全卷积注意网络的细粒度识别
很开心,自平台创办以来,还有这么多兴趣爱好者关注与支持,参与我们学习群的讨论,很感谢您们一路的鼓励与支持。不管怎么样,这个平台会一直为大家无私奉献,分享最值得一看的内容,让您阅读的几分钟内受益匪浅!
今天跟大家来说说全卷积网络,主要涉及的领域是细粒度识别!
细粒度的识别(Fine-grained Recognition)的挑战性主要来自于类内差异(Inter-class Differences)在细粒度类别中通常是局部的、细微的;类间差异(Intra-class Differences)由于姿态的变换而导致很大。
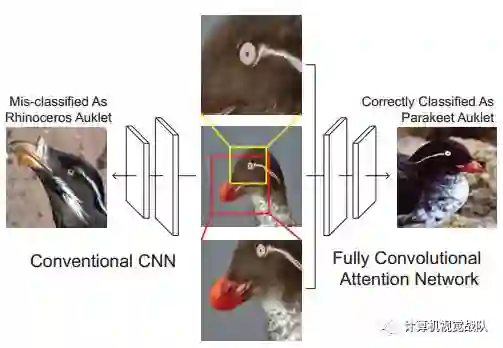
为了从类间变化区分他们,放大到具有高度判别性的局部区域是非常重要的。于是作者提出了一种基于强化学习的全卷积注意力局部网络来自适应的选择多任务驱动的视觉注意力区域 。(In this work, we introduce a reinforcement learning-based fully convolutional attention localization network to adaptively select multiple task-driven visual attention regions.)
作者的实验表明将相关区域放大处理,可以得到更好的结果,这一点就相当于我们人类看东西的时候,当全局看的不是很仔细的时候,就需要放大镜来看,从局部得到所需要的信息,从而做出进一步的判断。本文在三个数据集上做了实验,分别是:斯坦福dog, cars, CUB-200-2011。
前人的工作大多是使用手工设计的 part 来进行 Fine-grained Recognition,依赖于手工定义的part有几个缺点:
精确的part 标注需要非常昂贵的代价;
强监督的基于part的模型可能在part被遮挡时,失效;
最后但也是最重要的,即:没有线索表明,手工设计的part对于所有的 Fine-grained Recognition tasks来说是最优的。例如:对于食物的识别来别,是非常难以设计part的。
针对以上问题,提出了一种框架,即:Fully Convolutional Attention Localization Network来定位物体的part,而没有任何人工的标注。利用基于强化学习的视觉 Attenation Model 来模拟学习定位物体的part,并且在场景内进行物体分类。
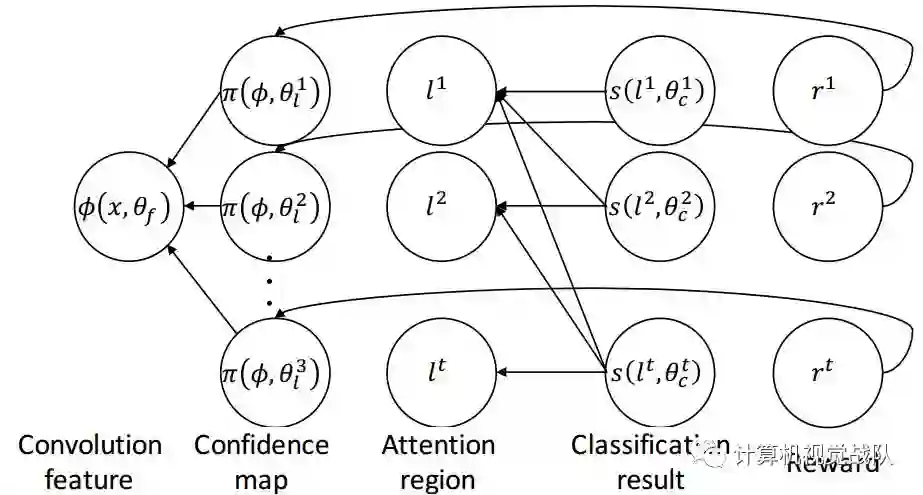
这个框架模拟人类视觉系统的识别过程,通过学习一个任务驱动的策略,经过一系列的 glimpse 来定位物体的part。每一个 glimpse 对应一个物体的part。将原始的图像以及之前glimpse 的位置作为输入,下一次 glimpse位置作为输出,作为下一次物体part。每一个 glimpse的位置作为一个 action,图像和之前glimpse的位置作为 state,奖励衡量分类的准确性。
本文方法可以同时定位多个part,之前的方法只能一次定位一个part,但是仔细想想,也奇怪,既然是 attenation model,那么像人类一样,一次只能将目光注意到一个地方,只定位一个part也是正常且合理的,但这里多个part同时定位,有点不太合理(嘿嘿)。
Fully Convolutional Attention Localization Networks
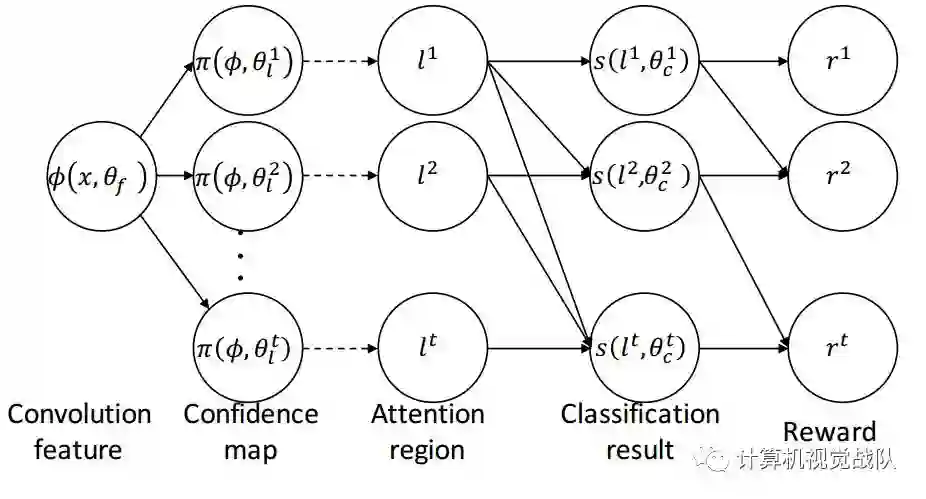
该网络结构可借助Attention Mechanism同时定位多个物体part。不同part可以拥有不同的预先定义的尺寸,主要包含两个成分:
Part localization component and classification component。
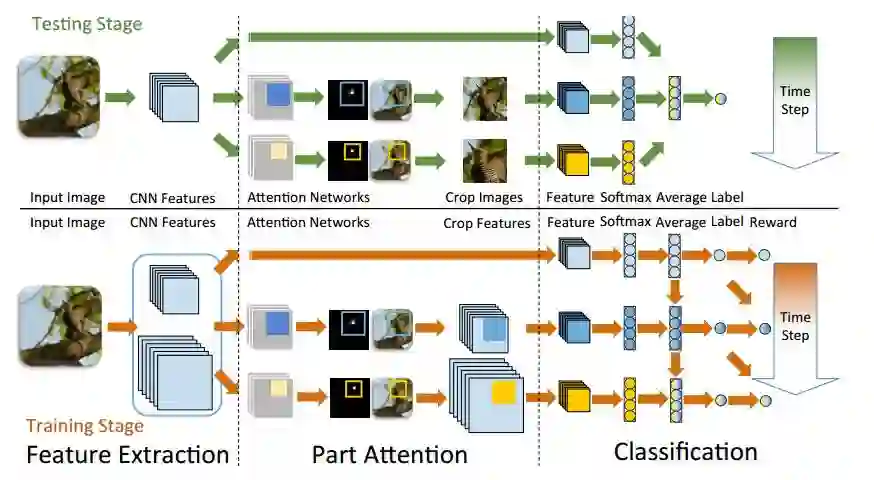
定位part的成分利用一个全卷积的神经网络来定位part的位置。给定一张输入图像,我们用VGG-16以及在ImageNet上训练好的model提取基础的卷积特征映射。
Attention localization network 定位多个parts,利用基础的卷积特征映射对每一个part都产生一个score map。每一个score map都是由两层累积的卷积层和一个spatial softmax layer构成。第一个卷积层利用64个3*3的kernel,第二层利用一个3*3的kernel来产生一个单通道的置信图。spatial softmax layer作用于confidence map,用来将置信得分转化为概率。拥有最高概率的Attention region被选为part location。
分类的部分(classification component) 对于每一个part 以及 全图都给定一个CNN分类器。不同的part 可能有不同的尺寸,局部的图像区域根据其大小以及part的位置进行crop操作。我们对每一个局部图像区域和整体图像分开来进行图像分类器的训练。最终分类的效果是所有单独分类器结果的平均。
为了判别出具有细微视觉不同的地方,每一个局部图像区域被resize成高分辨率的。每一个part都单独的训练一个CNN网络。
虽然resize局部图像区域可以达到很好的分类性能,但是其需要我们执行多步前向和后向传播,这是非常耗时的。
所以,此处采用了估计part 分类的方法,类似于 fast-rcnn,训练过程中的卷积特征映射对于part的定位,part的分类,以及整张图像的分类都是共享的。在整幅图像的卷及特征映射上选择对应的区域,从而得到每一个part的卷积特征,所以 所选中区域的接受域是和part部分相同的。所有时间步骤的卷积特征也是共享的。所以,我们只要在一个训练batch中,执行前向传递即可。
Note:这些分类网络仅仅用来在attention localization network training的时候得到奖励。最后的分类网络是基于resized 高分辨率图像。
Inference
接下来说说如何利用 attention localization network 在inference的过程中进行识别。像上图所示,给定一张图,我们首先定位多个 Attention regions,通过选择每一个part 拥有最高概率的区域。
然后放大每一个part的位置,通过resize围绕它的分辨率到对应的高分辨率。每一个resize的part region 以及原本的图像利用分类part单独的进行预测。最后的预测score是原本图像的平均和所有Attention region的平均。
Training Attention Localization Networks
由于并没有groundtruth来辅助进行定位Attention region,我们采用RL的方法来学习Attention localization networks。
整个attention定位问题被描述成 马尔科夫决策过程(Markov Decision Process, MDPs)。在MDP的每一步中,Attenation localization network作为agent 来基于观察,执行一个action,并且得到一个reward。
在工作中:
action ---> the location of the attention region;
observation ---> the input image and the crops of the attention regions;
the reward ---> measures the quality of the classification using the attention region.
学习目标自然就是:学习一个最优的决策来根据观测产生动作,具体表现为 通过Attention localization network的参数来最大化所有时间步骤的期望奖励的总和。
作者额外又训练了一个分类网络来衡量分类的质量。每一步的分类网络是一个全卷积网络紧跟着一个softmax layer,将最后一个timestep的所有part的Attention maps 以及 整幅图像的卷积特征作为输入。
分类网络和Attention localization network 联合优化来最大化接下来的目标函数:
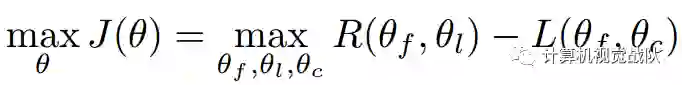
其中,θL,θC是Attention localization network和classification network的参数。注意到,我们应用L(θC)是交叉熵分类损失,R(θL)的定义是:
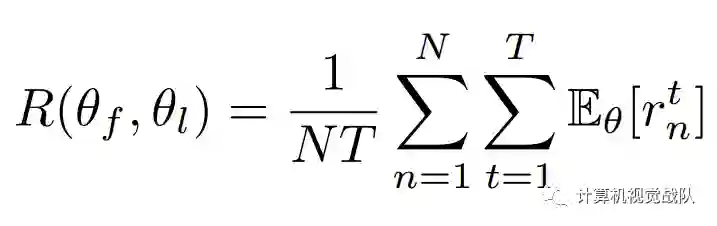
其是N个训练样本的平均期望奖励和T个不同的选择区域,L(θC)的定义如下:
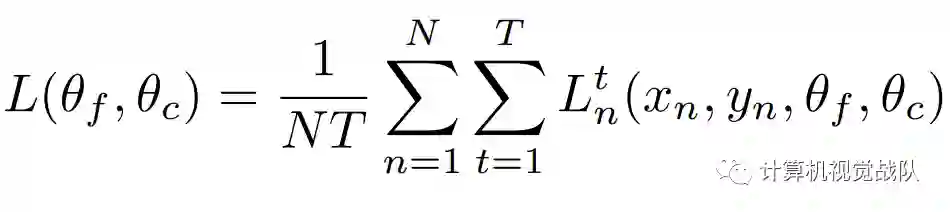
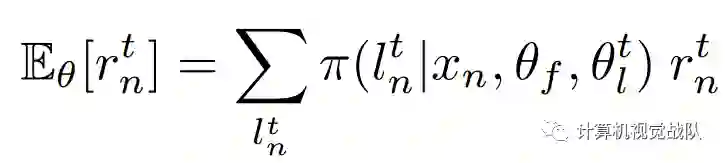
是第n个样本的第t个选择的Attention region的期望奖励。
1. Reward Strategy
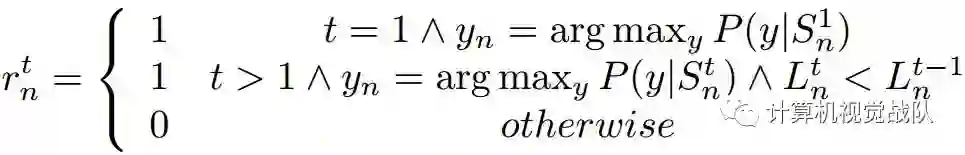
像上面公式表达的那样,有两种情况可以给出奖励:
1. 第一次迭代(t=1),并且预测的结果和gt值相等,则马上给出奖励,即:Cn,1 = yn ;
2. 第t次迭代,当预测的结果和gt值相等,然后当前迭代的loss值小于前一次迭代的loss,那么也给出奖励;否则,就不出给奖励。
其实,还有一种直观的关于reward奖赏的方法,即:从整体上,利用最终的分类结果来衡量Attention region 选择策略的质量, i.e. r(An, t) = 1 如果t = T,并且当前图像被正确的分类;否则就是0.文中提到这可能会导致难以收敛的问题。
所以,作者认为当图像可以利用当前attention region 被正确分类时,就立刻给出奖励,训练时就立刻更加简单和快速的收敛。
2. Optimization
FP
BP
直接计算 期望的梯度有点困难,本文采用的是蒙特卡洛方法来近似计算:
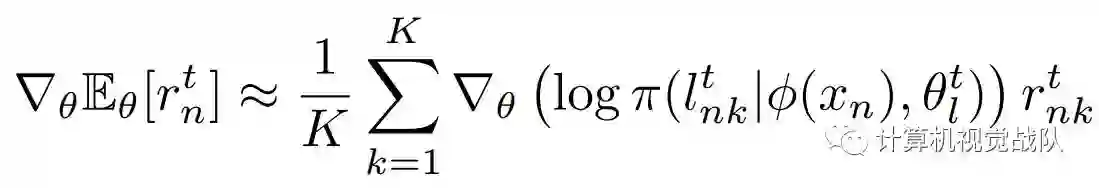
Attention区域的可视化:



微信ID:ComputerVisionGzq

长按左侧二维码关注
登录查看更多
相关内容

Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。
专知会员服务
78+阅读 · 2020年2月25日
专知会员服务
20+阅读 · 2020年1月26日
专知会员服务
102+阅读 · 2019年11月24日
Arxiv
8+阅读 · 2018年6月28日



相关VIP内容
专知会员服务
78+阅读 · 2020年2月25日
专知会员服务
20+阅读 · 2020年1月26日
专知会员服务
102+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
8+阅读 · 2018年6月28日