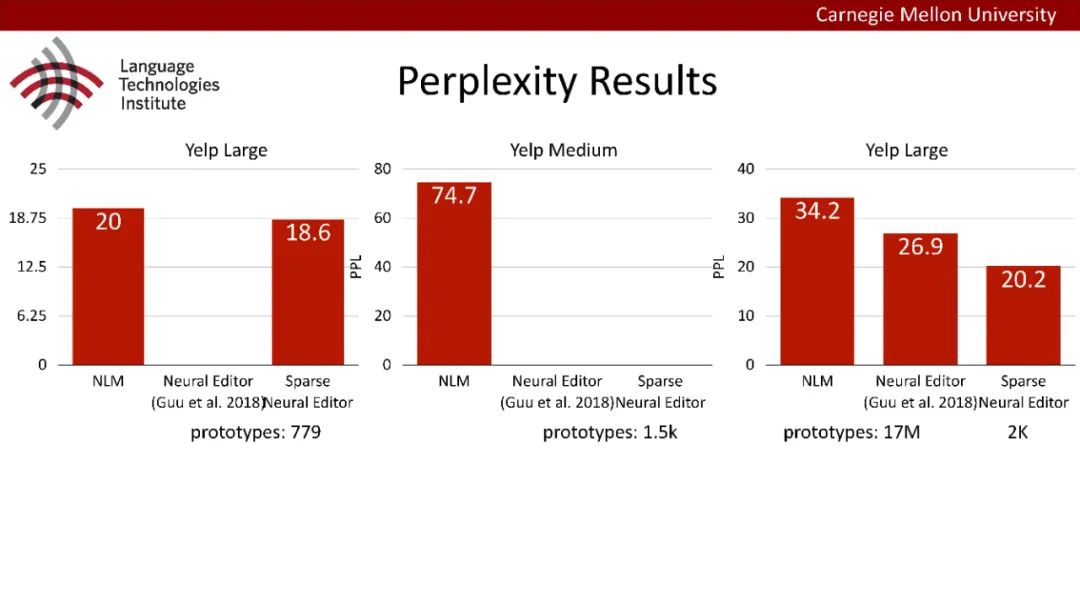
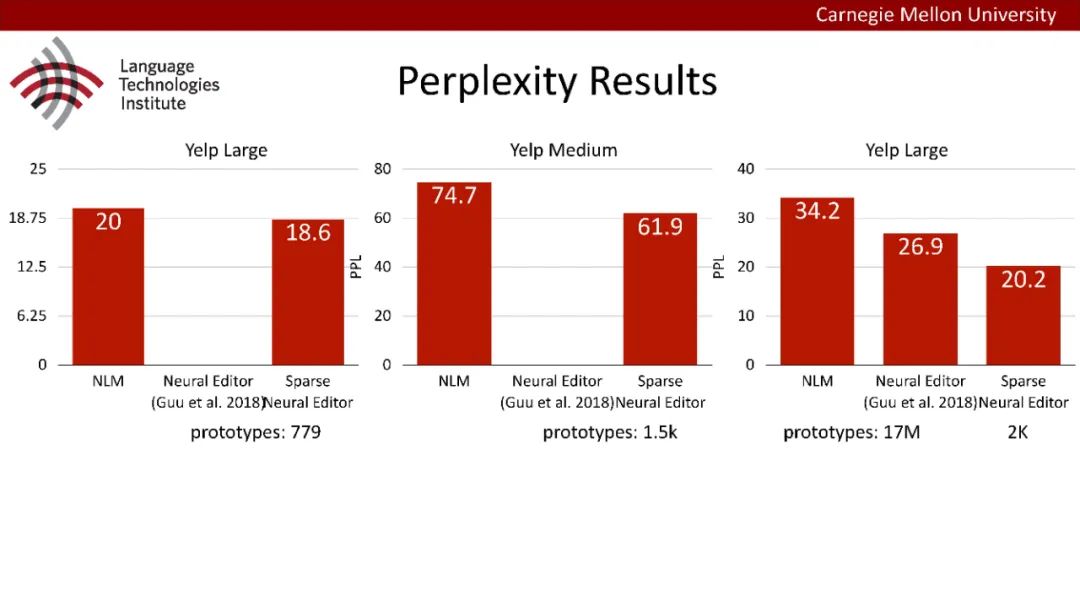
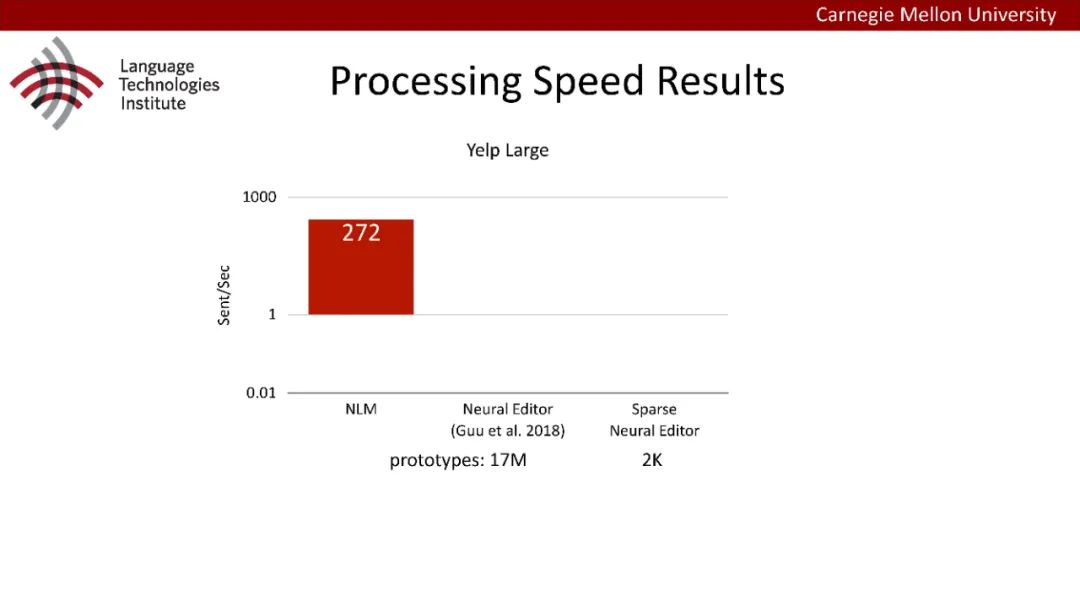
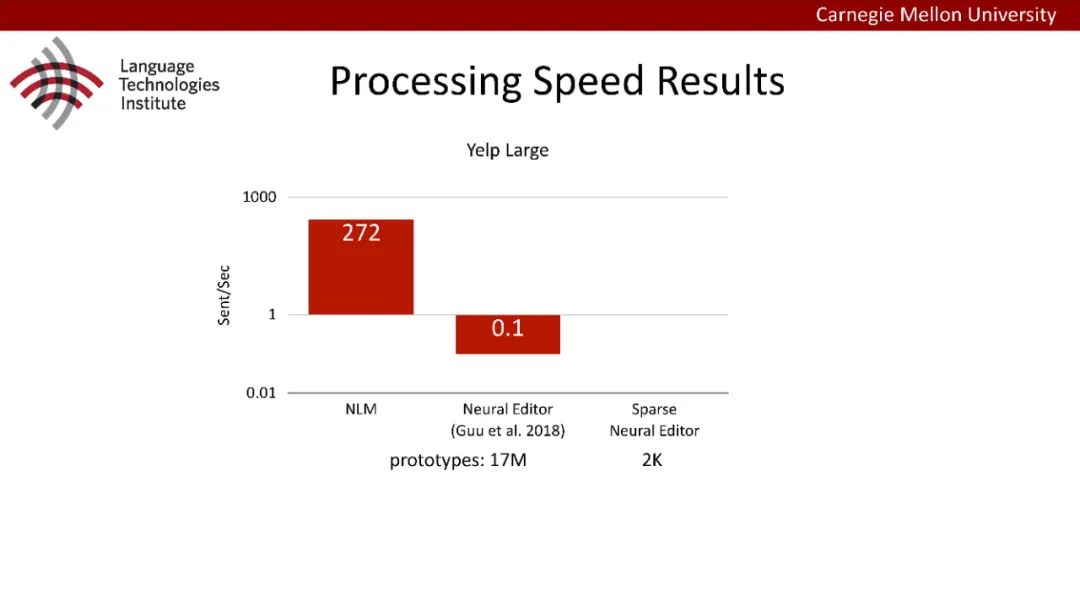
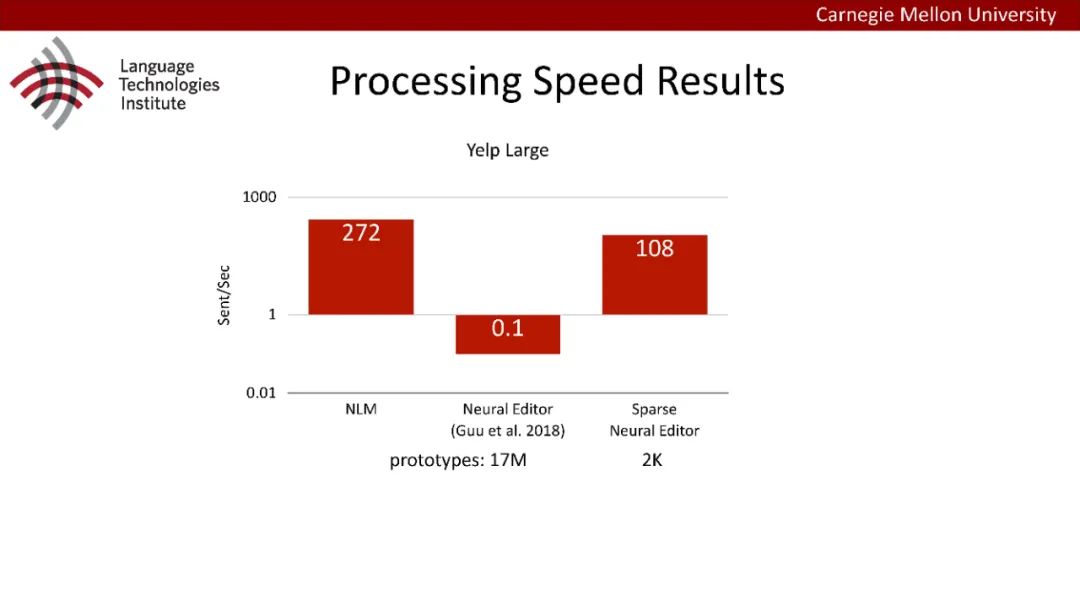
原型驱动的文本生成使用非参数模型,该模型首先从句子库中选择“原型”,然后修改原型生成输出文本。这些方法虽然有效,但测试时效率低下,因为需要对整个训练语料库进行存储和索引。此外,现有的方法通常需要启发式来确定在训练时引用哪个原型。在本文中,我们提出了一种新的生成模型,它可以自动学习稀疏原型支持集,同时也可以获得较强的语言建模性能。通过(1)在原型选择分布上施加稀疏诱导先验,(2)利用平摊变分推理学习原型检索函数来实现。在实验中,我们的模型优于以前的原型驱动的语言模型,同时实现了高达1000倍的内存减少,以及测试时1000倍的加速。更有趣的是,当我们改变原型选择的稀疏性时,我们展示了学习的原型能够在不同的粒度捕获语义和语法,并且可以通过指定生成的原型来控制某些句子属性。
https://arxiv.org/abs/2006.16336





































专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NPLM” 就可以获取《少即是多?非参数语言模型,68页ppt》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2021年1月26日
Arxiv
0+阅读 · 2021年1月25日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月26日
Arxiv
0+阅读 · 2021年1月25日