PRN:面向不规则文字识别的渐进矫正网络
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达


本文简要介绍SCIENCE CHINA Information Sciences 2020特刊Special Focus on Deep Learning for Computer Vision的论文“Progressive rectification network for irregular text recognition”的主要工作。该论文提出了一种渐进矫正的方式和包络改良的结构,主要解决了自然场景图像中不规则文字的识别问题。
由于场景的多样性和拍摄视角的多变性,对于不规则文字(倾斜文字、弯曲文字、透视文字等)识别的需求日益增加。由于文字布局不可预测的变化,识别任意形状的文字是一个极具挑战性的任务。大部分现存的方法主要集中在规则文字识别上,鲁棒性不足,很难泛化到不规则文字识别的任务上。有一些工作采用基于矫正的思路,首先将不规则文字矫正到一个易于识别的前向水平视角,然后再进行识别。空间变换网络Spatial Transformer Network (STN) 是一个可以进行空间变换的可学习的模块。然而,用STN处理复杂的变形,尤其是非刚体的变形是非常困难的,通过一次简单的矫正很难达到理想的效果。单步矫正通常不能完全移除变形,不理想的矫正也可能会导致文字信息丢失,因而造成对后续识别的负面影响。在现实世界人类的认知过程中,困难的任务通常会被划分为多个简单的步骤,中间阶段性的结果可以被用来指导下一步操作过程。而且,人类通常采用多次不断地改良来更好的完成一个复杂任务。基于以上分析,我们设计了一个循环矫正网络来逐步地将不规则文字矫正到易于识别的前向水平视角,从而达到最优的识别效果。
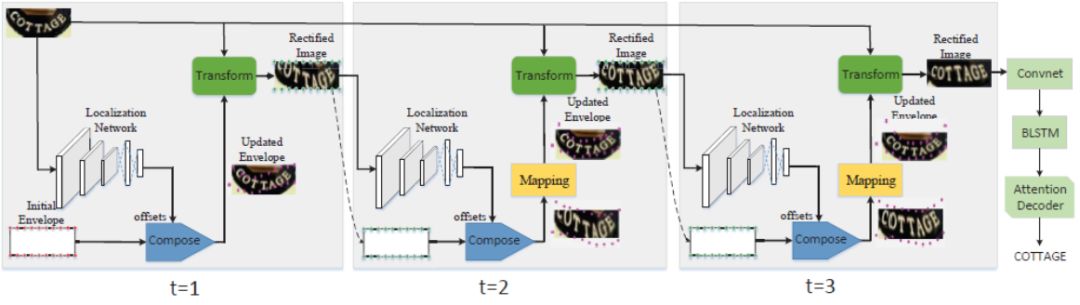
图1展示了我们提出的渐进矫正网络的整体框架图。不规则文字首先被渐进式地校准到正向水平视角,然后送入后续的识别网络。在矫正过程中,通过多次迭代对矫正结果进行优化,变形会被逐步地移除。我们用同一个矫正网络循环地更新矫正结果,因此不会引入任何额外的参数。具体地,将变换参数估计模块记做E,空间变换模块记做S,我们的循环结构如下所示:
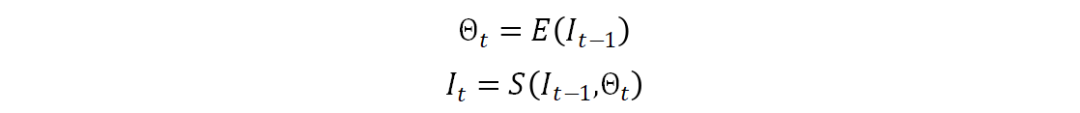
其中,t代表第t次迭代,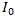
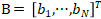
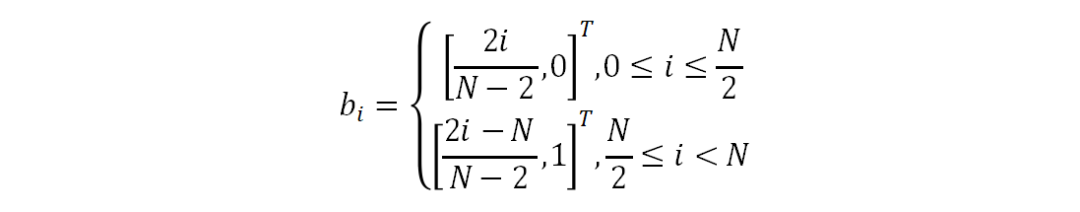
其中,N代表边界点的个数。在网络前传的过程中,定位网络预测一个输入图像上的文字包络
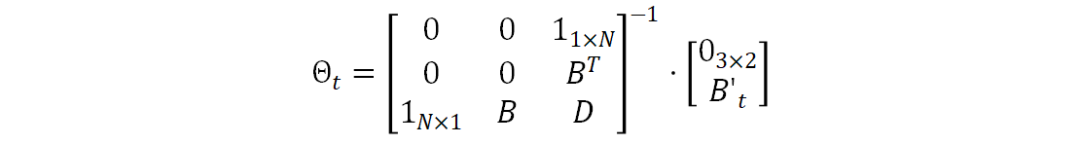
其中,D是一个的N×N方阵,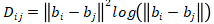
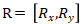
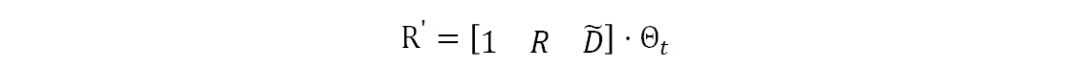
其中,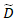
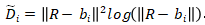
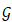

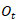 ,原始图像和矫正图像上的包络记为
,原始图像和矫正图像上的包络记为
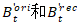 ,然后按照如下的方式对包络进行更新:
,然后按照如下的方式对包络进行更新:
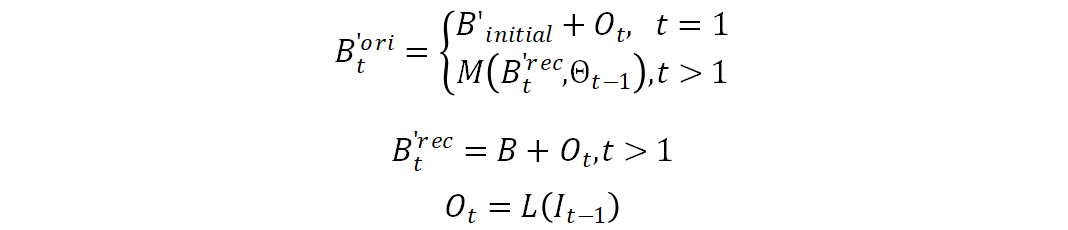 其中,
其中,
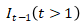 是上一步输出的矫正图像,是原始输入图像,
L
是定位网络,
是上一步输出的矫正图像,是原始输入图像,
L
是定位网络,
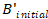 是预定义的初始包络,映射操作
M
和上文中的线性映射定义相同。当更新后的包络落到矫正图像外面的时候,映射回原图意味着补充一些损失的信息。基于原图上更新后的包络,可以计算出变换参数,然后在原始图像上进行采样。因此,循环结构中的第二个公式可以重写为以下的形式:
是预定义的初始包络,映射操作
M
和上文中的线性映射定义相同。当更新后的包络落到矫正图像外面的时候,映射回原图意味着补充一些损失的信息。基于原图上更新后的包络,可以计算出变换参数,然后在原始图像上进行采样。因此,循环结构中的第二个公式可以重写为以下的形式:
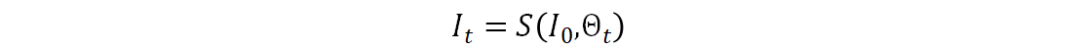
 ,然后解码器循环地生成字符序列
,然后解码器循环地生成字符序列
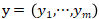 。第
i
步,解码器会自适应地对图像特征进行加权选择:
。第
i
步,解码器会自适应地对图像特征进行加权选择:
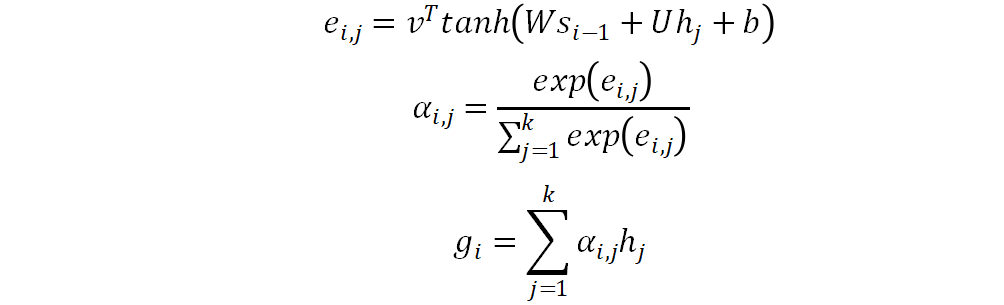
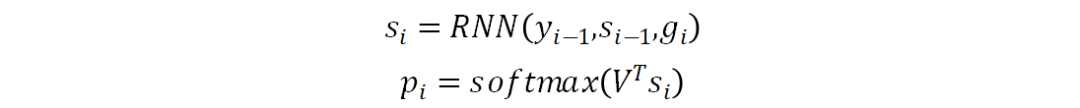
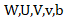 都是可学习的参数。
此外,这里我们采用双向解码器。
给定输入图像I和真实标签
都是可学习的参数。
此外,这里我们采用双向解码器。
给定输入图像I和真实标签
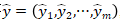 ,
目标函数的形式如下:
,
目标函数的形式如下:
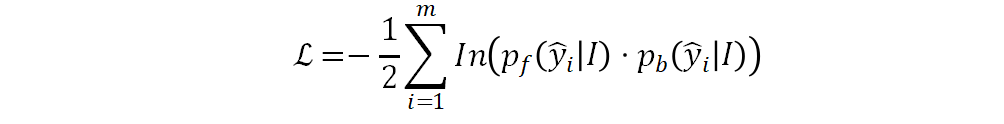
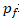 和
和
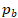 分别是前向解码器和反向解码器输出的概率分布。
矫正网络和识别网络是端到端的进行训练的,不需要任何额外的标注。
分别是前向解码器和反向解码器输出的概率分布。
矫正网络和识别网络是端到端的进行训练的,不需要任何额外的标注。
针对上述设计,我们分别在四个不规则文字的数据库SVT-P、CUTE80、ICDAR15、Total-Text和四个规则文字的数据库SVT、IIIT5k、ICDAR03、ICDAR13上进行了验证。
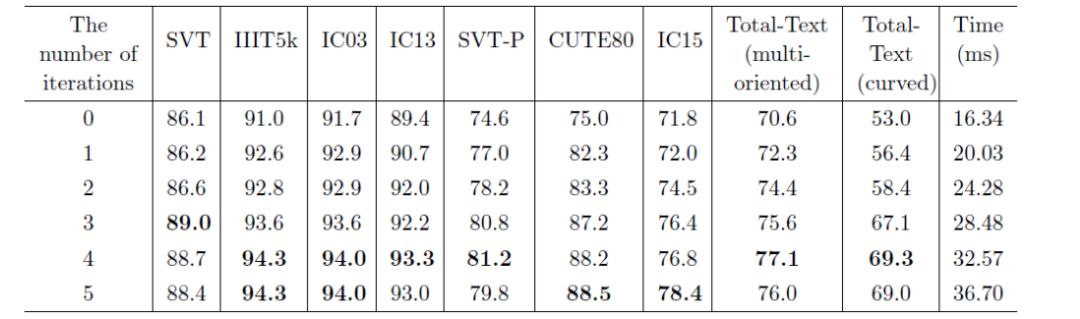


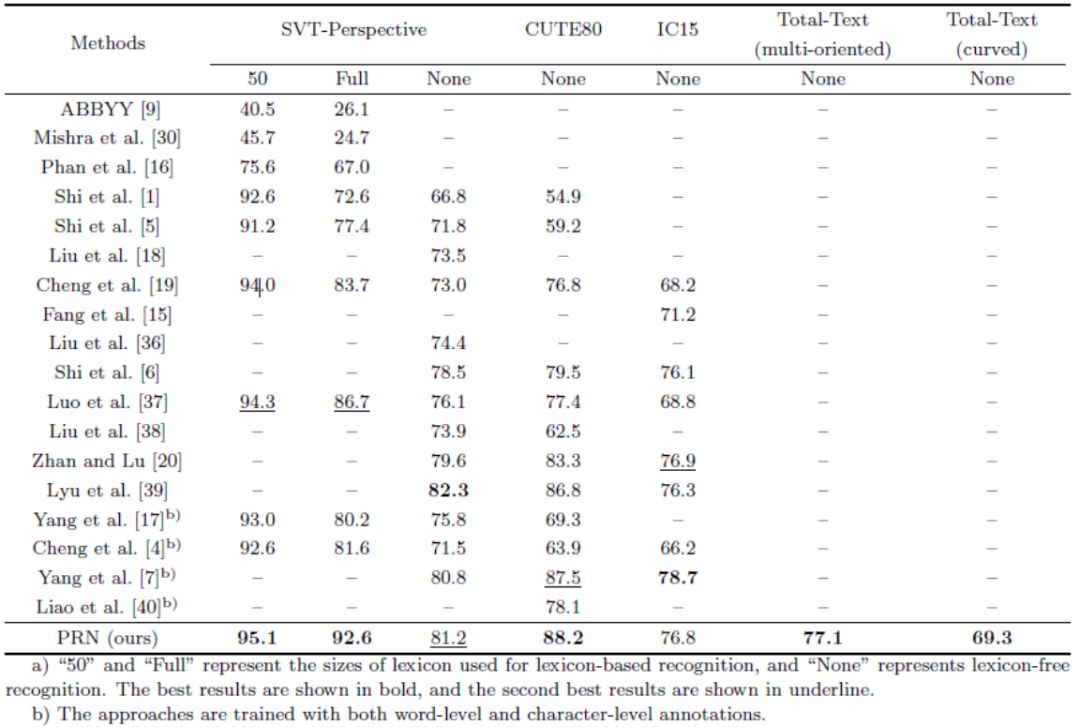
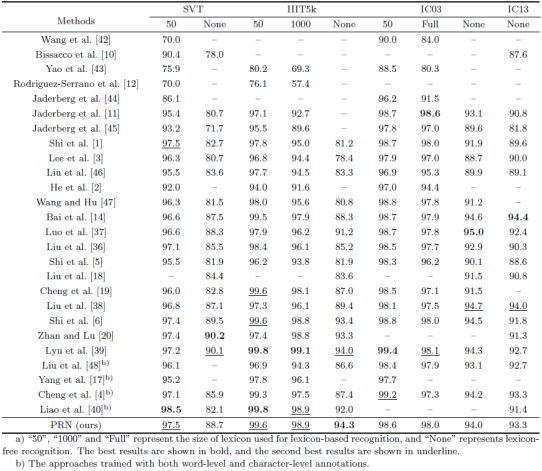
本文提出了一种渐进矫正网络,用于解决不规则文字的识别问题。该方法在不规则文字的数据集上表现出了优越的效果。与之前基于矫正的方法相比,该方法对于文字形变更加鲁棒,可以有效移除形变程度较大的文字形变,进一步改善识别性能。
原文作者:Yunze Gao, Yingying Chen, Jinqiao Wang,Hanqing Lu
撰稿:高云泽 编排:高 学
重磅!CVer-场景文本识别交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如场景文本识别+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




