大白话之《Shallow Updates Deep Reinforcement Learning》
Andrew ng曾讲过Deep Reinforcement Learning (DRL)是有前景的研究方向。近几年,顶级会议上发表了很多强化学习方面的论文,已成为各个应用领域的研究热点。本次介绍的论文《Shallow Updates Deep Reinforcement Learning》来自于NIPS 2017。
写在前面:
如果对强化学习的基本概念没有了解,可以参考 udacity两个逗比老师的免费教程。
可以参考DeepMind David Silver youtube上的课程。
关于教材,墙裂推荐《Reinforcement Learning: An Introduction》。
下面介绍一下论文《Shallow Updates Deep Reinforcement Learning》的干货:
强化学习的目标是学习值函数或策略以最大化收益。学习值函数或策略的方法,可以分为两类DRL和SRL,如下:
Deep Reinforecement Learning (DRL): 用深度神经网络来计算值函数或策略。
Shallow Reinforcement Learning (SRL): 用线性函数计算值函数或策略。
自1997年以来,研究人员在SRL类方法上发表了很多论文。SRL的优势是结果稳定(stable),需要的数据量比较少(data efficient)。但是,此类方法严重依赖特征的选择。选好特征,效果好。选不好特征,效果会很差。
随着表示学习的发展,研究人员意识到深度神经网络(如卷积神经网络CNN)可以同时学习特征和值函数,不必人工挑选特征,这是DRL的优势。但DRL的缺陷是训练的结果不够稳定(not stable)。
Motivation: 基于两类方法的优缺点,《Shallow Updates Deep Reinforcement Learning》提出结合SRL和DRL各自的优势,将shallow updates引入到DRL的最后一层,从而提升DRL的稳定性。实验结果表情,两类方法的结合有效提升了vanilla DQN和Double-DQN的表现。(vanilla DQN和Double-DQN是DRL的一种,其概念和原理将会在后续的文章详细介绍)。
Method: 论文提出的方法LS-DQN (Least Square Deep Q-Network),DRL是如何引入SRL的思想呢?
下面的图片是DRL,通过向Deep neural network输入游戏图片,产生相应的plicy。SRL引入的思想仅仅是在最后一个隐藏层上做了改变。
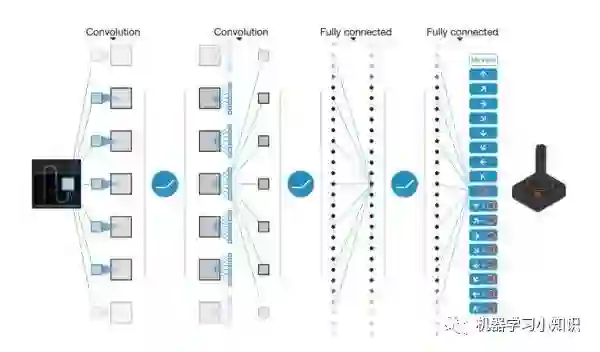
首先训练DRL网络,然后对DRL网络的最后一层,使用SRL方法重新训练。其本质是,用DRL学习输入的“新的表示”或“好特征”,然后用这些好特征,用线性函数优化最后一层,得到更好的参数。
说到这里,大家恍然大明白。传统的机器学习方法严重依赖特征选择,而表示学习、深度学习方法的优势是自动的特征“选择”。类似的KDD2017中,帅哥曹博凯的论文也是这个思想《DeepMood: Modeling Mobile Phone Typing Dynamics for Mood Detection》。
LS-DQN算法过程如下,在train DRL的过程中,对最后一层用SRL重新训练。训练的思想SRL-Algorithm也非常简单,将DRL最后一层的参数视为SRL算法的贝叶斯先验,使用下述方程更新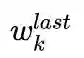


代码详见:github,可惜是lua写的。。
这篇文章让我想起一个问题,什么是“好的研究”?
我曾陷入一个误区,为了发论文而做论文,找问题,对问题理解的并不深,修改fancy的模型。自己也因为这样的工作方式,丧失了科研的动力。出发点不对了,做什么都是错的。
什么是好的研究--是关于科研品味的问题。所做的课题,要么有趣,要么有效,这样才是好的研究吧,诸如kim的CNN和本篇论文,并没有开拓式的创新,有效就行。并不是手机的发明人才伟大,手机的设计者、推广者也是同样伟大。只可惜自己到了博士末年才想清楚这些问题。
本文转载自公众号:机器学习小知识,作者 杨洋
推荐阅读
Siamese network 孪生神经网络--一个简单神奇的结构
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。



