案例分享 | TensorFlow 助力网易严选供应链需求预测(系列之四)
文 / 王迪,高级算法工程师

前言
网易严选作为自营品牌电商,供应链决策是最重要、最广泛的业务场景之一,每一个决策的制定,都能给公司的营收、成本等核心指标带来直接的影响。而需求预测几乎贯穿了所有的供应链决策场景,准确的需求预测能为全链路都带来可观的收益,其价值不言而喻。
在传统行业中,做准需求预测往往需要长期的数据积累,而网易严选成立至今不足五年,并且品类仍在不断发展,商品迭代节奏很快,很多商品的售卖历史数据并不充分。于此同时,作为一家电商,花样繁多的促销、引流手段为用户带来更丰富购物体验的同时,也给数据带来大量的不确定性,增加了需求预测的复杂度。
图 1 网易严选 APP 首页
在这样的业务场景下,传统的需求预测方法存在太多的局限性。我们经历了长期的理论与实践的探索,通过全面拥抱深度学习与 TensorFlow,沉淀出了一套适合电商场景的通用预测体系,解决了多种供应链需求预测问题,并应用到了网易严选的采购、调拨、营销等多个业务环节当中,取得了较好效果,充分体现了算法赋能所带来的巨大业务价值。
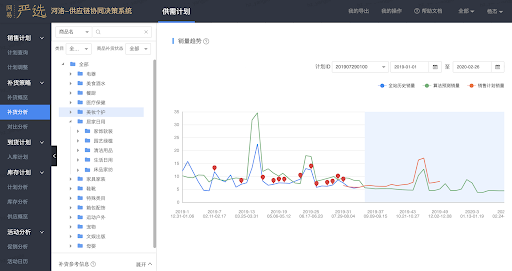
图 2 网易严选的供应链协同决策系统
此外,得益于深度学习与 TensorFlow 极强的技术拓展性,结合学术界的前沿研究,我们对自动化、智能化的供应链决策进行了初步探索,进一步挖掘人工智能的无限可能性。
通用预测赋能供应链决策
网易严选的供应链决策场景非常丰富,不同的业务场景都有着不同表现形式的需求预测问题。我们梳理了各种业务场景,将其中的需求预测问题进行梳理,转化为对应的算法问题:
采购补货 —— 指定时间范围里某件商品的需求量?——(天、SKU)粒度销量预测
仓间调拨 —— 指定时间范围、指定地域的商品需求量?——(天、SKU、省份)粒度销量预测
活动毛利预估 —— 指定活动条件下总体的毛利(可根据销量与售价转化)水平?——(天、SKU)粒度销量预测,并额外指定活动条件(折扣、流量)
仓配人力分配 —— 指定时间范围、指定地域的出库单量(可根据销量转化)?——(天、省份)粒度销量预测
…………
可以发现,大部分业务场景下的需求预测问题都可以转化为“特定条件下的商品销量预测”问题。因此,我们结合业务,对预测问题进行标准化的定义(时间粒度、商品粒度、可用特征……),使其转变为一些较为通用的预测问题。
使预测问题的通用化,可以大大提升开发效率,使相关的功能模块高度复用,同时也能更好的解耦算法与业务,具有更好的横向拓展性。
结合实际业务场景与技术基建,我们打造了一套核心预测引擎,提供了解决通用预测问题的基本算法能力。预测引擎主要包括特征池服务与模型层两个部分,TensorFlow 在开发过程中起到了至关重要的作用——不仅是模型层的基础与核心,更在特征池中也发挥了重要的作用。
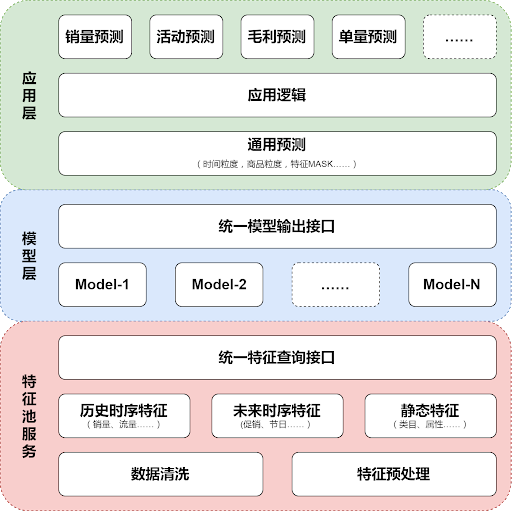
图3 核心预测引擎架构
纵观网易严选的所有需求预测场景,大部分预测问题总是围绕商品的销量、流量、活动等基本要素展开,这些数据作为特征,在不同的预测问题中被大量的复用。我们基于 Redis+Elasticsearch 构造了一套具有良好实时性、并发性的特征池服务。同时借助于 TensorFlow,特征的预处理部分也引入了 embedding、MCMC 等模型思想,在实际预测中起到了重要作用。
-
静态特征:
静态的,不随时间发生变化的特征,如商品 ID、类目关系、定价、季节性、属性标签等 -
历史时序特征:
描述历史事实的,与时间有关的特征,如商品历史每天的销量、流量、折扣等 -
未来时序特征:
描述未来事件的,与时间有关的特征,如商品未来的活动计划、上新计划、未来节假日等
我们把所有预测场景中用到的基础特征,从数据仓库、业务系统后台、底层日志等各种位置抽取汇总,统一存储在特征池当中。
-
商品建模 目前,网易严选在架售卖的 SKU 已有数万件,涵盖了上百个不同的品类。不同商品之间的关联关系对于需求预测是非常重要的输入特征,特别数据较少的新品,必须“借用”类似商品的历史数据才能产生较为合理的推断。为了能找出不同商品之间潜在的联系,除了业务最基础的商品多层级类目关系特征,我们对商品进行了额外的一次建模。 如下图所示,我们采用了类似于 word embeddings 的思想,对不同的商品 ID、类目 ID 进行了 embeddings 操作。计算时除了销量数据,还会重点考虑用户行为数据,包括加购、访问、搜索等多种维度。所有的 embeddings 建模均通过 TensorFlow 来实现,大大节约开发成本,提升了效率。与基本特征类似, embeddings 特征离线生成,定期更新,存储在核心特征池当中供算法模型实时取用。
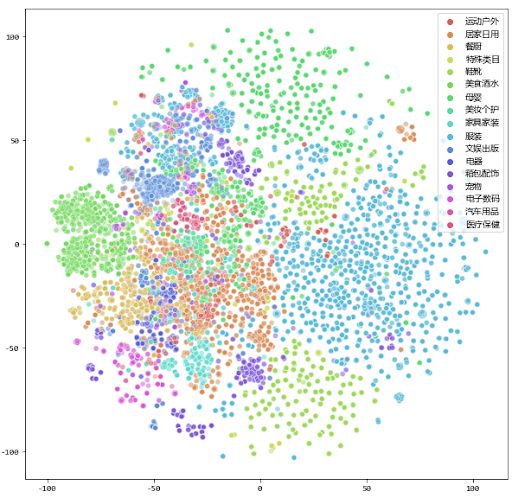
图 4 严选商品 embeddings
-
事件建模 真实的需求、销量总是充满了波动的。大部分情况下,波动总是伴随着一些特殊“事件”的发生而产生,例如特定的促销策略、特定的活动宣传等等。事件考虑不充分是造成预测不准的最普遍因素。而网易严选作为电商公司,其促销活动的玩法、策略比传统行业更加丰富多样,频率也更高,“事件”对需求预测带来的影响也就更加显著。 我们从流量、折扣、时间等基本维度出发,基于业务策略,设计了一套标准化的事件体系,对于在严选场景下发生的各种事件转化为标准的字段,作为时序特征的重要补充。
图 5 截取自严选 Web 端首页
-
季节性建模 商品季节性也是在需求预测重点考虑的因素之一。季节性对销量产生的影响是以年为周期的,也就意味着对于售卖不足一年的商品而言,并不能完整的推测出全年季节性影响趋势。另一方面,许多商品在非应季时直接是下架停售,这样也会导致商品历史数据不完整,给预测带来干扰。 为了做好季节性商品的预测,我们基于马尔可夫链蒙特卡罗方法(MCMC),设计了一套具有一定先验假设的概率模型,可以从小样本量数据中推算出全年完整的季节性趋势变化。而这样的概率分布模型,同样可以基于 TensorFlow Probability 提供的丰富 API 来实现。通过模型计算得到的全年每一天的季节性因子,作为时序特征的重要补充。
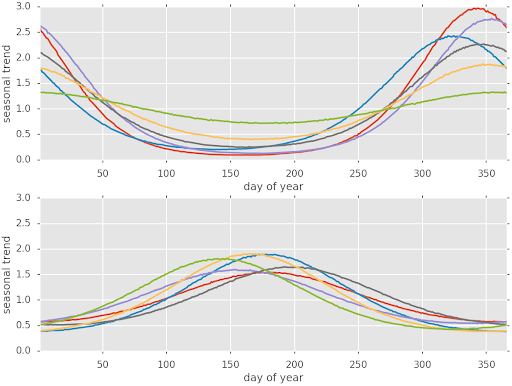
图 6 小数据集下学习到的冬季(上)夏季(下)商品季节性趋势(每根曲线代表一件商品)
-
多场景多模型:根据实际的预测场景,不同场景选取不同的模型,或是专门定制算法模型 单场景多模型:即使对相同的预测场景,其中的不同基本单元(如商品销量预测时以商品为基本单元)可能呈现不同的数据规律,因此对同场景下不同单元使用不同的模型(经验证这种方法能得到远超单一模型的预测效果)
-
无法考虑不同商品之间关联关系(大都是“单一时间序列”预测模型) -
无法考虑额外特征(如额外的活动计划等) 对历史数据质量有要求(要有足够的长度来拟合,不能有异常值、缺失值等)
如果在严选场景下使用这些传统统计模型,需要增加大量的额外的人工逻辑来弥补上述不足,无论是预测效果还是可拓展性都不理想。而使用机器学习类算法,从样本点——特征的角度去对预测问题建模,能很好的解决上述问题。
-
自回归式 RNN: RNN 是一种广泛应用于序列类数据的网络结构,而“自回归式”的核心思想是:对于t时刻预测的输出 zt,作为 t+1 时刻预测的输入,从而实现对未来多个时间步的预测 ,如下图所示:
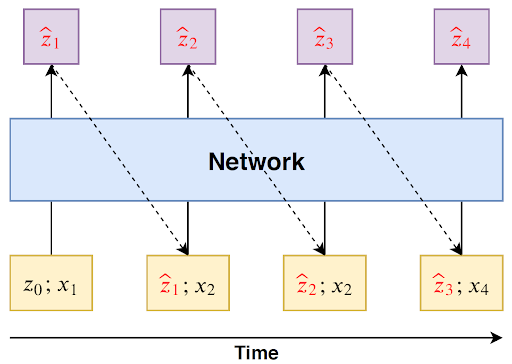
图 7 自回归式预测网络结构
其中,Network 的部分可以是单层或多层的基础 RNN、LSTM、GRU 等结构(经过实验比较,目前我们采用的是多层 LSTM 网络结构)。
-
Encoder-Decoder: Encoder-Decoder 是一种常用于 NLP 领域的网络结构。这种结构可以天然的把一个样本的数据拆分为历史、未来两个部分,如下所示。
预测可以分为两个步骤:Encoder 从 历史数据中学习一些基本知识(如平销状态下的平均销量值)并编码成特征向量,然后在 Decoder 中把编码历史特征(产生基础预估)与未来特征(对基础预估进行修正)相结合,产生最终的预测结果。 Encoder 与 Decoder 中使用的网络结构同样是可以灵活选择的。我们参考一些主流算法,使用了 StackedLSTM、BiLSTM 等 RNN 类结构,并且引入了 Attention 机制,加强了对历史数据的长程依赖,取得了不错的预测效果。
此外,我们也尝试了 CNN 类的网络结构 —— 基于 WaveNet 中的 Dilated Casual Convolutions 结构作为 Encoder,同样能得到不错的长程视野,并且相较于 RNN,在计算效率上有极大的提升。Encoder-Decoder 网络结构实现的是真正的 T+n 预测,可以有效避免误差堆积,并且可用特征的选择范围更加广泛(无需“贯穿始终”)。但是这种模型对未来的预测长度是固定的,复杂度也更高,需要更加定制化的开发,通用性较差。
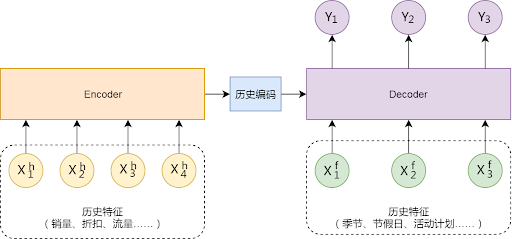
图 8 Encoder-Decoder 预测网络结构
无论是自回归式 RNN,还是 Encoder-Decoder,其内部具体网络结构都是灵活多变的,需要通过大量的实验来确定。我们基于 TensorFlow 进行开发,可以极大地提升开发效率,每种新的结构设计想法都可以快速地实现出来,并在实验中得以验证。
基于概率预测的智能决策探索
前文讨论的各种需求预测场景,总是基于一个确定的估计值(点估计)来进行下一步决策的。以商品的采购补货业务为例:首先预测出未来一段时间内的商品销量数值,然后根据当前的库存,考虑生产周期、到货周期、起订量等业务因素,推算出需要下单的采购量,这也是在业内被广泛的使用的一套流程。那么,这样的流程本身是否还有优化的空间?如何让算法在其中发挥更大的价值?带着这样的疑问,我们从从商品采购业务作为切入点,对于更加智能化、自动化的供应链决策系统展开了探索。
在前面描述的基于点估计的采购流程中,从预测值到采购量的转化是一个严密的、确定的过程,整个决策都是基于“预测是准确的”这一假设而做出的——如果预测是足够准确的,那这样的流程是最为直观和有效的,库存也一定能维持在预期的水位上。
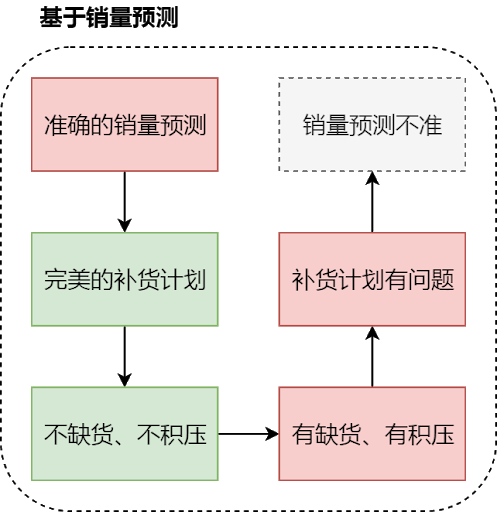
图 9 基于点估计的采购链路
看上去,只要一直提升准确率,就能够一直给采购业务带来优化,只要预测足够准,一切业务痛点都迎刃而解。但现实是,预测总是有偏差的,同样的业务约束下,不可能会有长期持续的、稳定的准确率提升。因此,提升需求预测准确率不是银子弹,必须在流程中考虑预测的不确定性。传统的做法当中,为了应对不确定性,往往是在计算采购量时考虑一些缓冲量。而我们从需求预测算法的角度,采用了另外一种思路:考虑不确定性的预测——用概率分布估计来替代点估计。
以销量预测为例。我们假设每一天的销量是服从某种概率分布的,传统的点估计给出的是每一天销量的期望,即“均值”。而概率分布预测不直接给出销量值,而是给出概率分布中的参数(如高斯分布中的 μ 和 σ,泊松分布中的 λ 等)。基于一个确定参数的概率分布,我们在得到销量“均值”的同时,还能计算出一个特定概率下的销量波动范围。而对于均值相同的两次销量预估,上下波动的范围可能是不同的,如下图所示:
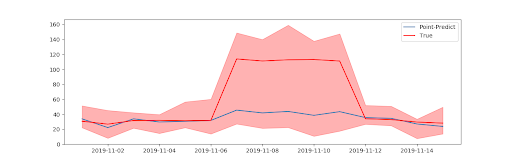
图10 点估计 vs 考虑不确定性的预测
如果只看点估计(蓝线),图中每一天的预估销量都是差不多的,“上下波动”范围的相关信息被丢失掉了,在不同日期上做出的决策(如采购量)也将基本保持稳定。
但如果从分布的角度来看,11 月 7 日 ~ 11 月 11 日的销量会有更大的不确定性(可能是受到特殊事件的影响),上界远高于其他日期。如果这件商品具有重要的意义,或者库存成本较低时,可以考虑适当的调高采购量来减少缺货。
得益于深度学习模型的层次结构,我们可以方便的把点估计模型改造成概率分布估计模型。
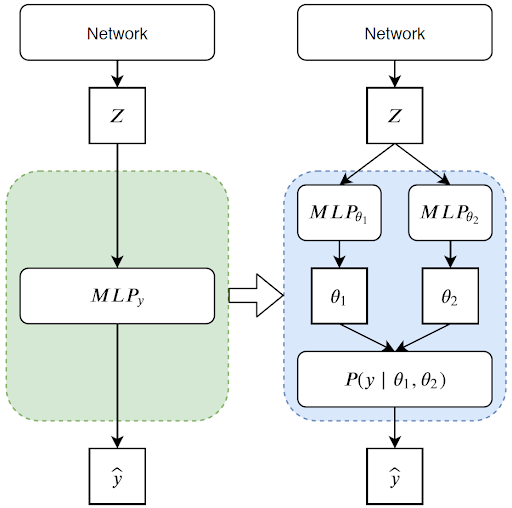
图 11 从点估计网络改变到概率分布预测
如上图所示,我们对输出层(一般会在隐层状态后接一个 MLP 结构)进行替换,为分布中的每一个参数设计专门的输出网络(例如 MLP),以最终的隐层状态作为输入,生成分布中的不同参数。除了结构上的修改,我们用最大似然函数构造新的 loss 函数,替代点估计的 loss 函数(常见的如MSE、MAE等)。所有的模型改造基于 TensorFlow,可以非常方便的实现。
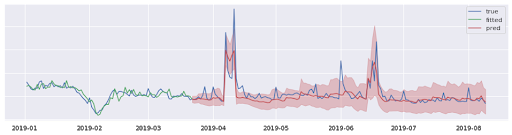
图 12 某类目真实销量数据 vs 概率分布预测效果
当预测从点估计拓展成概率分布估计后,意味着可以结合不同的业务约束与目标,从分布中采样一个更合适的预测结果来进行后续的决策。本质上,考虑不确定性并没有提升预测的准确率,而是让需求预测提供了更丰富的参考信息,为后续的决策过程提供优化的空间。以商品采购业务为例,对于重要性较低的商品,可以使用更保守的需求估计,腾出更多的资金空间用于重要性高的商品。从总体上来看,虽然总成本相近,但是库存的结构会更加合理。
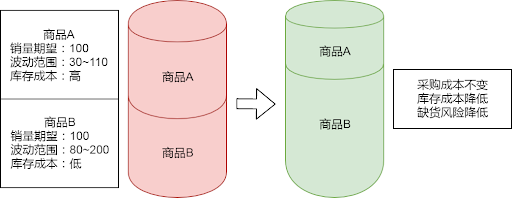
图 13 考虑不确定性的成本分配
我们通过“服务水平”指标来衡量商品的重要性,服务水平的计算是较为灵活的,可以综合考虑商品的采购成本、库存成本或者其他重要的业务指标,基于运筹优化中经典的“报童模型”进行计算。把考虑不确定性的需求预测和考虑服务水平的决策策略相结合,我们打造了一套以业务指标为目标,“端到端”的自动化采购解决方案,并且在实验中验证了方案的有效性,给业务带来一定优化效果的同时,大大的节约了人力。
总结
在网易严选,基于人工智能的需求预测作为各种供应链决策的基础,已经在众多业务场景里发挥了巨大的价值,而 TensorFlow 正是沟通这一切的桥梁。
最后,再次感谢 TensorFlow 对网易严选供应链,对人工智能领域的大力支持。未来,网易严选也将持续探索人工智能在供应链决策领域的应用,发掘 TensorFlow 更多的业务场景与价值,为自动化、智能化的供应链决策提供无限的可能性。
想加入案例分享?点击 “阅读原文”,填写相关信息,我们会尽快与你联系。
更多相关案例:





