深度学习文本分类实战报告:CNN, RNN & HAN

本文为 AI 研习社编译的技术博客,原标题 :
Report on Text Classification using CNN, RNN & HAN
翻译 | 小猪咪、莫尔•约瑟夫、M.Y. Li 校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/jatana/report-on-text-classification-using-cnn-rnn-han-f0e887214d5f
注:本文的相关链接请点击文末【阅读原文】进行访问
简介
大家好!! 我最近作为 NLP 研究员(Intern😇 ) 加入了 Jatana.ai a并被要求利用深度学习的模型在文本分类方面做一些工作。
在这篇文章中,我将分享我在不同的神经网络架构上做实验时的一些经验和学习心得。
我将覆盖下面这三种主要算法:
卷积神经网络(CNN)
循环神经网络(RNN)
分层注意网络(HAN)
这次的文本分类任务将在丹麦语、意大利语、德语、英语和土耳其语的数据集上做测试。好啦,那我们开始吧!✅
关于自然语言处理(NLP)
自然语言处理和有监督机器学习(ML)在不同的商业问题中被使用到最频繁的任务之一就是“文本分类”,自从第一个含有文本和其标签的标注数据集被用于分类器的训练之后,这就成为了有监督机器学习领域的一个任务模板。
文本分类的目标是:自动将文本文件划分成预定义好的一种或多种不同的类别。
一些文本分类的案例如下:
理解社会媒体中用户的情感 (😁 😐 😥)
检测垃圾邮件
用户问询的自动标签
把新文章📰分类成预定义好的话题
文本分类无论在学术界 📚 还是工业界都是一个活跃的研究领域,在这篇文章中,我将试着展示并对比一些研究成果的表现,所有的实现是基于 Keras 框架的。
所有源代码和实验结果都可以在jatana_research的知识库中找到。
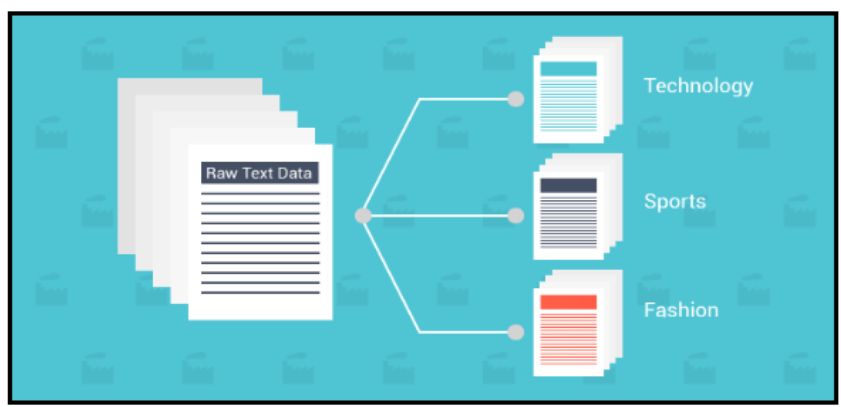
一个端到端的文本分类架构由以下几个部分组成
训练文本:即输入文本,监督学习模型可以通过它来学习和预测所需的类。
特征向量:特征向量是包含描述输入数据特征信息的向量。
标签:我们模型将要预测的预定义的类别/类。
算法:它是我们的模型能够处理文本分类的算法(在我们的例子中:CNN,RNN,HAN)
预测模型:在历史数据集上训练的模型,可以实现标签的预测。
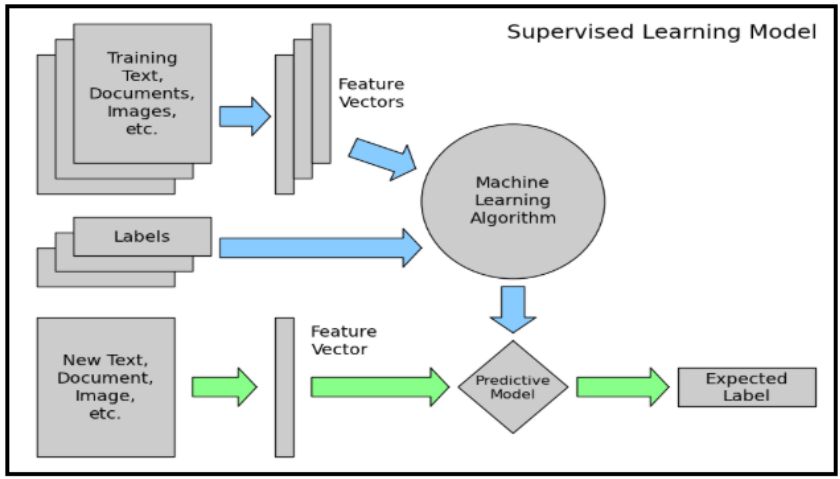
数据分析
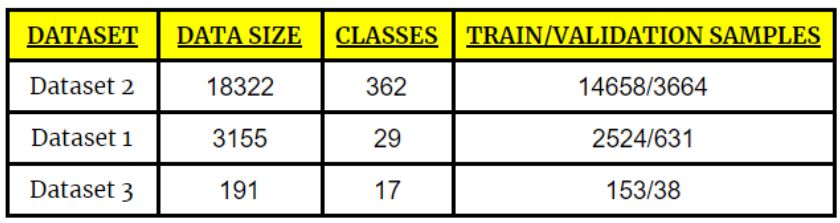
我们使用3种类型的数据集,其中包含多种类别,如下表所示:
基于卷积神经网络的文本分类(CNN)
CNN是一类深度前馈人工神经网络(节点之间的连接不构成循环)并使用多层感知器的变体,其设计需要极少的预处理。 这些都受到动物视觉皮层的启发。
我参考了Yoon Kim论文和Denny Britz撰写的这篇博客。
CNN通常用于计算机视觉,但是最近它们已经应用于各种NLP任务,并且结果很有希望。
让我们通过一个图表简要地看一下将CNN应用与文本数据会发生什么。当一个特殊的模式被检测时,每个卷积的结果都将触发。通过改变核的大小并连接它们的输出,可以检测多个大小(2、3或5个相邻的单词)的模式。模式可以是表达式(单词n元组)像“ I hate ”,“ very good”,因此CNNs可以在句子中识别他们,而不管他们的位置。
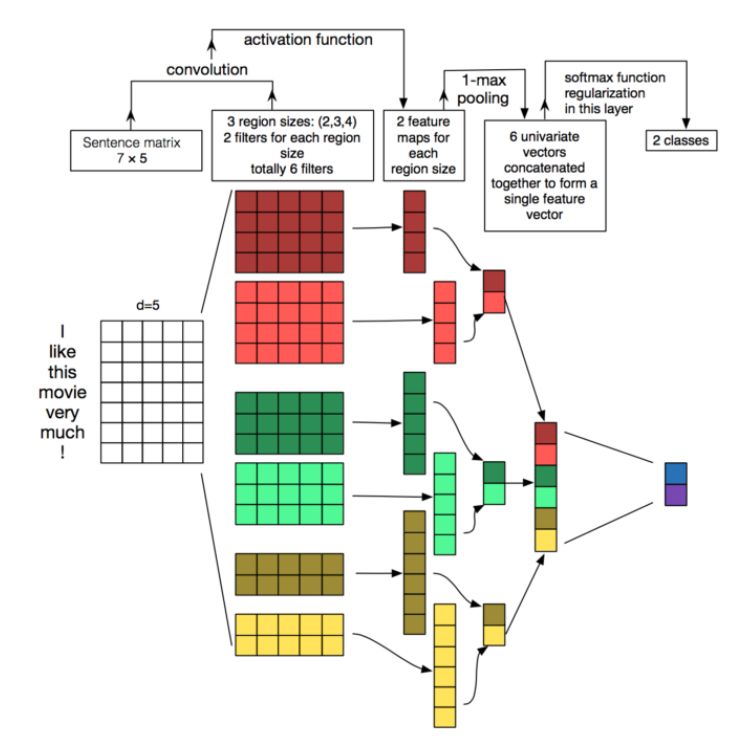
图片参考:http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
在本节中,我使用了一个简化的CNN来构建分类器。首先,使用Beautiful Soup来删除一些HTML标签和一些不需要的字符。
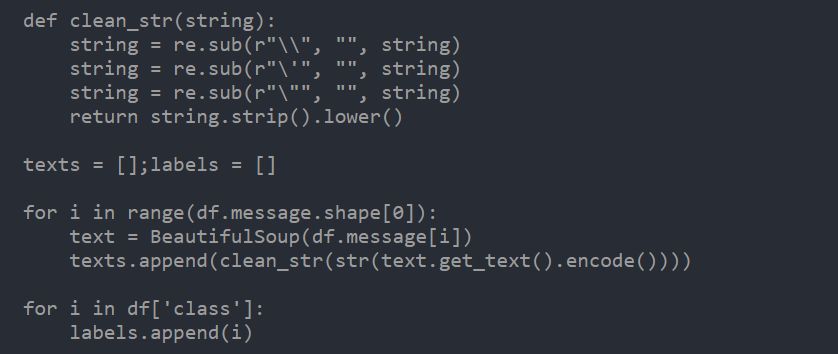
在此,我使用了Google Glove预训练的100维词向量 Google Glove 6B vector 100d。它的官方文档如下:
'' GloVe 是一种用于获取单词向量表示的无监督学习算法。它对来自语料库的聚合的全局词-词共现统计量进行训练,并且其结果展现了单词向量空间非常有趣的线性子结构。''
对于未知的单词,下面的代码会随机初始化它的向量。下面是一个非常简单的卷积结构,总共使用了128个大小为5的卷积核,窗口大小为5与35的最大池化,遵循该博客中的示例。
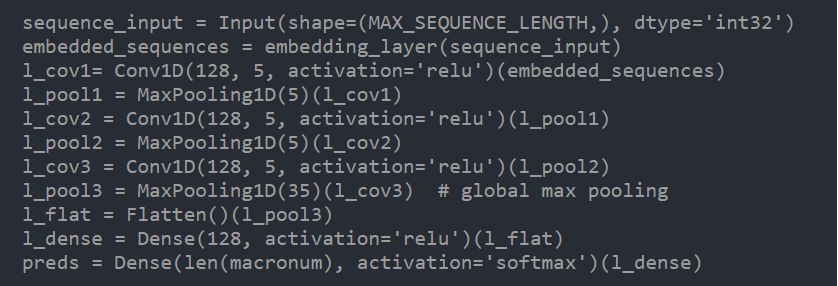
这是CNN模型的结构。
使用递归神经网络(RNN)进行文本分类
递归神经网络(RNN)是一种节点定向连接成有向图的人工神经网络,这种特性允许它展示一段时间序列内的动态时序行为。
使用来自外部嵌入的知识可以提高RNN的精度,因为它整合了这个单词的相关新信息(词汇和语义),而这些信息是基于大规模数据语料库训练和提炼出来的。我们使用的预训练嵌入是GloVe。
RNN可能看起来很可怕。虽然它们很难理解,但是却非常有趣。他们封装了一个非常漂亮的设计,克服了传统神经网络在处理序列数据时出现的缺点:文本,时序,视频,DNA序列等。
RNN是一系列的神经网络节点,它们像链条一样彼此连接。每个节点都将信息传递给下一节点。如果你想深入了解其内部机制,我强烈推荐Colah的博客。
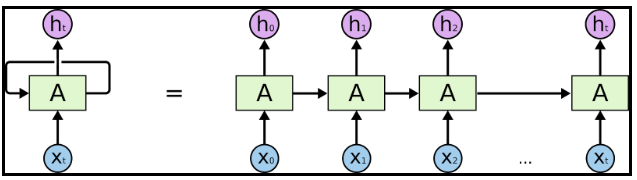
图片参考自:考自:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
使用Beautiful Soup也可以在这里进行相同的预处理。我们将处理一种序列类型的文本数据。单词的顺序对于语义的理解非常重要,RNNs有希望能够处理这个问题并解决长期依赖问题。
要在文本数据上使用Keras,我们首先要对其进行预处理,为此,我们可以使用Keras的Tokenizer类。此对象将num_words作为基于字频率进行标记化后保留的最大字数的参数。
MAX_NB_WORDS = 20000
tokenizer = Tokenizer (num_words=MAX_NB_WORDS) tokenizer.fit_on_texts(texts)
一旦将标记器放置于数据上时,我们就可以使用它将文本字符串转换为数字序列。这些数字代表字典中每个单词的位置(将其视为映射)。
在本节中,我将尝试通过使用递归神经网络和基于注意力机制的LSTM编码器来解决该问题。
通过使用LSTM编码器,我们打算在运行前馈网络进行分类前,对递归神经网络的最后一个输出文本的全部信息进行编码。
这与神经翻译机和序列到序列的学习模型非常类似。以下是段落和文档的分层神经自动编码器的图。
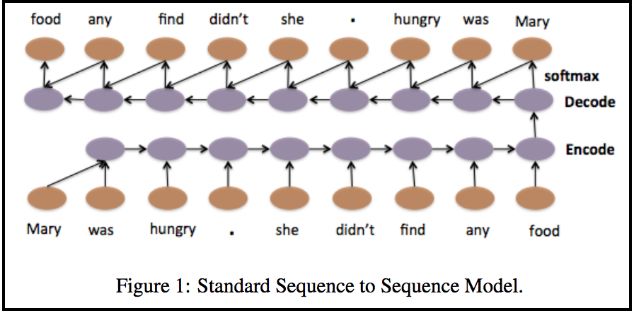
图片参考自:https://arxiv.org/pdf/1506.01057v2.pdf
我在Keras中使用LSTM层来实现这一点。不同于正向LSTM,在这里我使用了双向LSTM,并且连接了其各自的最后一层输出。
Keras提供了一个非常好的双向包装器,这将使这种编码工作毫不费力。您可以在此处查看示例代码。
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
l_lstm = Bidirectional(LSTM(100))(embedded_sequences)
preds = Dense(len(macronum), activation='softmax')(l_lstm)
model = Model(sequence_input, preds)
model.compile(loss='categorical_crossentropy',optimizer='rmsprop', metrics=['acc'])
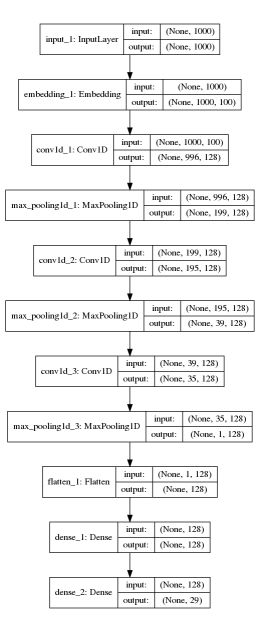
以下是RNN模型的结构
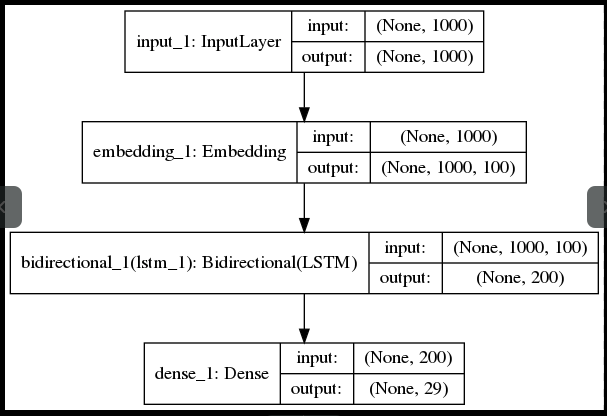
使用分层注意网络(HAN)的文本分类
我参考了《用于文档分类的分层注意网络》这篇研究论文,它可以成为使用HAN进行文档分类的一个不错的指南。使用Beautiful Soup也可以进行相同的预处理,在这里我们使用的预训练嵌入是GloVe。
这里我正在构建一个分层LSTM网络。我必须按上面两节所述构建输入数据为3D格式而非2D。
因此输入张量将是[每批数据的评论数,句子数,每句中的单词数]。
tokenizer = Tokenizer(nb_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(texts)
data = np.zeros((len(texts), MAX_SENTS, MAX_SENT_LENGTH), dtype='int32')
for i, sentences in enumerate(reviews):
for j, sent in enumerate(sentences):
if j< MAX_SENTS:
wordTokens = text_to_word_sequence(sent)
k=0
for _, word in enumerate(wordTokens):
if(k<MAX_SENT_LENGTH and tokenizer.word_index[word]<MAX_NB_WORDS):
data[i,j,k] = tokenizer.word_index[word]
k=k+1
在此之后,我们可以使用Keras魔术函数TimeDistributed构建如下分层LSTM网络输入层。我们也可以参考这篇文章。
embedding_layer=Embedding(len(word_index)+1,EMBEDDING_DIM,weights=[embedding_matrix],
input_length=MAX_SENT_LENGTH,trainable=True)
sentence_input = Input(shape=(MAX_SENT_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sentence_input)
l_lstm = Bidirectional(LSTM(100))(embedded_sequences)
sentEncoder = Model(sentence_input, l_lstm)
review_input = Input(shape=(MAX_SENTS,MAX_SENT_LENGTH), dtype='int32')
review_encoder = TimeDistributed(sentEncoder)(review_input)
l_lstm_sent = Bidirectional(LSTM(100))(review_encoder)
preds = Dense(len(macronum), activation='softmax')(l_lstm_sent)
model = Model(review_input, preds)
如下是HAN模型的架构。
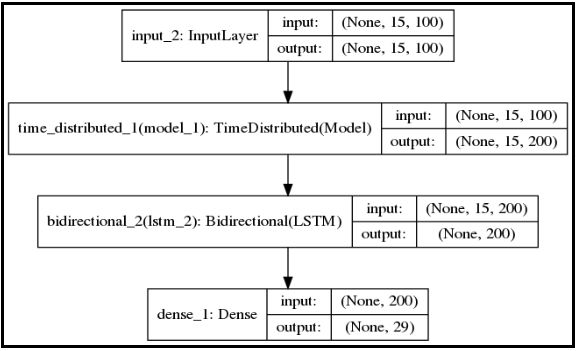
结果
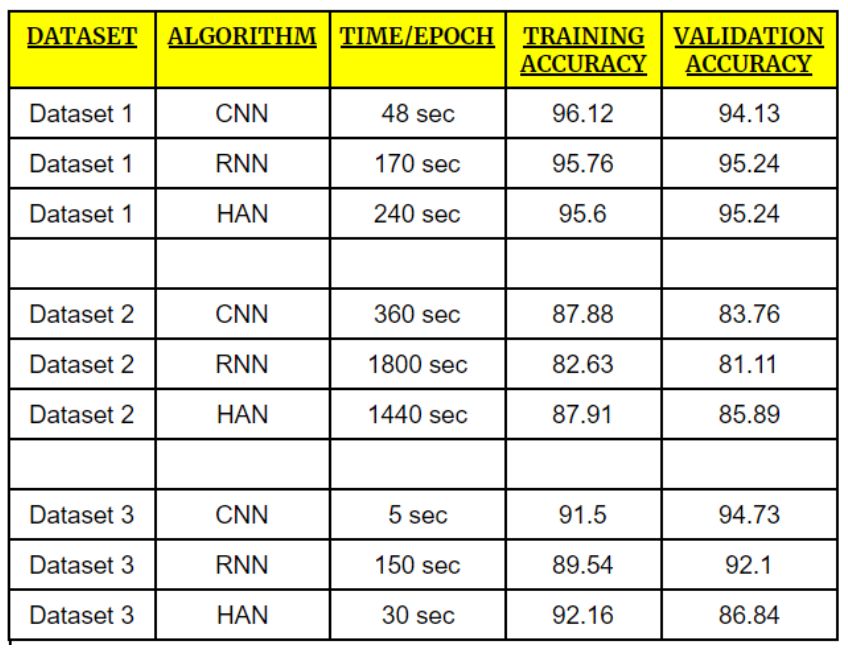
📈为准确率, 📉为损失
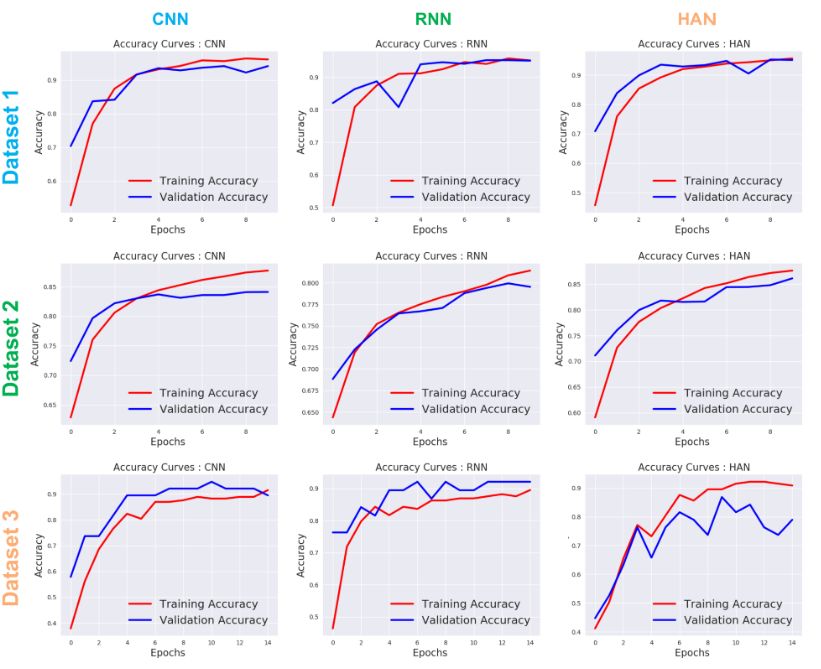
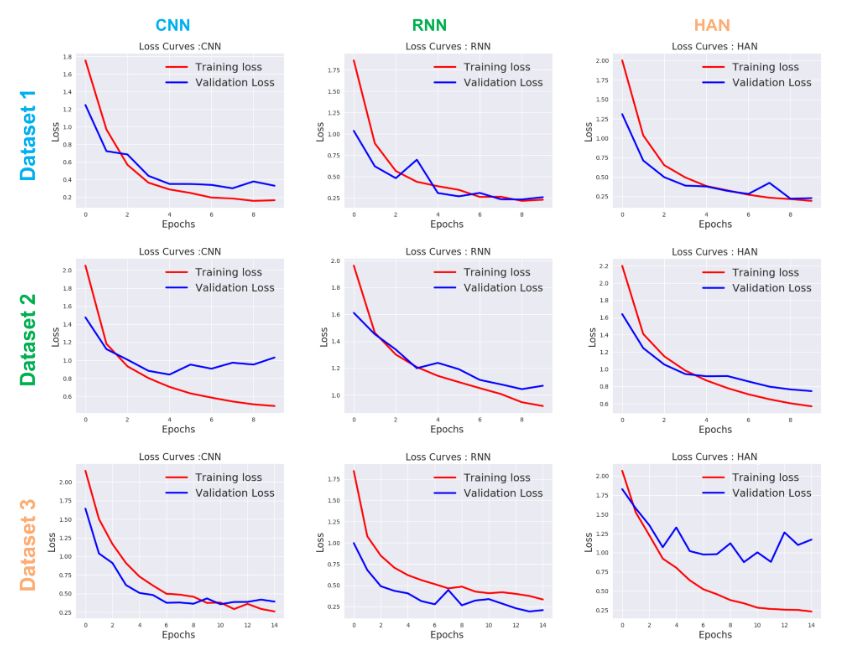
观察发现
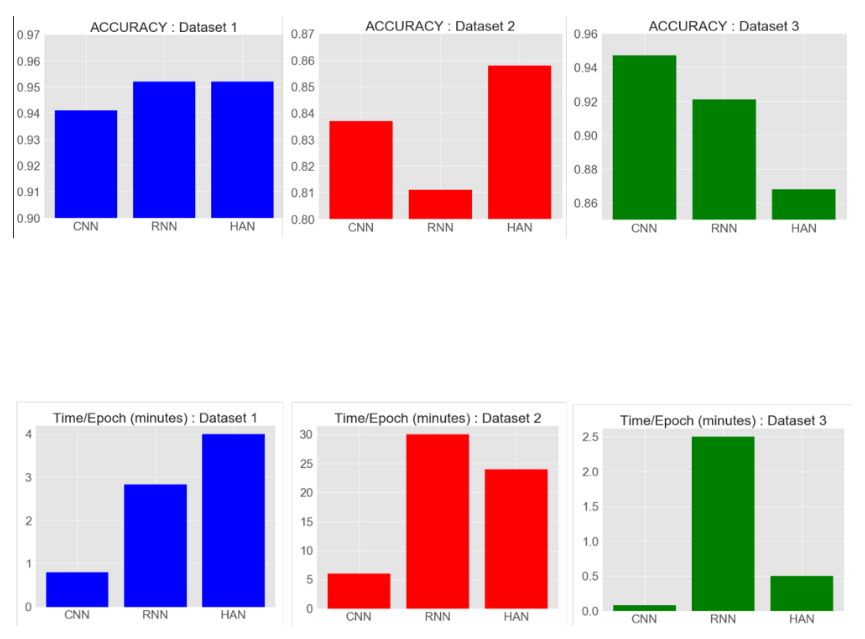
基于上述图表,CNN取得了良好的验证准确率以及高度的一致性,RNN和HAN也实现了高准确性,但在所有数据集中它们并不具有一致性。
发现RNN对于生产就绪场景的实现是最差的一种结构。
CNN模型在训练时间方面优于其他两个模型(RNN和HAN),但是如果我们拥有较大的数据集,HAN比CNN和RNN表现更好。
对于拥有很多训练样本的数据集1和数据集2,HAN达到了最佳验证准确度,而当训练样本非常小时,HAN没有表现出那么好(数据集3)
当训练样本较少时(数据集3),CNN达到最佳验证准确度。
性能改进
为了达到最好的性能😉,我们可以:
微调超参数: 超参数是在训练前设置的变量,它决定了网络的结构以及如何训练网络。(例如:学习率,批量大小,迭代数)。实现微调可以通过:手动搜索,网格搜索,随机搜索…
提高文本预处理: 可以根据数据集的需要,更好地对输入数据进行预处理 ,例如删除一些特殊符号,数字,停用词等...
使用Dropout层:Dropout是一种正则化方法,可以避免过拟合(提高验证精度),从而增加泛化能力。
基础配置
以上实验均在Nvidia Tesla K80 GPU的8核 vCPU上进行。
此外,所有实验均在Rahul Kumar 的指导下进行 😎 。
同时,我还要感谢Jatana.ai为我提供了一个非常好的基础设施和全程支持
想要继续查看该篇文章相关链接和参考文献?
戳链接或点击底部【阅读原文】:
http://ai.yanxishe.com/page/TextTranslation/1127
AI研习社每日更新精彩内容,观看更多精彩内容:
使用 SKIL 和 YOLO 构建产品级目标检测系统
AI课程/书籍/视频讲座/论文精选大列表
自定义损失函数Gradient Boosting
为什么现在人工智能掀起热潮?
等你来译:
深度网络揭秘之深度网络背后的数学
华人团队赢得微软COCO挑战赛,凭借的是实力还是?
智能手机哪家强?实时姿态检测大比拼!
用Excel来阐释什么是多层卷积
号外号外~
想要获取更多AI领域相关学习资源,可以访问AI研习社资源板块下载,
所有资源目前一律限时免费,欢迎大家前往社区资源中心
(http://www.gair.link/page/resources)下载喔~




